一、概述
Ceph是一个分布式存储系统,诞生于2004年,最早致力于开发下一代高性能分布式文件系统的项目。随着云计算的发展,ceph乘上了OpenStack的春风,进而成为了开源社区受关注较高的项目之一。
Ceph有以下优势:
1. CRUSH算法
Crush算法是ceph的两大创新之一,简单来说,ceph摒弃了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法完成数据的寻址操作。CRUSH在一致性哈希基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。Crush算法有相当强大的扩展性,理论上支持数千个存储节点。
2. 高可用
Ceph中的数据副本数量可以由管理员自行定义,并可以通过CRUSH算法指定副本的物理存储位置以分隔故障域,支持数据强一致性; ceph可以忍受多种故障场景并自动尝试并行修复。
3. 高扩展性
Ceph不同于swift,客户端所有的读写操作都要经过代理节点。一旦集群并发量增大时,代理节点很容易成为单点瓶颈。Ceph本身并没有主控节点,扩展起来比较容易,并且理论上,它的性能会随着磁盘数量的增加而线性增长。
4. 特性丰富
Ceph支持三种调用接口:对象存储,块存储,文件系统挂载。三种方式可以一同使用。在国内一些公司的云环境中,通常会采用ceph作为openstack的唯一后端存储来提升数据转发效率。
二、CEPH的基本结构
Ceph的基本组成结构如下图:
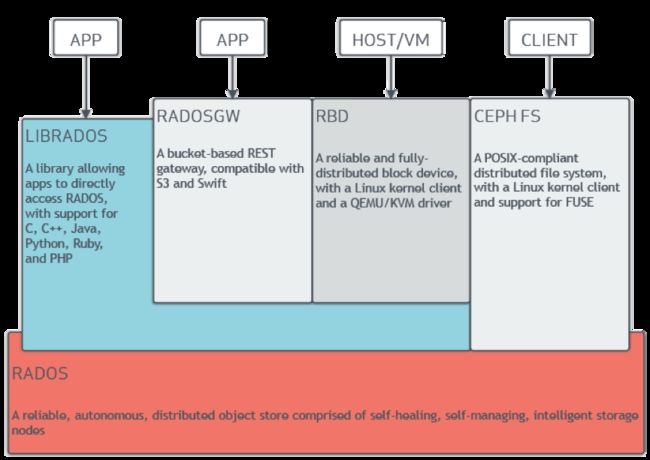
Ceph的底层是RADOS,RADOS本身也是分布式存储系统,CEPH所有的存储功能都是基于RADOS实现。RADOS采用C++开发,所提供的原生Librados API包括C和C++两种。Ceph的上层应用调用本机上的librados API,再由后者通过socket与RADOS集群中的其他节点通信并完成各种操作。
RADOS GateWay、RBD其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中,RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。这两种方式目前在云计算中应用的比较多。
CEPHFS则提供了POSIX接口,用户可直接通过客户端挂载使用。它是内核态的程序,所以无需调用用户空间的librados库。它通过内核中的net模块来与Rados进行交互。
三、Ceph的基本组件
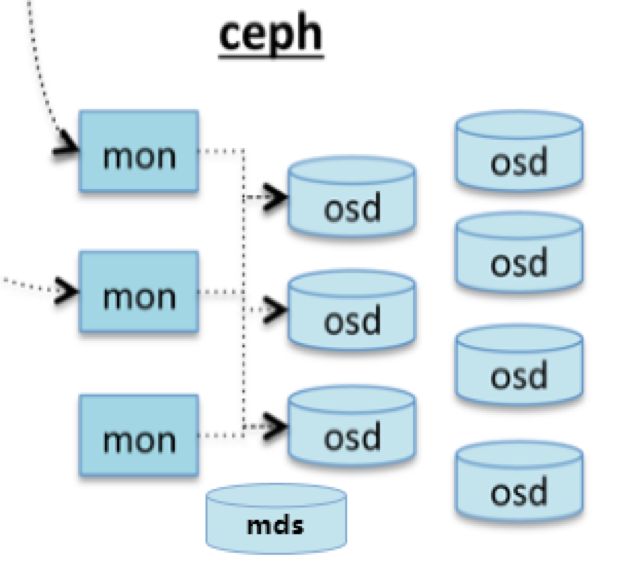
如上图所示,Ceph主要有三个基本进程
-
Osd
用于集群中所有数据与对象的存储。处理集群数据的复制、恢复、回填、再均衡。并向其他osd守护进程发送心跳,然后向Mon提供一些监控信息。
当Ceph存储集群设定数据有两个副本时(一共存两份),则至少需要两个OSD守护进程即两个OSD节点,集群才能达到active+clean状态。 -
MDS(可选)
为Ceph文件系统提供元数据计算、缓存与同步。在ceph中,元数据也是存储在osd节点中的,mds类似于元数据的代理缓存服务器。MDS进程并不是必须的进程,只有需要使用CEPHFS时,才需要配置MDS节点。
-
Monitor
监控整个集群的状态,维护集群的cluster MAP二进制表,保证集群数据的一致性。ClusterMAP描述了对象块存储的物理位置,以及一个将设备聚合到物理位置的桶列表。
四、OSD
首先描述一下ceph数据的存储过程,如下图:

无论使用哪种存储方式(对象、块、挂载),存储的数据都会被切分成对象(Objects)。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成,虽然这些名词看上去很复杂,其实相当简单。ino即是文件的File ID,用于在全局唯一标示每一个文件,而ono则是分片的编号。比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。Oid的好处是可以唯一标示每个不同的对象,并且存储了对象与文件的从属关系。由于ceph的所有数据都虚拟成了整齐划一的对象,所以在读写时效率都会比较高。
但是对象并不会直接存储进OSD中,因为对象的size很小,在一个大规模的集群中可能有几百到几千万个对象。这么多对象光是遍历寻址,速度都是很缓慢的;并且如果将对象直接通过某种固定映射的哈希算法映射到osd上,当这个osd损坏时,对象无法自动迁移至其他osd上面(因为映射函数不允许)。为了解决这些问题,ceph引入了归置组的概念,即PG。
PG是一个逻辑概念,我们linux系统中可以直接看到对象,但是无法直接看到PG。它在数据寻址时类似于数据库中的索引:每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。而且在数据迁移时,也是以PG作为基本单位进行迁移,ceph不会直接操作对象。
对象时如何映射进PG的?还记得OID么?首先使用静态hash函数对OID做hash取出特征码,用特征码与PG的数量去模,得到的序号则是PGID。由于这种设计方式,PG的数量多寡直接决定了数据分布的均匀性,所以合理设置的PG数量可以很好的提升CEPH集群的性能并使数据均匀分布。
最后PG会根据管理员设置的副本数量进行复制,然后通过crush算法存储到不同的OSD节点上(其实是把PG中的所有对象存储到节点上),第一个osd节点即为主节点,其余均为从节点。
下面是一段ceph中的伪代码,简要描述了ceph的数据存储流程
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
osds_for_pg = crush(pg) # returns a list of osds
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]
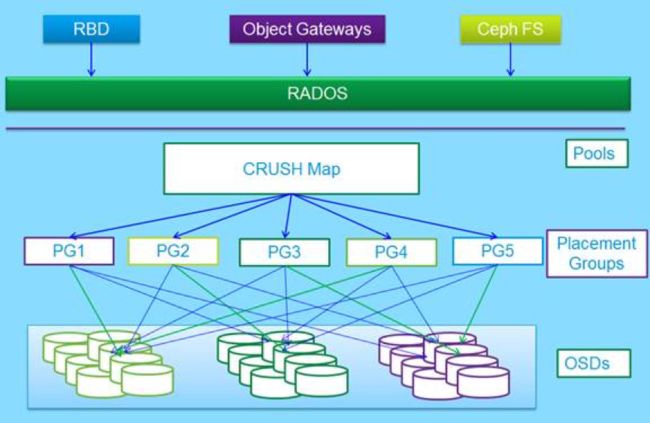
上图中更好的诠释了ceph数据流的存储过程,数据无论是从三中接口哪一种写入的,最终都要切分成对象存储到底层的RADOS中。逻辑上通过算法先映射到PG上,最终存储近OSD节点里。图中除了之前介绍过的概念之外多了一个pools的概念。
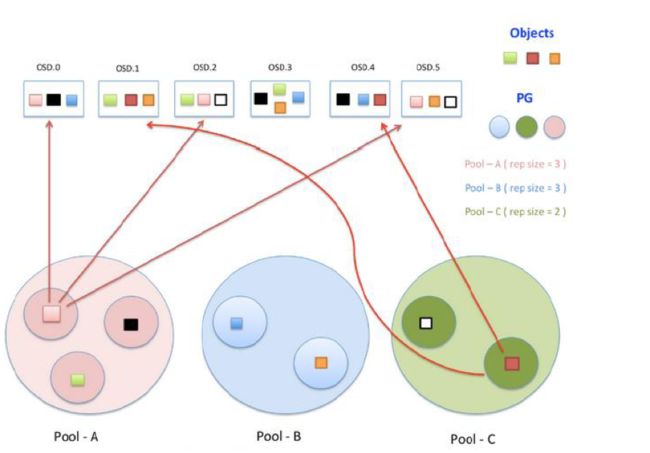
Pool是管理员自定义的命名空间,像其他的命名空间一样,用来隔离对象与PG。我们在调用API存储即使用对象存储时,需要指定对象要存储进哪一个POOL中。除了隔离数据,我们也可以分别对不同的POOL设置不同的优化策略,比如副本数、数据清洗次数、数据块及对象大小等。
OSD是强一致性的分布式存储,它的读写流程如下图
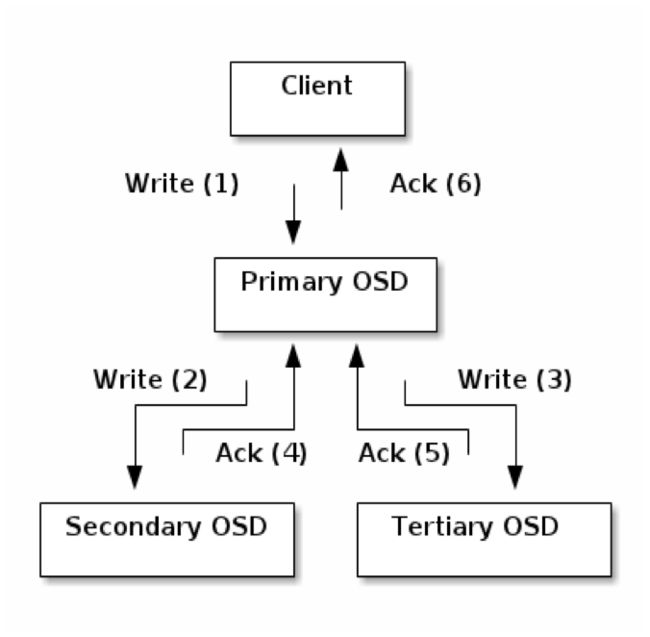
Ceph的读写操作采用主从模型,客户端要读写数据时,只能向对象所对应的主osd节点发起请求。主节点在接受到写请求时,会同步的向从OSD中写入数据。当所有的OSD节点都写入完成后,主节点才会向客户端报告写入完成的信息。因此保证了主从节点数据的高度一致性。而读取的时候,客户端也只会向主osd节点发起读请求,并不会有类似于数据库中的读写分离的情况出现,这也是出于强一致性的考虑。由于所有写操作都要交给主osd节点来处理,所以在数据量很大时,性能可能会比较慢,为了克服这个问题以及让ceph能支持事物,每个osd节点都包含了一个journal文件,稍后介绍。
数据流向介绍到这里就告一段落了,现在终于回到正题:osd进程。在ceph中,每一个osd进程都可称作是一个osd节点,也就是说,每台存储服务器上可能包含了众多的osd节点,每个osd节点监听不同的端口,类似于在同一台服务器上跑多个mysql或redis。每个osd节点可以设置一个目录作为实际存储区域,也可以是一个分区,一整块硬盘。如下图,当前这台机器上跑了两个osd进程,每个osd监听4个端口,分别用于接收客户请求、传输数据、发送心跳、同步数据等操作。
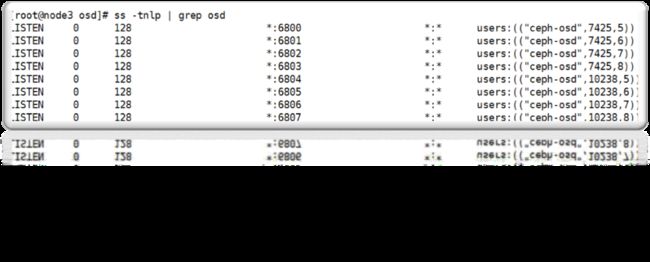
如上图所示,osd节点默认监听tcp的6800到6803端口,如果同一台服务器上有多个osd节点,则依次往后排序。
在生产环境中的osd最少可能都有上百个,所以每个osd都有一个全局的编号,类似osd0,osd1,osd2........序号根据osd诞生的顺序排列,并且是全局唯一的。存储了相同PG的osd节点除了向mon节点发送心跳外,还会互相发送心跳信息以检测pg数据副本是否正常。
之前在介绍数据流向时说过,每个osd节点都包含一个journal文件,如下图:

默认大小为5G,也就说每创建一个osd节点,还没使用就要被journal占走5G的空间。这个值是可以调整的,具体大小要依osd的总大小而定。
Journal的作用类似于mysql innodb引擎中的事物日志系统。当有突发的大量写入操作时,ceph可以先把一些零散的,随机的IO请求保存到缓存中进行合并,然后再统一向内核发起IO请求。这样做效率会比较高,但是一旦osd节点崩溃,缓存中的数据就会丢失,所以数据在还未写进硬盘中时,都会记录到journal中,当osd崩溃后重新启动时,会自动尝试从journal恢复因崩溃丢失的缓存数据。因此journal的io是非常密集的,而且由于一个数据要io两次,很大程度上也损耗了硬件的io性能,所以通常在生产环境中,使用ssd来单独存储journal文件以提高ceph读写性能。
五、monitor节点
Mon节点监控着整个ceph集群的状态信息,监听于tcp的6789端口。每一个ceph集群中至少要有一个Mon节点,官方推荐每个集群至少部署三台。Mon节点中保存了最新的版本集群数据分布图(cluster map)的主副本。客户端在使用时,需要挂载mon节点的6789端口,下载最新的cluster map,通过crush算法获得集群中各osd的IP地址,然后再与osd节点直接建立连接来传输数据。所以对于ceph来说,并不需要有集中式的主节点用于计算与寻址,客户端分摊了这部分工作。而且客户端也可以直接和osd通信,省去了中间代理服务器的额外开销。
Mon节点之间使用Paxos算法来保持各节点cluster map的一致性;各mon节点的功能总体上是一样的,相互间的关系可以被简单理解为主备关系。如果主mon节点损坏,其他mon存活节点超过半数时,集群还可以正常运行。当故障mon节点恢复时,会主动向其他mon节点拉取最新的cluster map。
Mon节点并不会主动轮询各个osd的当前状态,相反,osd只有在一些特殊情况才会上报自己的信息,平常只会简单的发送心跳。特殊情况包括:1、新的OSD被加入集群;2、某个OSD发现自身或其他OSD发生异常。Mon节点在收到这些上报信息时,则会更新cluster map信息并加以扩散。
cluster map信息是以异步且lazy的形式扩散的。monitor并不会在每一次cluster map版本更新后都将新版本广播至全体OSD,而是在有OSD向自己上报信息时,将更新回复给对方。类似的,各个OSD也是在和其他OSD通信时,如果发现对方的osd中持有的cluster map版本较低,则把自己更新的版本发送给对方。
推荐使用以下的架构
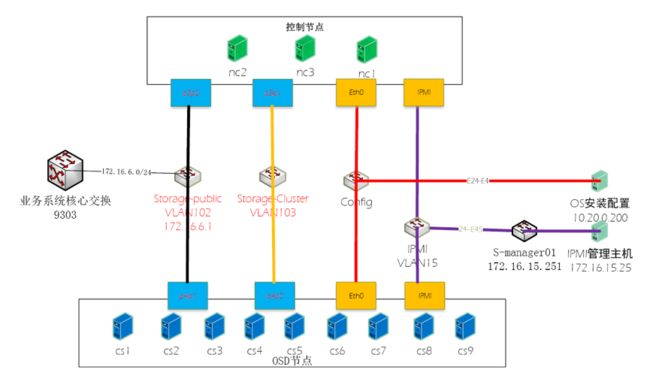
这里的ceph除了管理网段外,设了两个网段,一个用于客户端读写传输数据。另一个用于各OSD节点之间同步数据和发送心跳信息等。这样做的好处是可以分担网卡的IO压力。否则在数据清洗时,客户端的读写速度会变得极为缓慢。
六、MDS
Mds是ceph集群中的元数据服务器,而通常它都不是必须的,因为只有在使用cephfs的时候才需要它,而目在云计算中用的更广泛的是另外两种存储方式。
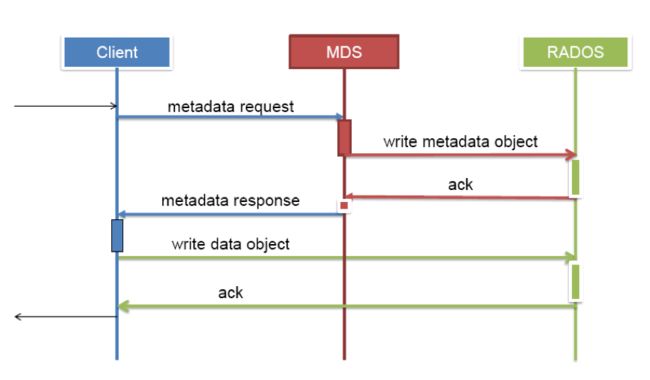
Mds虽然是元数据服务器,但是它不负责存储元数据,元数据也是被切成对象存在各个osd节点中的,如下图:
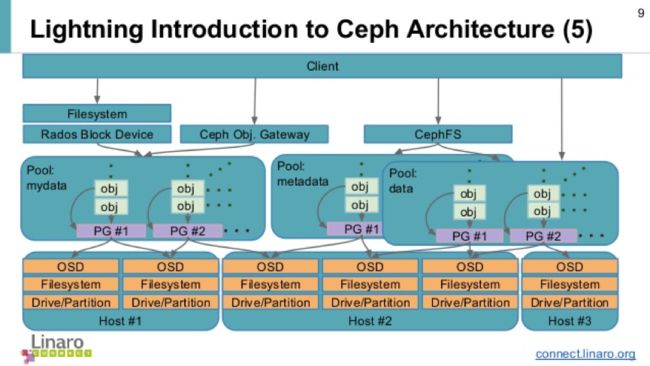
在创建CEPHFS时,要至少创建两个POOL,一个用于存放数据,另一个用于存放元数据。Mds只是负责接受用户的元数据查询请求,然后从osd中把数据取出来映射进自己的内存中供客户访问。所以mds其实类似一个代理缓存服务器,替osd分担了用户的访问压力,如下图:
七、cephfs的简易安装
在安装ceph之前推荐把所有的ceph节点设置成无需密码ssh互访,配置hosts支持主机名互访,同步好时间,并关闭iptables和selinux。
1、实验环境说明:
当前实验环境使用了4台主机node1~node4,node1为管理节点。
2、部署工具:
Ceph官方推出了一个用python写的工具 cpeh-deploy,可以很大的简化ceph集群的配置过程,建议大家用用。它的yum仓库地址,下载地址如下:
http://download.ceph.com/rpm-firefly/el6/noarch/
3、安装步骤
-
在管理主机上安装工具(通常是跳板机)
yum install -y ceph-deploy -
创建工作目录,用于存放生成的配置文件和秘钥等信息
Mkdir /ceph;cd /ceph -
下载yum源,下载地址如下
http://download.ceph.com/rpm-firefly/el6/noarch/
```
-
在node1~4上把上面的网址设置为yum源
yum install –y ceph -
到管理主机上的/ceph目录操作,创建一个新集群,并设置node1为mon节点
ceph-deploy new node1 执行完毕后,可以看到/ceph目录中生成了三个文件,其中有一个配置文件可以做各种参数优化,据说ceph的优化参数接近1000项。(注意,在osd进程生成并挂载使用后,想修改配置需要使用命令行工具,修改配置文件是无效的,所以需要提前规划好优化的参数。) -
在ceph.conf中添加四个最基本的设置
echo "osd pool default size = 4" >> ceph.conf echo "osd_pool_default_min_size = 3" >> ceph.conf echo "public network = 192.168.120.0/24" >> ceph.conf echo "cluster network = 10.0.0.0/8" >> ceph.conf 设置每个pool默认的副本数是两个(所有文件一共存四份,如果不设置此项则默认为三份副本);设置最小副本数为3,也就是说,4份副本的环境下有一个副本损坏了,其他osd可以照常相应用户的读写请求;设置公共网络地址段,即用于相应客户读写的网段;设置集群工作网段,用于集群同步数据、发送心跳等使用的网段。
-
激活监控节点
ceph-deploy mon create-initial -
接下来创建osd节点,本例中使用整个分区作为osd节点的物理存储区域
ceph-deploy osd prepare node2:/dev/sdb1 node3:/dev/sdb1 node4:/dev/sdb1 ceph-deploy osd prepare node2:/dev/sdb1 node3:/dev/sdb1 node4:/dev/sdb1 -
将管理节点上的配置文件同步到其他节点上
ceph-deploy --overwrite-conf admin node{1..4} -
建立元数据服务器
ceph-deploy mds create node1 -
创建两个池,最后的数字是PG的数量
ceph osd pool create test1 256 ceph osd pool create test2 256
-
创建cephfs文件系统,注意一个ceph只能创建一个cephfs
ceph fs new cephfs test2 test1 默认第一个池会存储元数据
到此一个简单的cephfs集群就诞生了,可以使用ceph –s查看,如果是HEALTH_OK状态说明配置成功
八、cephfs的删除
-
remove所有节点上的ceph
ceph-deploy purge node{1..4} -
清除所有数据
ceph-deploy purgedata node{1..4}
-
清除所有秘钥文件
ceph-deploy forgetkeys
九、结语
目前来说,ceph在开源社区还是比较热门的,但是更多的是应用于云计算的后端存储。官方推荐使用ceph的对象式存储,速度和效率都比较高,而cephfs官方并不推荐直接在生产中使用。以上介绍的只是ceph的沧海一粟,ceph远比上面介绍的要复杂,而且支持很多特性,比如使用纠删码就行寻址,所以大多数在生产环境中使用ceph的公司都会有专门的团队对ceph进行二次开发,ceph的运维难度也比较大。但是经过合理的优化之后,ceph的性能和稳定性都是值得期待的。