这篇文章我想以一个小项目为契机, 从头到尾讲解一遍构建 Neural Network 的基本思路.
这里是 一层, 二层, 三层神经网络的 TFiwS 实现, 比较容易理解的一个版本.
矩阵数学
1. 数据维度
我们知道现实数据都是可以抽象为数学数据输入到电脑中的.
| 类型 | 维度 | 举例 |
|---|---|---|
| Scalar(标量) | 0维 | 1 |
| Vector(向量) | 1维 | 行向量和列向量 |
| Matrix(矩阵) | 2维 | [[1, 2, 3], [4, 5, 6]], 2 x 3 矩阵 |
| Tensor(张量) | n维 | 标量是0维张量, 向量是1维张量... |
注意
- 向量也可以用1维矩阵来表示, 比如[1, 2, 3] 是1x3 矩阵
- 任何大于二维的数据都可以被张量表示, 但是 3 维及以上的数据很难被可视化.
三维数据我们可以想像成矩阵堆栈, 或者矩阵列表

举例:
对于一张图片, 每一个像素有三个颜色通道, R, G, B, 每一个通道都可以表示为一个值, 那么一张图片这么多像素点组成, 我们可以将这些值存储为 三维张量. 并用单独的平面来表示 红色值, 绿色值, 蓝色值.
2. 矩阵乘法
矩阵乘积(matmul): 对应位置的数据进行相乘.
矩阵点积(dot): 对应行数据与对应列数据进行相乘再相加

let x = Tensor([[1, 2], [3, 4]])
let y = Tensor([[1, 2, 3], [1, 2, 3], [1, 2, 3]])
let z = Tensor([[1, 2, 3], [1, 2, 3]])
x shape: [2, 2] y shape: [3, 3] z shape: [2, 3]
print(x * x) // [[1, 4], [9,16]]
print(x * y) // 编译失败, 无法相乘
print(x • x) // [[7, 10], [15, 22]]
print(x • y) // 编译失败, 无法相乘
print(x • z) // [[3, 6, 9], [7, 14, 21]] shape [2, 3]
小结:
- 对于矩阵乘积, 由于对应位置的数据进行相乘的这种机制, 导致只有相同 shape 的矩阵才能做乘积运算
- 对于矩阵点积, 由于对应行数据与对应列数据进行相乘再相加的机制, 导致只有左侧的列数必须等于右侧的行数的矩阵才能进行点击运算, 并且我们能推出规律
- 矩阵shape[x, y] • [y, z] ==> 答案矩阵shape[x, z]
- 内侧决定是否可以点积, 外侧决定答案矩阵的 shape
- 不满足交换率, A • B 不等于 B • A
如果由于矩阵对应行列数不同而造成无法进行点积, 我们就需要 reshape 或者 矩阵转置.
3. 矩阵转置(transpose)
矩阵的值没变, 但是行和列的位置互换

举例:
有一个矩阵存储的是三个人的身高, 体重, 年龄, 我们可以把数据以行的形式存储, 或者列的形式存储.
下面这两者互为转置

|

|
|---|
请注意: 如果以列的形式存储, 那么每行就包含特定特征的所有值.
如果我们需要处理一个人的所有特征, 或者处理所有人的单个特征, 上面两张图的作用就凸现出来了
我们存储数据的时候不一定要以行或者列存储, 重点是我们需要知道每个矩阵的数据情况, 确保知道哪些 行/ 列 需要进行计算, 仅在这些 行 / 列 不会造成干扰的情况下进行转置.
创建我们第一个神经网络ANN
ANN 是 Artificial Neural Network 的简写
有一个题目, 有四组二进制输入值, 和其对应的输出值, 输入值和输出值有某种联系, 如何找到这个联系, 由我们随意输入, 预测输出.
| input | input | input | output |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | ?????? |
要解决这个问题, 我们必须了解 感知器( Perceptron )
感知器
感知器最初是下面这样的.
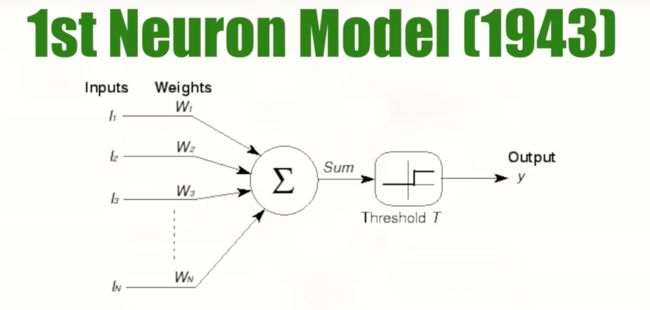
神经元接收二进制输入, 对输入求和, 如果结果大于某个阀值, 则输出 1. 否则输出 0 .
- 几年后, Frank Rosenblatt 在原有模型上做改进, 增加了学习机制, 称之为感知器(
Perceptron), 即单层前馈神经网络(Single Layer Feedforward Neural Network). 因为数据按照一个方向传递, 即向前传递, 所以叫前馈.
感知器对输入引进了
加权的思想, 给定某个包含输入输出的数据集, 感知器通过学习得到一个(将输入映射到输出的)函数. 即根据每一次输出, 逐步校正权重.

补充说明:
- 上面这个图指的是一层的情况, 如果是多层, 情况会有变化.
权重: 当数据被输入感知器, 它会分配给对应输入的权重相乘, 这些权重刚开始是随机值,当神经网络学习到什么样的输入数据会使得与目标值接近的时候, 网络会根据之前权重下分类的错误来调整权重. 换句话说, 这个关联的权重体现了对应数据的重要性.激活函数: 当输入给到节点,激活函数可以决定节点的输出, 常见的激活函数包括单位阶跃函数, 对数几率(Sigmoid函数), tanh, softmax, ReLU函数等.- 对于上面的问题, 我们知道在 Layer1 这一层里, A 代表着 [0, 0, 1]三个输入, G 代表可以将输入映射到输出的函数.
解决办法
import TensorFlow
typealias TensorFloat = Tensor
struct NeuralNetwork {
// 随机初始化权重, 原本范围在 0 <= n <= 1, 2n - 1 属于 [-1, 1]
var weights: TensorFloat = 2 * TensorFloat(randomUniform: [3, 1]) - 1
// 训练数据
mutating func train(training_inputData: TensorFloat, training_outputData: TensorFloat, epoch: Int)
{
for _ in 0.. TensorFloat {
// 权重就是通过这种方式来控制数据在神经网络间的流动
// 此函数将返回预测结果
return sigmoid(inputs • self.weights)
}
}
// sigmoid 的导数
// 描述了 sigmoid 曲线的梯度, 也就是变化率
func sigmoid_derivative (input: TensorFloat) -> TensorFloat {
return input * (1 - input)
}
func main()
{
// 初始化
var network = NeuralNetwork()
// 随机初始化权重
print("初始化权重: ", network.weights)
// 指定训练集
// 三个输入 一个输出
let training_inputData = TensorFloat([[0, 0, 1],
[1, 1, 1],
[1, 0, 1],
[0, 1, 1]])
let training_outputData = TensorFloat([[0, 1, 1, 0]]).transposed()
// 开始训练
network.train(training_inputData: training_inputData,
training_outputData: training_outputData, epoch: 10000)
print("当前权重: ", network.weights)
// 预测结果
print("预测数据[[1, 0, 0]] -> ?", network.predict(inputs: TensorFloat([[1, 1, 1]])))
}
上面就是解决问题的方法, 里面都有注释, 我不做赘述. 这里有一些思考,
按照程序运行的顺序
-
- 对于表格数据转化为数学语言, 我们可以用矩阵(二维张量)来存储这些值.
-
- 对于初始权重, 不一定是要在[-1, 1], 这样是为了方便测试, 不论用多大的值, 后面都会在反向传播的过程中更新.
-
- 在预测数据的方法里,
sigmoid(inputs • self.weights), 到底在干嘛?
- 在预测数据的方法里,
在前面我们介绍的感知器(单层前馈神经网络)的示意图

这个网络里, h是节点输入, f(h)是激活函数, y是节点输出. 注意, 这是单层网络
inputs • self.weights, 点积其实做的就是加权和的工作, 对矩阵不熟的同学在纸上画一画就明白了.sigmoid在这里是激活函数, 可以把数据转化为 [0, 1] 区间, 我们的目标值就是 0 / 1, 越靠近 0 或者 1 的就是我们的预测结果.- 为什么我们需要激活函数呢? 换句话说,
f(h) = h可以吗?
1. 要知道一点,f(h)可以是任意函数, 只要符合条件, 能预测出好的结果的都行.
2. 如果f(h) = h, 输入等于输出, 那么y=∑ᵢ wᵢxᵢ + b, 这跟线性回归模型是一样的, 但是狭义上的线性回归模型无法处理这种情况, 想了解细节可以看这个
3. 如果用 sigmoid 函数作为激活函数的结果, 其实跟对数几率回归是一样的, 在这个简单的网络中,跟通常的线性模型例如对数几率模型相比,神经网络还没有展现出任何优势.
-
-
error 有哪些方式决定?
-
标准一点, 这里应该叫 损失函数 (代价函数, Loss function), 一个合适的损失函数应该有两个要求:
- 损失函数是模型对数据拟合程度的反映, 损失函数的值越大, 表明拟合的越差.
- 损失函数在比较大时,它对应的梯度也要比较大,这样的话更新变量就可以更新的更快一点.
根据机器学习任务的不同, 损失函数分为回归和分类两种, 回归函数预测数量, 分类函数预测标签.

回归损失函数:
* MSE(Mean Square Erro): 均方误差, 平方损失(二次损失), L2损失, 最常用的回归损失函数.
* MAE(Mean Absolute Error): 平均绝对误差, L1损失.
* huber Loss: 平滑的平均绝对误差.
* Log-Cosh Loss: 比 L2 更平滑的损失函数
* Quantile Loss: 分位数损失
* 以上的所有损失函数的对比以及取舍我把链接放在文末, 这里不展开讲.
* 还有一些上面损失函数的变体, 比如 SSE (sum of the squared errors ), 误差平方和, 它和 MSE 有几分类似.- 损失函数的选择其实没什么必要条件, 合适就行, 业内也总结了很多经验, 在上面的简单例子中, 我们直接选择了 求差 , 来表示 error, 从结果来看还可以.
-
-
-
- 在这个例子中, 我们的目标是将 error 最小化, 找到最合适 weights, 那么怎么才能将 error 降下来呢?
-
- 每一个损失函数, 都有数学表达式, 我们都可以根据表达式画出图像. 比如 f(x) = x², 如何求极值呢? 用 梯度 (
gradient), 梯度也叫变化率, 或者斜率, 求梯度, 就是求导的过程. f˙(x) = 2x, 极值在 x = 0 可取. 此时梯度最小, f(x)最小.
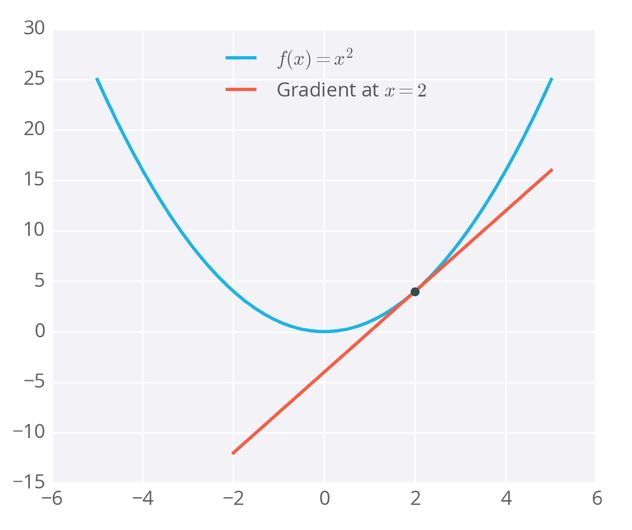
- 每一个损失函数, 都有数学表达式, 我们都可以根据表达式画出图像. 比如 f(x) = x², 如何求极值呢? 用 梯度 (
-
-
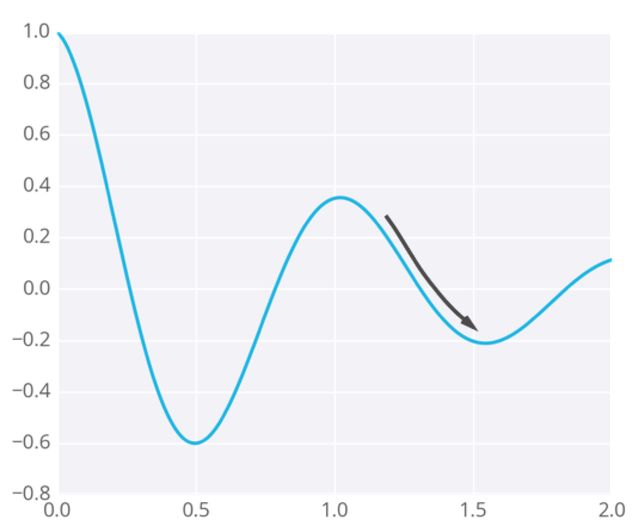
权重会走向梯度带它去的位置,它们有可能停留在误差小,但不是最小的地方。这个点被称作局部最低点, 或者鞍点. 为了解决这个问题, 我们可以用随机梯度下降( SGD ), 对于随机梯度下降, 批量梯度下降, 小批量梯度下降的链接我放在文末.
-
-
- 在这个例子中, 我们的目标是将 error 最小化, 找到最合适 weights, 那么怎么才能将 error 降下来呢?
-
- 理解梯度下降的过程.
在前面的感知器模型中, 我们知道
节点输入: 预测值:
误差值: (这是最容易想到的误差值表示, 并不一定要这么算, 在这里方便下面的理解和计算)
改进版:
(平方差是因为屏蔽正负的影响, 而且对于高误差影响更大, 低误差影响小, 乘以 是为了方便计算, 这里不影响最终结果)
全体数据误差和: , 这和 SSE 有点类似.
这里我们先计算单行数据误差. 以便于理解误差最小化的过程
E 随着 w 改变而变化, 从而最终影响整体误差.
这是单一权重误差函数的简化图形.我们的目标是当 E 最小时的, 取得 w 的值.
我们从某个随机权值开始, 逐步向误差最小值前进

我们会发现 梯度下降的越多, w 的变化率越大, 即
, 也叫步长
由上可得
( 是学习率, 用来控制下降中更新的步长), 这个结论很重要.
由于 是 权重 w 的函数
这里面运用了链式法则求偏导, 即
由于 y 是常数, 在求导的过程中上式可变为
这里单独讲一下
仅仅是 的自变量, 和其他的无关, 那么, 在求导的时候, 结果就是 , 对于 来说, 结果就是
继续演算
这里有一个关键的结论: 我们一般把 称作是 误差项 .
最终结论:
用梯度下降来更新权重的算法的一般描述:
- 权重步长设定为 0:
- 对训练数据中的每一条记录:
- 通过网络做正向传播,计算输出:
- 计算输出单元的误差项(error term)
- 更新权重步长:
- 更新权重:
- 重复 e 代(epoch)
-
再次回到我们的代码
let adjusment = training_inputData.transposed() • (error * sigmoid_derivative(input: output))-
(error * sigmoid_derivative(input: output))这就是误差项. - 这里的转置是为什么? 如果不转置, 将无法进行点积, 无法进行下一步计算, 转置的现实意义在于将训练数据中每一个输入单元的值与误差项相乘求和, 获得总的权重变化值.
-
对于这个简单的项目, 到这里就可以暂时告一段落, 我们通过这个项目, 了解了一个单层神经网络的创建过程.
补充说明:
多层感知器
通过增加中间层, 能让神经网络学习更加复杂的模式.

|

|
|---|
反向传播
在一个两层神经网络中, 包含隐藏层, 和输出层, 输入层不算在其中.
输出层误差是
隐藏层误差是
通过反向传播更新权重的算法一般概述:
-
把每一层权重更新的初始步长设置为 0
- 输入到隐藏层的权重更新是
- 隐藏层到输出层的权重更新是
-
对训练数据当中的每一个点
- 让它正向通过网络,计算输出
- 计算输出节点的误差梯度 , 这里 是输出节点的输入
- 误差传播到隐藏层
- 更新权重步长:
-
更新权重.
重复这个过程 e 代
下面我会做一个项目, 通过共享单车的使用数据, 来判断它的投放. 待更新
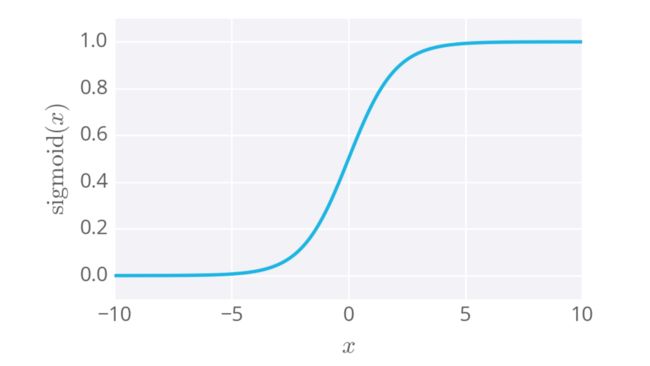
Sigmoid(对数几率函数)
|

Heaviside Step Function(单位阶跃函数)
|
|---|
参考:
[***]机器学习者都应该知道的五种损失函数!
[**]如何为模型选择合适的损失函数?
[*]深度学习中如何选好激活函数和损失函数?
[*]如何理解随机梯度下降(Stochastic gradient descent,SGD)?
[***]三种梯度下降的方式:批量梯度下降、小批量梯度下降、随机梯度下降
如何方便的在markdown中插入数学公式
在线latex数学公式