(JavaScript - 原生)正则表达式在JavaScript中的应用
(JavaScript - 原生)正则表达式在JavaScript中的应用
## 绪论
今天来研究的是正则表达式,其实正则表达式不是JavaScript独有的,Java与C#等其它语言也支持正则表达式,因为正则这个概念是独立于语言之外的,它是通过定义指定的模式去匹配符合该模式的字符(概念),只不过在各个语言中表现出来的可能不太相同,但核心都是一样的!
## 表述
还是那句老话,不管是久经沙场的老鸟还是从入门到放弃的菜鸟,正则表达式都是我们前端人员手中的利器...本章会尽量细讲真正做到深入浅出!
## 正题
## 在这我们还是通过三个维度来研究正则:
1.正则是什么?
2.为什么使用?
3.怎么使用?
> -1).正则是什么?
通过定义指定的模式去匹配符合该模式的字符,擅长处理复杂的字符串,可以担任数据等校验工作 ...
像这样的火星文就是正则(此为匹配邮箱的正则) => /^[0-9a-z]+@[0-9a-z]+\.(?:com.cn|(?:com|cn))/
>-2).为什么使用?
来,假如有一道题:
题:找出字符串"pingguo123taozi456putao789"中的数字?
在没有接触过正则的时候我们可能这么写:
定义字符串
let str = "pingguo123taozi456putao789";ES5及之前写法:
// ES5方法
var arr_es5 = str.split("");// 将字符串转换为数组
var arr_res = [];// 声明空数组
for(var i = 0;i < arr_es5.length;i++) {// 拿出数字元素
var num = Number(arr_es5[i]);
if((num * 0) === 0) {// 利用NaN的运算特性仅仅拿出数字元素
arr_res[i] = String(num);
}
}
var strr = String(arr_res);// 将其结果转换为字符串
for(var i = 0;i < arr_res.length;i++) {// 替换
strr = strr.replace(",", "");
}
arr_res = strr.split("");// 将字符串转化为数组
console.log(arr_res);// 打印 (9) ["1", "2", "3", "4", "5", "6", "7", "8", "9"]ES6写法:
// ES6方法
let arr_es6 = [...str];
arr_es6 = arr_es6.filter((item, index) => Number.isNaN(Number(item)) ? void 0 : item);
console.log(arr_es6);// 打印 (9) ["1", "2", "3", "4", "5", "6", "7", "8", "9"]正则方式:
//正则方式
let reg = /\d+/g;
let arr = str.match(reg);
console.log(arr);// 打印 (3) ["123", "456", "789"]3种方式的打印结果:

如果![]() 你不想要,你想要
你不想要,你想要![]() 的话
的话
console.log([...arr.toString().replace(/,/g, "")]);// 打印 (9) ["1", "2", "3", "4", "5", "6", "7", "8", "9"]怎么样?
相比较来说ES5及其以前的方法是不是烦死人了?
就连ES6的方法也足足3句代码才完成而且消耗的性能不容小觑!
再看看正则的方式仅仅2句代码就找出目标元素而且代码简洁高效,孰强孰弱一看便知!
>-3).怎么使用?
-
定义正则方式:
-1).字面量方式:
let reg = /^$/;
console.log(reg);// 打印 /^$/
console.log(Object.prototype.toString.call(reg))// 打印 [object RegExp]打印结果:
![]()
-2).构造器方式:
let reg_1 = new RegExp(/^$/ig, "g");
console.log(reg_1);// 打印 /^$/g打印结果:
![]()
咦?为什么会打印![]() 呢?不是应该打印
呢?不是应该打印![]() 的吗?那是因为ES6语法曾明确指出,正则RegExp的构造器的第二参数的正则修饰符会覆盖正则RegExp的构造器的第一参数中的修饰符!
的吗?那是因为ES6语法曾明确指出,正则RegExp的构造器的第二参数的正则修饰符会覆盖正则RegExp的构造器的第一参数中的修饰符!
-
exec方法与test方法
-1).reg.test(str);方法 => (如果匹配到符合模式的元素就返回true,否则返回false)
let reg = /12/;
let str = "123";
console.log(reg.test(str));// 打印 true尽管没人会这样写,因为正则表达式是一个匹配模式不能写死,这里咱们为了示范(还没有学新的)就将就先用着。
打印结果:
![]()
-2).reg.exec(str)方法 => (如果匹配到符合模式的元素就将该元素以数组的形式返回否则返回null)
console.log(reg.exec(str));// 打印 ["12"]打印结果:
![]() 将其展开 =>
将其展开 => 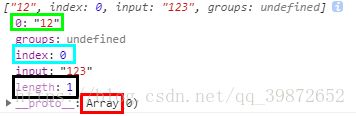
红框代表返回的是一个数组
黑框代表返回的结果数组中只有一个元素
蓝框代表是在"123"的第0个位置开始匹配到的
绿框代表这个唯一的元素是"12"
## 另外这些属性我们也是可以获取到的
cosnole.log(reg.exec(str).index);// 打印 0
cosnole.log(reg.exec(str).length);// 打印 1打印结果
![]()
-
认识元字符(就是特殊意义的字符)
-1). \d 匹配一个数字元素
let reg = /\d/;
let str = "a1";
console.log(reg.exec(str));// 打印 ["1"]打印结果:
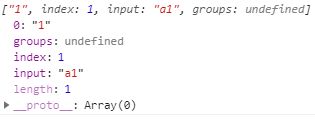
-2). \D 匹配一个非数字元素
reg = /\D/;
console.log(reg.exec(str));// 打印 ["a"]打印结果:
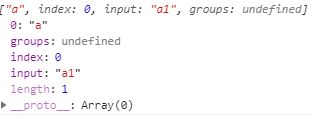
-3).\b 匹配一个单词边界
let str = "bigcatsmallcat";
let reg = /cat\b/;
console.log(reg.exec(str));// 打印 ["cat"]打印结果:
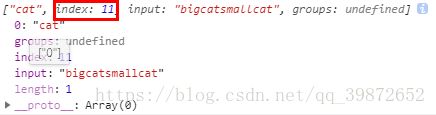
从打印的结果来看是在字符串str的第索引为11的地方开始匹配到的。即最后那块 ...,通俗说就是cat\b会匹配到前面是cat后面是边界的cat,要不在str中中间的那个部分也有个cat怎么没有匹配到呢?
-4). \B匹配一个非单词边界
let reg = /cat\B/;
console.log(reg.exec(str));// 打印 ["cat"]打印结果:

从打印结果来看这次匹配的是中间的即big后面的cat,因为/cat\B/代表匹配一个cat后面不为边界的cat。
-5). \s 匹配一个任何空白字符(包括\r\t\n\b等 ...)
let str = "var apple = '苹果'";
let reg = /\s/;
console.log(reg.exec(str));// 打印 [" "]打印结果

str = "var\napple = '苹果'";
console.log(reg.exec(str));
-6). \S 匹配一个任何非空白字符
reg = /va\B/;
console.log(reg.exec(str));// 打印["va"]打印结果:

此正则的意思是匹配一个va后面不是空白字符的va。
再来看:
str = "va\napple = '苹果'";
reg = /va\B/;
console.log(reg.exec(str));// 打印 null打印结果:
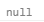
此正则的意思是匹配一个va后面不是空白字符的va,但其后面有\n,\n就是空白字符,所以不符合该模式导致没有匹配成功exec方法就返回null。
-7). \w 匹配一个0~9、a-z、A-Z、_范围内的一个元素
let reg = /\w\d/;
let str= "TomCat2&3";
console.log(reg.exec(str));// 打印 ["t2"] 打印结果:
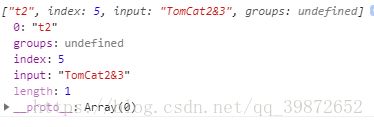
-8). \W匹配一个非0~9、a~z、A~Z、_范围内的元素
reg = /\W\d/;
console.log(reg.exec(str));// 打印 ["&3"]打印结果:

-
认识限定符(对元字符等元素进行个数方式上的限制)
-1). {n} 仅匹配n个
let reg = /\d{2}/;
let str = "123456";
console.log(reg.exec(str));// 打印["12"]在本案例中,此正则的意思是仅匹配两个数字
打印结果
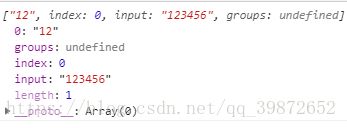
-2). {n,} 匹配至少n个(包括n)
reg = /\d{2,}/;
console.log(reg.exec(str));// 打印 ["123456"]
str = "12";
console.log(reg.exec(str));// 打印 ["12"]
str = "1";
console.log(reg.exec(str));// 打印 null打印结果
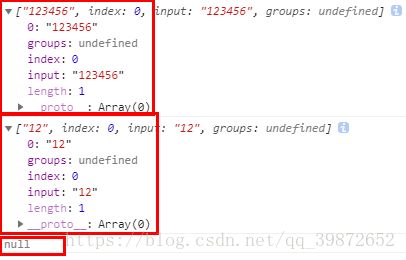
-3). {m,n} 匹配最少m个最多n个(包括m与n)
str = "1";
reg = /\d{2,3}/;
console.log(reg.exec(str));// 打印null
str = "12";
console.log(reg.exec(str));// 打印 ["12"]
str = "1234";
console.log(reg.exec(str));// 打印 ["123"]打印结果:
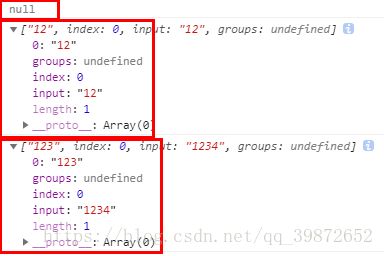
由上方代码可知,当只有一个元素的时候不符合条件,所以没有匹配到进而返回![]() ,当有两个元素的时候符合{2,3}中的2,所以返回
,当有两个元素的时候符合{2,3}中的2,所以返回
![]() 当有三个数字的时候符合{2,3}中的3,所以直接跳过2就以3为准。
当有三个数字的时候符合{2,3}中的3,所以直接跳过2就以3为准。
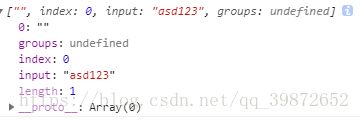
-4). * 、+、?
* 代表匹配0个及0个以上 <=> {0,}。
let reg = /\d*/;
let str = "asd123";
console.log(reg.exec(str));// 打印 [""]为什么会打印[""],就是因为正则在查找的时候上来就遇到了a,a是字母但却不是数字而且同时受限定符影响符合0个或多个的定义,故就不会再向后面进行查找,所以返回[""],在这很多人又疑惑了,既然没有匹配到为什么返回的不是null而是"" -> 空的字符串的呢?其实正则匹配到了内容只是匹配到了0个数字,所以会返回"" -> 空字符串而不是null。打印结果:
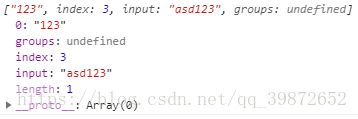
+代表匹配1个及一个以上 <=> {1,}。
reg = /\d+/;
console.log(reg.exec(str));// 打印["123"]为什么这块打印的就是["123"]呢?+与*不同, +是至少匹配1个, *是至少匹配0个,当上来遇见a的时候没有符合条件继续向后查找直到找到了123并且123符合匹配的条件就会将其返回。打印结果:
?代表匹配最少0个最多1个(包括0与1)。
reg = /\d?/;
console.log(reg.exec(str));// 打印 [""]
str = "101";
console.log(reg.exec(str));// 打印 1至于第一次打印返回[""]的原因与*的原因相同,*至少匹配0个而?是匹配0个或1个,针对于0个来说对他们俩都有意义,所以当他们一上来遇到的是a而不是数字的时候就会放弃查找直接匹配0个,并返回"" -> 空字符串。
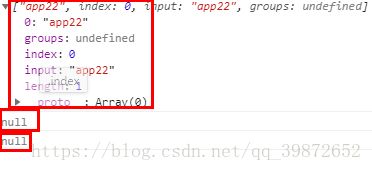
-5). ^与$
^ 表示必须在开头
$表示必须在结尾
let str = "app22";
let reg = /^app\d{2}$/;
console.log(reg.exec(str));// 打印 ["app22"]
str = "app22kg";
console.log(reg.exec(str));// 打印 null
str = "spp22";
console.log(reg.exec(str));// 打印 null/^app\d{2}$/这个正则的意思就是匹配开头字母是a的带有字母pp后面跟着两个数字并且结尾必须是数字的元素。
打印结果:
-6). | 表示或的意思(左右两边分别都被当成一个整体)
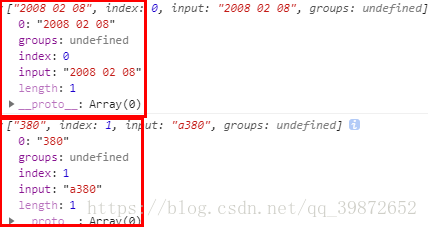
let reg = /\d{4}\s\d{2}\s\d{2}|\d{3}/;
let str = "2008 02 08";
console.log(reg.exec(str));// 打印 ["2008 08 08"]
str = "a380";
console.log(reg.exec(str));// 打印 ["380"]此正则的意思是匹配一个时间或者3个数字
打印结果:
-7). [] 表示匹配[...]内的任意一个元素
注意:[]与|不同,比如ac|bc代表匹配ac或者bc,而[abc]的意思是匹配a、c、b中的任意一个...
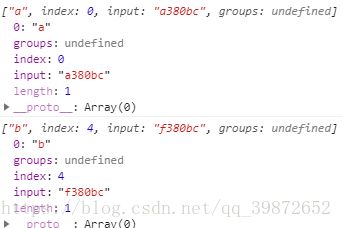
let reg = /[abc]/;
let str = "a380bc";
console.log(reg.exec(str));// 打印 ["a"]
str = "f380bc";
console.log(reg.exec(str));// 打印 ["b"]打印结果:
另外:/[a-z]/表示匹配任何一个小写英文字母,/A-Z/表示匹配任何一个大写字母,/0-9/表示匹配0~9的数字中的任何一个。
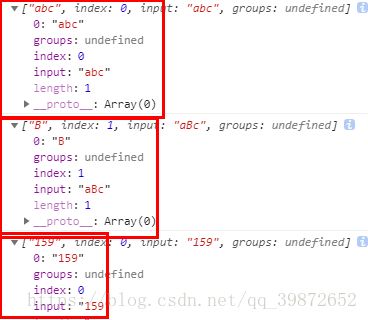
reg = /[a-z]+/;
str = "abc";
console.log(reg.exec(str));// 打印 ["abc"]
str = "aBc";
reg = /[A-Z]+/;
console.log(reg.exec(str));// 打印 ["B"]
reg = /[0-9]+/;
str = "159";
console.log(reg.exec(str));// 打印 ["159"]打印结果:
## 由此说来\w就等同于[a-zA-Z0-9_]
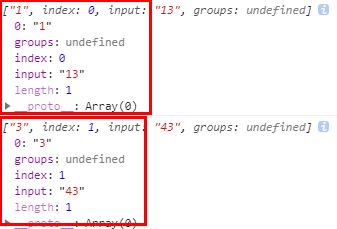
注意: 但是[1-13]并不代表匹配1~13内任何一个数字,而是代表匹配1到1或3,即匹配1或者3
reg = /[1-13]/;
str = "13";
console.log(reg.exec(str));// 打印 ["1"]
str = "43";
console.log(reg.exec(str));// 打印 ["3"]打印结果:
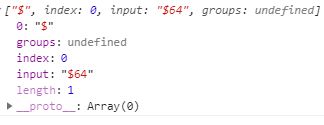
注意:元字符在[...]内不再表示元字符的含义而是表示其本身
reg = /[$&]/;
str = "$64";
console.log(reg.exec(str));// 打印 ["$"]打印结果:
-8). [^...]反字符集合([^abc]就代表不匹配a或b或c中的任何一个)
let reg = /[^abc]/;
let str = "abcd";
console.log(reg.exec(str));// 打印 ["d"]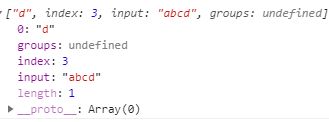
-9). ()分组 => 子正则(不仅返回匹配的父正则的内容,连(...)里面的匹配的内容也一并返回)
let reg = /(a|b)c/;
let str = "ac";
console.log(reg.exec(str));// 打印 ["ac", "a"]打印结果:

-10). (...)\num分组引用
let reg = /(a|b)(a|b)\2\1c/;
let str = "baabc";
console.log(reg.exec(str));// 打印 ["baabc", "b", "a"]// Ⅰ Ⅱ
// \2与\1会被当成 => /(a|b)(a|b)Ⅱ处的结果Ⅰ处的结果c/ =>
// 由于[(a|b)(a|b)...]这俩会先匹配到ba,再把a放到\2的位置b放到\1的位置进行匹配... /baabc/打印结果:

-11). (?:...)匹配不捕获(我们都知道正则表达式默认是贪婪模式即尽可能多的匹配,所以为了避免()子正则也出现这种状况通过?:来解决)
// 正常情况下
let reg = /(b|a)c/;
let str = "acd";
console.log(reg.exec(str));// 打印 ["ac", "a"]
// 匹配不捕获
reg = /(?:a|b)c/;
console.log(reg.exec("acd"));// 打印 ["ac"]打印结果:

上面我们不是使用分组(子正则)的时候,小括号里面匹配到的内容不是也会被返回吗?但是使用了匹配不捕获就不会出现那样的情况,即忽视子正则匹配的内容仅仅返回父正则匹配的内容。
-12). 正向预查与负向预查
## 正向预查与负向预查的含义就是,假如有一个"abchaha"的字符串与"defhaha的字符串",我们只需adc后的haha,我们可以这么做
正向预查:(? = ...)
let reg = /haha(?=def)/;
let str = "hahadef";
console.log(reg.exec(str));// 打印 ["def"]
str = "hahaxixi";
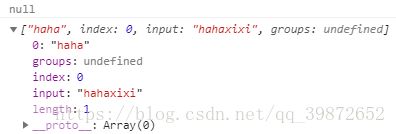
console.log(reg.exec(str));// 打印 null// 查找后缀是def的haha,而非xixi的haha负向预查:(? ! ...)
## 负向预查与正向预查相反,负向预查是必须不满足这个条件才算匹配:
let str = "hahadef";
let reg = /haha(?!def)/;
console.log(reg.exec(str));// 打印 null
str = "hahaxixi";
console.log(reg.exec(str));// 打印 ["haha"]打印结果:
-13). . 代表匹配除了\n以外的任意字符
let reg = /.+/;
let str= "123";
console.log(reg.exec(str));//打印 ["123"]
str = "1\n23";
console.log(reg.exec(str));// 打印 ["1"]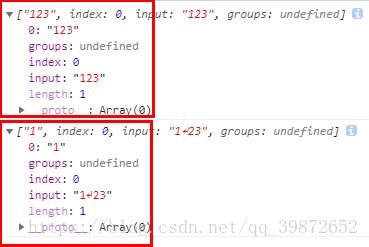
-
认识修饰符(修饰整个正则的行为特点)
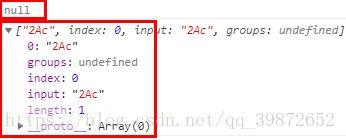
-1). i修饰符 => 大小写不敏感
let reg = /\dac/;
let str = "2Ac";
console.log(reg.exec(str));// 打印null
reg = new RegExp(reg, "i");
console.log(reg.exec(str));// 打印["2Ac"]打印结果:
-2). m修饰符 => 多行匹配
let reg= /\d/;
let str = "s\n2";
console.log(reg.exec(str));// 打印["2"]
reg = /^\d/;
console.log(reg.exec(str));// 打印 null
reg = new RegExp(reg, "m");
console.log(reg.exec(str));//打印 ["2"]打印结果:
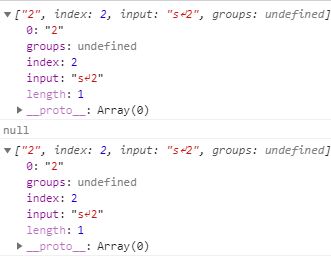
至于为什么/\d/就能匹配到"s\n2"中的2呢?别看这里有个换行符\n,这个换行符再厉害也是这个字符串里面的,/\d/上来没匹配到数字就像后匹配最后匹配到了2并将其以数组的形式返回,但是/^\d/与/\d/不同\^\d\要求匹配开头是数字的,显然一上来没有匹配到,就直接返回null。但是再加上m修饰符后/^\d/m, \n也代表的另起一行所以\n后面的数字就是另起一行的开头,m又代表多行匹配,所以就匹配到了并将其以数组的形式返回。
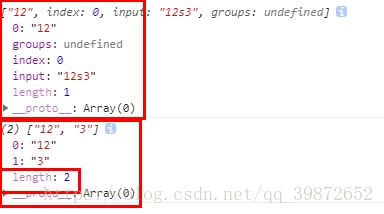
-3) g修饰符 => 全局查找
let reg = /\d{1,}/;
let str = "12s3";
console.log(reg.exec(str));// 打印 ["12"]
reg = new RegExp(reg, "g");
console.log(str.match(reg));// 打印 (2) ["12", "3"]打印结果:
-
常用的正则方法与支持正则的字符串方法
- 正则方法:exec与test在上面介绍完毕就不做过多赘述啦...
- 支持正则的字符串方法
-1).search方法 => 查找指定字符所在位置的索引
let reg = /\d/;
let str = "sd2ds";
console.log(str.search(reg));// 打印 2打印结果:
![]()
-2).match方法 => 查找指定索引对应的字符
console.log(str.match(str.search(reg)));// 打印 ["2"]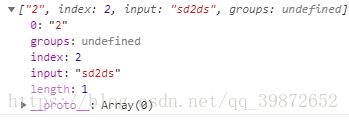
-3).replace方法 => 替换指定字符
reg = /[a-zA-Z]/g;
console.log(str.replace(reg, "1"));// 打印 11211打印结果:
![]()
-
exec与macth的区别
## 说到这两个方法的区别:
-1).exec是正则相关的方法而match是支持正则的字符串方法(一个是正则方法、一个是字符串方法)。
-2).在处理分组的时候二者相同,在处理(修饰符g)与(修饰符g + 分组)的问题上二者存在差异
处理分组:
let reg = /(a|b)c/;
let str = "acbc";
console.log(reg.exec(str));// 打印 ["ac", "a"]
console.log(str.match(reg));// 打印 ["ac", "a"]打印结果:

处理修饰符g + 分组
reg = new RegExp(reg, "g");
console.log(reg.exec(str));// 打印 ["ac", "a"]
console.log(str.match(reg));// 打印 ["ac"]打印结果:
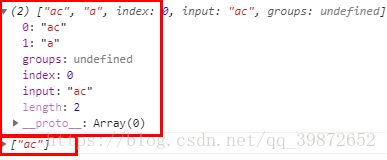
可见在处理修饰符g + 分组的时候exec会忽略修饰符g,match则忽略了分组。
处理全局修饰符g:
reg = /\d/g;
str = "1a2";
console.log(reg.exec(str));// 打印 ["1"]
console.log(str.match(reg));// 打印 (2) ["1", "2"]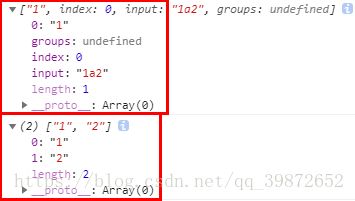
由此可见在处理修饰符g的时候,exec方法照样还是会忽略修饰符g,
而字符串方法match就不会忽略修饰符g。
-
常用的正则
-1).手机号: /^1[34578][0-9]\d{8}/
let reg_phone = /^1[34578][0-9]\d{8}/;// 手机号正则
let str_phone = "17803218829";
console.log(reg_phone.exec(str_phone));// 打印 ["17803218829"]
打印结果:

-2).邮箱: /^[0-9a-z]+@[0-9a-z]+\.(?:com.cn|(?:com|cn))/
let reg_email = /^[0-9a-z]+@[0-9a-z]+\.(?:com.cn|(?:com|cn))/;// 邮箱的正则
let str_email = "[email protected]";
console.log(reg_email.exec(str_email));// 打印 ["[email protected]"]
打印结果:

-3).匹配任何所有字符: /^[\s\S]*$/
let reg_free = /^[\s\S]*$/;
let str_free = "I LOVE YOU!";
console.log(reg_free.exec(str_free));// 打印 ["I LOVE YOU!"]

## 总结:
以上就是JavaScript中的正则简单的入门,掌握这些基本的知识就可以看懂大部分类似火星文的正则表达式,而且这也是我们前端人必不可少的一项技能!如果不正确的地方还请指正,有疑问或有建议的朋友请在下方留言!