分布式爬虫
什么是分布式爬虫?
1.默认情况下,scrapy爬虫是单机爬虫,只能在一台电脑上运行,因为爬虫调度器当中的队列queue去重和set集合都是本机上创建的 其他的电脑无法访问另外一台电脑上的内存的内容。
2.分布式爬虫用一个共同的爬虫程序,同时部署到多台电脑上运行,这样可以 提高爬虫速度,实现分布式爬虫。
分布式爬虫的前提
1.要保证每一台计算机都能够正常的执行scrapy命令,能够启动爬虫。
2.要保证所有的爬虫程序可以访问同一个队列一个set集合。
想要保证多台机器共用一个queue队列和set集合,scrapy中是结合scrapy_redis完成的,分布式爬虫可以让所有机器上的爬虫程序从同一个queue队列中获取request请求, 并且每个机器取出request请求的对象是不一样的,直到所有的request被请求完毕。
分布式爬虫的使用范围/要求
1.分布式爬虫对电脑的性能有一定的要求。
2.分布式对网速也有一定的要求, 电脑性能和网速如果不是很好的话,爬虫效率不如单机爬虫 注意:并不是任何时候都可以使用分布式爬虫,因为对硬件有较高的要求。
分布式爬虫经常和redis数据库一起使用。
redis简介
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
redis优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
简单的来说redis的优点为:
1.默认使用持久化数据方式
2.体积小,使用方便
3.如果存储量比较大的话启动速度很快
4.数据库中的数据和内存中的数据可以相互访问
redis的缺点为:
从安全性的角度来说,持久化数据可能会崩溃,造成数据丢失。
要实现分布式爬虫,首先要配置服务器主从
配置主从的目的:
达到一个备份的功能,一旦master出现崩溃,而数据库中还有数据, 可以将其中的一个slave重新设置为主服务器,从而恢复redis的正常运行。
2.一个redis服务器负责读写,性能较低,通过主从来减轻一个redis的压力
redis主从的配置
redis作为缓存服务器,主要是将数据在内存中进行缓存,但是一台机器的内存和性能是有限的 当对于redis数据库的数据进行读写量较大的时候,那么一台redis就不能满足需求了 此时,需要将redis部署到多台机器上,用于写入数据的redis,称之为master, 而只负责读取数据的redis,称之为slave。
redis主从的特点
1.master只负责写入数据,slave只负责读取数据 。
2.当slave创建的时候,会向master发送一个同步的命令,master接收到命令以后 将数据同步给slave 。
3.master只能有一个,slave可以有多个。
redis安装
下载地址:https://github.com/MSOpenTech/redis/releases
Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到电脑,解压后,将文件夹重新命名为 redis。

解压之后重命名的文件夹:

打开一个cmd的窗口,使用cd命令切换目录到你解压的文件夹路径之后运行下面的命令。
redis-server redis.windows.conf如果想要方便的话,可以把redis的路径加到系统环境变量里面,这样就省得用cd来切换目录了,不过后面的redis.windows.conf不能省略,否则连接服务端可能会出问题。
注意:配置环境变量之后创建服务端也需要cd到redis的路径,连接redis服务端不用cd。
输入之后,会显示如下界面:

这个时候再开启一个cmd窗口,原来的那个不要关闭,不然就不能访问服务端了。
切换到redis目录下运行以下命令:
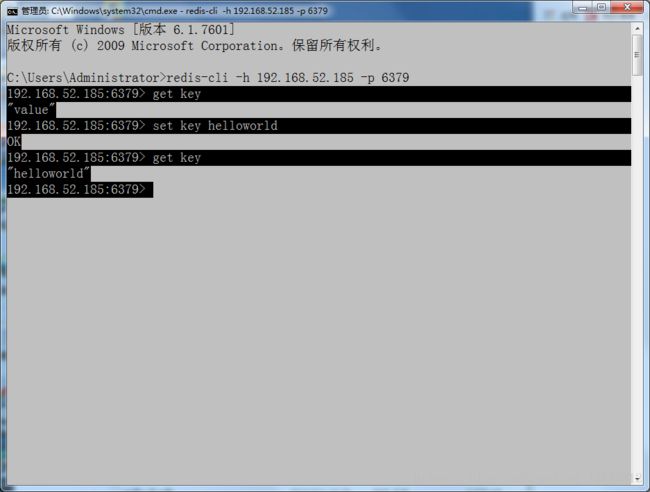
redis-cli -h 127.0.0.1 -p 6379设置键值对:
set mykey helloworld取出键值对:
get mykey
配置环境变量
1.进入redis文件夹点击地址栏把路径复制下来。

2.然后在左侧的计算机上面鼠标右键选择属性。

3.点击高级系统设置。

4.点击环境变量。
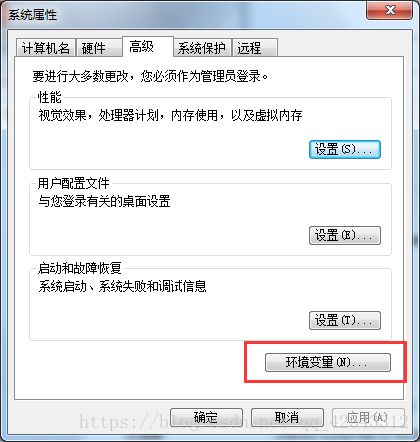
5.在下面的系统变量里面知道path,双击或者选中之后点编辑按钮。
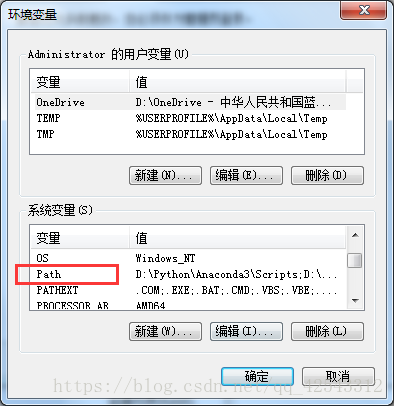
6.把光标移到最后面先添加一个英文分号,一定要添加一个英文分号,然后把复制的redis的路径粘贴上去。
配置完之后把刚才打开的窗口都点确定就完成了。

redis配置
为了让我们能正常的练习使用redis我们需要对redis进行一些配置。
用编译工具打开redis文件夹里面的redis.windows.conf文件。

把bind 127.0.0.1前面加上#号注释掉。

把protected-mode后面的yes改为no,关闭保护模式。

把daemonize后面值改为no,关闭守护进程。

配置完成之后我们就可以让其他的电脑来连接我们的redis了。
连接其他电脑的redis
在cmd输入一下命令连接到其他电脑的redis服务端:
-h后面是你要连接redis服务端电脑的ip地址。
redis-cli -h 192.168.XXX.XXX -p 6379使用get获取redis服务端的键值对。
get key也可以使用set创建键值对,如果已存在则会覆盖。
set key helloworld