Cortex-M系列中断和异常(四)
文章目录
- 1 中断及异常的注意事项
- 1.1 中断及异常的优先级配置
- 1.2 中断与栈空间的关系
- 1.3 向量表重定向情况
- 1.4 软件中断
- 1.5 ARM架构及中断
- 2 函数调用与异常处理的过程
- 2.1 函数调用过程
- 2.2 异常处理过程
- 2.2.1 栈帧
- 2.2.2 EXC_RETURN
- 3 进入异常及返回异常流程
- 3.1 异常进入及压栈
- 3.2 异常返回及出栈
- 4 中断等待和异常处理优化
- 4.1 中断等待
- 4.2 多周期指令执行时的中断
- 4.3 末尾连锁
- 4.4 延迟到达
- 4.5 出栈抢占
- 4.6 惰性压栈
1 中断及异常的注意事项
1.1 中断及异常的优先级配置
如果没有设置中断的优先级分组,那么默认就用0,即优先级寄存器中0位用于子优先级。如果没有设置中断优先级,则中断优先级默认为0,即最高的优先级。可通过下面具体的函数来实现:
NVIC_SetPriorityGrouping(5);
NVIC_SetPriority(Timer0_IRQn, 0xC); // Timer0_IRQn是中断编号
NVIC_EnableIRQ(Timer0_IRQn);
1.2 中断与栈空间的关系
在处理模式中,中断的处理是要用主堆栈MSP的,如果存在大量的中断嵌套的话,就需要更大的栈空间。计算栈空间时应该考虑中断处理使用的栈以及每级栈帧使用的栈。
1.3 向量表重定向情况
向量表默认位于存储器的开头处(地址为0)。但是,有一些微处理器是具有boot loader的,而且在flash中代码开始执行前,boot loader可能已经将向量表重定向到了Flash存储器的开头。重定向向量表的同时,也可以更改向量表中的内容,具体代码如下:
#define HW32_REG(address) (*(volatile unsigned long*)(address))
void new_timer0_handler(void); // 新的Timer0的中断处理
unsigned int vect_addr;
// 假设需要被替换的中断为Timer_IRQn
vect_addr = SCB->VTOR + (((int)(Timer0_IRQn) + 16) << 2); // 获取Timer_IRQn在向量表中的地址,此地址 = 异常编号 * 4,Timer0_IRQn是中断编号因此需要+16
HW32_REG(vect_addr) = (unsigned int)new_timer0_handler;
1.4 软件中断
有的时候我们需要用软件来触发一个中断,这么做的原因是允许多任务环境中处在非特权状态的应用任务,可以访问一下需要在特权状态下才能执行的系统服务。如果要触发中断,即异常编号16以上的,可以用下面函数:
NVIC_SetPendingIRQ(Timer0_IRQn); // 将中断挂起
==注:==即便优先级高于当前的优先级,中断处理也会延迟几个时钟周期。若要保证触发中断后,马上执行中断,代码不能按照原始路局往下走,需要加上存储器屏障指令,具体代码如下:
NVIC_SetPendingIRQ(Timer0_IRQn);
_DSB();
_ISB();
1.5 ARM架构及中断
Cortex-M3和Cortex-M4用的是ARMv7-M架构,Cortex-M0和Cortex-M0+用的是ARMv6-M架构。具体的差别如下表:

2 函数调用与异常处理的过程
由C语言实现的函数调用或异常处理的根本过程就是操作R0R15、PSR、浮点相关(S0S31、FPSCR)等寄存器。用于ARM架构的C编译器遵循ARM的一个名为AAPCS的规范。根据这份标准,C函数可以修改R0R3、R12、R14(LR)以及PSR。如果想要使用R4R11,需要将这些寄存器保存在栈空间中,并且在函数结束前将他们恢复。
2.1 函数调用过程
R0~R3、R12、R14(LR)以及PSR被称为“调用者要存寄存器”,如果函数调用后还需要使用这些寄存器的数据,在进行调用前,调用子程序的程序代码需要将这些寄存器内容保存到栈中。如果函数调用后不需要这些寄存器的值,调用者就不需要保存这些寄存器。
R4~R11称为“被调用者要保存的寄存器”, 被调用的子程序或函数需要确保这些寄存器在函数调用结束时不会发生变化(与进入函数时候相同)。这些寄存器在被调用的函数执行时可能发生变化,因此要在函数进入是保存,在函数退出时恢复,以保证调用完函数之后,调用者可以继续的执行。
若Cortex-M处理器具有浮点单元,则浮点单元中的寄存器也有类似的需求:
- S0~S15为“调用者需要保存的寄存器”
- S16~S31为“被调用者需要保存的寄存器”
一般来说,函数调用将R0~R3作为输入参数,R0则用作返回结果。若返回值为64位,则R1也会用作返回结果。函数调用过程寄存器的保存恢复都是硬件自动执行的,不需要软件来参与。


2.2 异常处理过程
异常处理时,异常机制需要在异常入口处自动保存R0~R3、R12、R14(LR)以及PSR,并在退出时将他们恢复,这些都是由处理器硬件控制。这样,当返回到被中断的程序时,所有寄存器的数值都会和进入中断时相同。另外,与普通的函数调用不同,返回地址PC的数值并没有保存在LR中,(异常机制在进入异常时将EXC_RETURN代码放入LR中,该数值将会在异常返回时用到),因此异常流程也需要将返回地址保存。
2.2.1 栈帧
在异常入口处被压入栈空间的数据块为栈帧。对于Cortex-M3或不具备浮点单元的Cortex-M4处理器,栈帧都是8字大小的,对于具有浮点单元的Cortex-M4,栈帧则可能是8或26个字。
AAPCS的另一个要求为,栈指针的数值在函数入口和出口处应该是双字对齐(即指针地址一定是双数)。因此,若在中断产生时栈帧为未对齐到双字地址上,Cortex-M3和Cortex-M4处理器会自动插入一个字。压栈的xPSR中的第9位表示栈指针的数值是否调整过。下面介绍几种异常的栈帧。
- 不需要或禁止双字栈对齐时,无浮点单元处理器的异常栈帧:

- 需要或使能双字栈对齐时,无浮点单元处理器的异常栈帧:

- 具有浮点单元的上下文的栈帧格式:

通过系统控制块(SCB)中配置控制寄存器(CCR, 0xE000ED14)的一个控制位也可以使能双字栈对齐,具体代码如下:
SCB->CCR |= SCB_CCR_STKALIGN_Msk; // 设置CCR中的SKALIGN位(第9位)
2.2.2 EXC_RETURN
处理器进入异常处理或中断服务程序(ISR)时,链接寄存器(LR)的数值会被更新为EXC_RETURN数值。 当利用BX, POP或存储器加载指令(LDR或LDM)被加载到程序寄存器中时,该书中用于触发异常返回机制。EXC_RETURN的编码格式,在地址区间0xF0000000~0xFFFFFFFF中是无法执行中断返回的。不过,由于系统空间中的地址区间已经被架构定义为不可执行的,因此不会带来什么问题。下面是EXC_RETURN各个部分的具体含义:

3 进入异常及返回异常流程
3.1 异常进入及压栈
当异常产生的时候,处理器要保存现场,把ARM的通用寄存器进行保存,即组织栈帧然后压栈。具体过程如下:

Cortex-M3和Cortex-M4处理器具有多个总线接口如6.2,在压栈操作的同时(用系统总线),处理器还可以取向量和取指。如图压栈和取向量通过两条总线在同时进行,这样由于压栈操作可以和flash存储器访问同时进行,哈弗总线架构可以降低中断等待时间。若向量表在SRAM或异常也位于SRAM中,中断等待时间会稍微增加,因为取向量和压栈会用到同一个系统总线。

压栈期间的压栈顺序和栈帧中的顺序是不一样的,Cortex-M3会在其他寄存器前先将PC和xPSR压栈,这样在取向量时会尽快更新PC。具体的压栈顺序如下:

压栈操作可以使用主栈(MSP)也可以使用进程栈(PSP)。如果处理器运行在线程模式且CONTROL的bit0=0,则使用主栈MSP。

如果处理器运行在线程模式且CONTROL的bit0=1,则压栈操作使用进程栈PSP。在进入处理模式后,处理器必须使用MSP,即所有嵌套中断的压栈操作执行时都使用主栈MSP。
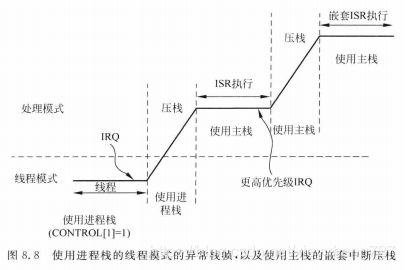
3.2 异常返回及出栈
在异常处理结束时,异常入口处生成的EXC_RETURN数值的第2位用于确定提取栈帧时所用的栈指针,如果为0则代表之前压栈的是主栈MSP,1则代表之前压栈的是进程栈PSP。


每次出栈结束时,处理器还会检查出栈xPSR数值的第9位,并且若压栈时插入了额外的空间,出栈时就要将其去除。具体流程如下:

为了降低出栈所需的时间,处理器会首先取出返回地址(压栈的PC),因此取指可以和剩下的出栈操作同时进行。
4 中断等待和异常处理优化
此章会介绍不同场景下的专业术语,这些场景是可以被优化的。
4.1 中断等待
中断等待表示从中断请求开始到中断处理开始中间的时间。对于Cortex-M3和Cortex-M4处理器,如果中断0等待,而且假定系统设计允许取向量和压栈同时执行,则中断等待为12个时钟周期。执行流程的持续时间还要看存储器的访问速度。除了存储器设备过外设产生的等待状态外,其他情况也可能加大中断等待时间;
- 处理器正在处理另外一个相同或更高优先级的异常。
- 调试器访问存储器系统。
- 处理器正在执行非对齐传输。
- 处理器正在执行对位段别名的写操作。
4.2 多周期指令执行时的中断
有些指令需要执行多个时钟周期,如果在处理器执行多周期指令(如整数除法)时产生了中断请求,该指令可能被丢弃且在中断处理结束后重新执行。这种设计还适用于加载双字(LDRD)和存储双字(STRD)指令。
4.3 末尾连锁
若某个异常产生时处理器正在处理另一个具有相同或更高优先级的异常,该异常会进入挂起状态。在处理器执行完当前的异常处理后,他可以继续执行挂起的异常和中断请求。这个紧接着执行中断的过程不会重复的压栈出栈,这样就大大的节约了时间,对于无等待状态的存储器系统,末尾连锁的中断等待时间仅为6个时钟周期。末尾连锁优化还给处理器带来了更佳的能耗效率,这是因为栈存储器访问的总数少了,而每次存储器传输都会消耗能量。末尾连锁详细过程如下图:

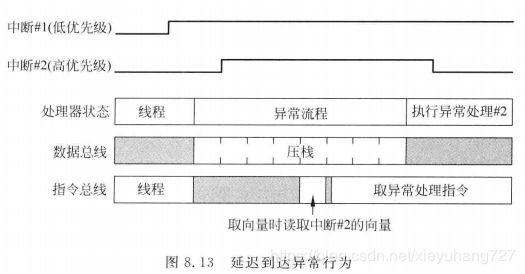
4.4 延迟到达
当异常产生时,处理器会接受异常请求并开始压栈操作。若在压栈操作期间产生了另外一个更高优先级的异常,则更高优先级的后来的异常会首先得到服务。具体过程如下图:
4.5 出栈抢占
若某个异常请求在另一个刚完成的异常处理出栈期间产生,处理器会舍弃出栈操作且开始取向量以及下一个异常服务的指令,该优化被称作出栈抢占。具体过程如下:

4.6 惰性压栈
若异常处理不需要任何浮点运算,浮点单元寄存器在异常处理期间会保持不变,而且不会再异常退出时恢复。如果异常处理需要浮点运算,处理器检测到冲突后会停止处理器,将浮点寄存器存到预留栈空间并清除LSPACT,接下来异常处理会继续执行。这样浮点单元寄存器只会在必要时压栈。惰性压栈操作可能被打断,当在惰性压栈期间产生了中断请求,则惰性压栈操作会停止,取而代之的是普通压栈开始执行,由于触发了惰性压栈的浮点指令还没有执行,压入栈中的PC值会指向那条浮点指令。当中断服务结束时,异常会返回浮点指令,而且重新执行这条指令会再次触发惰性压栈操作。若当前执行上下文未使用浮点单元,则FPCA为0(CONTROL寄存器的第2位),且栈帧会使用较短的形式。