生成式对抗网络对比(GAN--pix to pix--cycleGAN)
- 神经网络只要有非线性激活函数,就可以去拟合任意的函数,那么分布也是一样,所以可以用一直正态分布,或者高斯分布,取样去训练一个神经网络,学习到一个很复杂的分布。
GAN
- 单向
- 用于生成图片
- 为生成一个生成器,该生成器可以产生新的原训练集中没有的数据
- 如有一系列猫的图片,①给鉴别器判别他们是真的图片,②训练生成器时输入随机变量,生成器随机生成一张图片(此图片随机)③把这张图片拿去训练鉴别器,鉴别器会输出假 ④用鉴别器去训练生成器,让生成器可以生成更好的图片,使得这一代鉴别器判别为真,则训练鉴别器... 不断重复操作。
- 注意:通过损失函数来训练,其中G、F(映射函数)等函数都是在训练过程中确定(开始为随机值),并不断修改
- 虽然最终生成器能产生随机的真的图像,但因为你是拿你的数据集,如你的数据集里是各种各样猫的图片,则最终生成器产生的也会是猫的图片,不过不在训练集里,因为你是拿猫的图片训练鉴别器,所以它会认为“哦,原来这种图片是真的图片啊”,即如果你拿一张狗的拍的真实的图片给鉴别器判别,它会说这是假的,所以记住,机器是很傻的,只有通过一种一种的训练它才会.
- 生成器和鉴别器相互博弈,最终使二者都成为专家
e.g
首先,有一个一代的 generator,它能生成一些很差的图片,然后有一个一代的 discriminator,它能准确的把生成的图片,和真实的图片分类,简而言之,这个 discriminator 就是一个二分类器,对生成的图片输出 0,对真实的图片输出 1。
接着,开始训练出二代的 generator,它能生成稍好一点的图片,能够让一代的 discriminator 认为这些生成的图片是真实的图片。然后会训练出一个二代的 discriminator,它能准确的识别出真实的图片,和二代 generator 生成的图片。以此类推,会有三代,四代。。。n 代的 generator 和 discriminator,最后 discriminator 无法分辨生成的图片和真实图片,这个网络就拟合了。

- 生成器:
训练一个 encoder,把 input 转换成 code,然后训练一个 decoder,把 code 转换成一个 image,然后计算得到的 image 和 input 之间的 MSE(mean square error,一般是每一个像素上的均方差,但会有一些鉴别不出),训练完这个 model 之后,取出后半部分 NN Decoder,输入一个随机的 code,就能 generate 一个 image。

1. 生成模型功能:比作是一个样本生成器,输入一个噪声/样本,然后把它包装成一个逼真的样子,也就是输出。
2. 判别模型:比作一个二分类器(如同0-1分类器),来判断输入的样本是真是假。(就是输出值大于0.5还是小于0.5)
训练GAN的步骤
第1步:定义问题。你想生成假的图像还是文字?你需要完全定义问题并收集数据。
第2步:定义GAN的架构。GAN看起来是怎么样的,生成器和鉴别器应该是多层感知器还是卷积神经网络?这一步取决于你要解决的问题。
第3步:用真实数据训练鉴别器N个epoch。训练鉴别器正确预测真实数据为真。(注意:鉴别器并不是真的能“看出”如一张图是真实的还是电脑生成的,而是通过输入真实图片和生成图片训练多次而得)这里N可以设置为1到无穷大之间的任意自然数。
第4步:用生成器产生假的输入数据,(输入为随机向量)用来训练鉴别器。训练鉴别器正确预测假的数据为假。
第5步:用鉴别器的输入训练生成器。当鉴别器被训练后,将其预测值作为标记来训练生成器。训练生成器来迷惑鉴别器。
第6步:重复第3到第5步多个epoch
第7步:手动检查假数据是否合理。如果看起来合适就停止训练,否则回到第3步。这是一个手动任务,手动评估数据是检查其假冒程度的最佳方式。当这个步骤结束时,就可以评估GAN是否表现良好。
(如果不只是产生图片那么简单,GAN过程常常在生成一张图片x后,再加一个生成器(重建)Gba,来看能不能把y还原为x,以保证生成图片与原图有相似特征,如轮廓不变等,避免发生“生成器永远生成同一张“真实”图片,因为判别器判别它为真”)

1.重建Loss:希望生成的图片Gba(Gab(a))与原图a尽可能的相似。
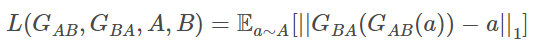
2.判别Loss:生成的假图片和原始真图片都会输入到判别器中。公式为0,1二分类的损失。
![]()
这样可使判别器对真实图像输出为1,对生成器生成图像输出为0时损失最小
公式:

目标公式
先优化D,然后再优化G,拆解之后就如下:
优化D:

优化D
优化D,即优化判别网络时,没有生成网络什么事,后面的G(z)这里就相当于已经得到的假样本。优化D的公式的第一项,使得真样本x输入的时候,得到的结果越大越好,因为真样本的预测结果越接近1越好;对于假样本,需要优化的是其结果越小越好,也就是D(G(z))越小越好,因为它的标签为0。但是第一项越大,第二项越小,就矛盾了,所以把第二项改为1-D(G(z)),这样就是越大越好。
优化G:

优化G
在优化G的时候,这个时候没有真样本什么事,所以把第一项直接去掉,这时候只有假样本,但是我们说这个时候是希望假样本的标签是1,所以是D(G(z))越大越好,但是为了统一成1-D(G(z))的形式,那么只能是最小化1-D(G(z)),本质上没有区别,只是为了形式的统一。之后这两个优化模型可以合并起来写,就变成最开始的最大最小目标函数了。
GAN强大之处在于可以自动的学习原始真实样本集的数据分布
pix to pix
- 可用于给图像上色
- 改进:输入不是随机变量了,是图像,要求提供image pairs。
损失函数

对于图像翻译任务,G的输入和输出之间其实共享了很多信息,比如图像上色任务,输入和输出之间就共享了边信息。因而为了保证输入图像和输出图像之间的相似度,还加入了L1 Loss
![]()
那么,汇总的损失函数为

生成网络G
正如上所说,输入和输出之间会共享很多的信息。如果使用普通的卷积神经网络,那么会导致每一层都承载保存着所有的信息,这样神经网络很容易出错,因而,使用U-Net来进行减负。
(先卷积提取图像特征,再反卷积上色,GAN只有后一步,即直接输入coder)

上图中,首先U-Net也是Encoder-Decoder模型,其次,Encoder和Decoder是对称的。
所谓的U-Net是将第i层拼接到第n-i层,这样做是因为第i层和第n-i层的图像大小是一致的,可以认为他们承载着类似的信息。
判别网络D
在损失函数中,L1被添加进来来保证输入和输出的共性。这就启发出了一个观点,那就是图像的变形分为两种,局部的和全局的。既然L1可以防止全局的变形。那么只要让D去保证局部能够精准即可。
cycleGAN
-
双向
-
用于风格迁移
-
不要求提供pairs,即Unpaired
- 改进:输入是张图片,不过可以是unpaired,即两张图片可以没有任何关系
- 为了规范模型,作者介绍了循环一致性的约束条件:如果我们从源分布转换为目标分布,然后再次转换回源分布,那么应该可以从源分布中获取样本。


两个GAN共享两个生成器,并各自带一个判别器,即共有两个判别器和两个生成器。一个单向GAN两个loss,两个即共四个loss。



参考文章:
https://www.cnblogs.com/bonelee/p/9166084.html
https://www.jianshu.com/p/64bf39804c80
pix2pix:https://blog.csdn.net/stdcoutzyx/article/details/78820728
常用损失函数:https://blog.csdn.net/willduan1/article/details/73694826