https://github.com/square/okio
Okhttp连接connectSocket:
/** Does all the work necessary to build a full HTTP or HTTPS connection on a raw socket. */
private void connectSocket(int connectTimeout, int readTimeout, Call call,
EventListener eventListener) throws IOException {
Proxy proxy = route.proxy();
Address address = route.address();
rawSocket = proxy.type() == Proxy.Type.DIRECT || proxy.type() == Proxy.Type.HTTP
? address.socketFactory().createSocket()
: new Socket(proxy);
eventListener.connectStart(call, route.socketAddress(), proxy);
rawSocket.setSoTimeout(readTimeout);
try {
Platform.get().connectSocket(rawSocket, route.socketAddress(), connectTimeout);
} catch (ConnectException e) {
ConnectException ce = new ConnectException("Failed to connect to " + route.socketAddress());
ce.initCause(e);
throw ce;
}
// The following try/catch block is a pseudo hacky way to get around a crash on Android 7.0
// More details:
// https://github.com/square/okhttp/issues/3245
// https://android-review.googlesource.com/#/c/271775/
try {
source = Okio.buffer(Okio.source(rawSocket));
sink = Okio.buffer(Okio.sink(rawSocket));
} catch (NullPointerException npe) {
if (NPE_THROW_WITH_NULL.equals(npe.getMessage())) {
throw new IOException(npe);
}
}
}
Okio is a library that complements java.io and java.nio to make it much easier to access, store, and process your data. It started as a component of OkHttp, the capable HTTP client included in Android. It's well-exercised and ready to solve new problems.
简言之:java.io,nio的补充,Okhttp的组件(做了socket支持),功能强大
https://github.com/square/okio/blob/master/README.md
可以通过readme进一步了解:
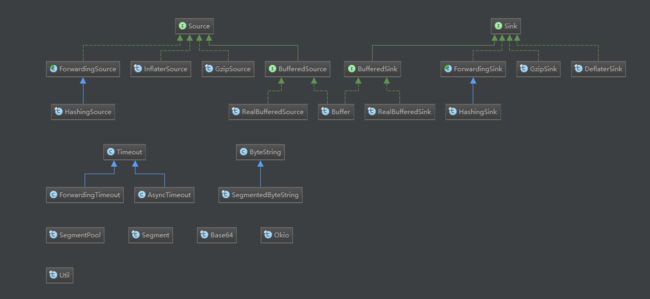
Okio的2个关键类:
① ByteString 不可变的字节序列类似String,封装了更多功能,支持base64,utf8
ByteString:
public class ByteString implements Serializable, Comparable {
final byte[] data;
transient int hashCode; // Lazily computed; 0 if unknown.
transient String utf8; // Lazily computed.
String(jdk1.7):
/**
* String a = "sss"; a 指向 value[] 指向 堆内存"sss"
*/
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
这里具体使用就不看了,我们看下另一个重要的类,
② Buffer 可变的字节序列,就像ArrayList,,数据读写都是从头到尾,并且buffer的字符位置、大小、容量会自己调整。
Okio 和 java.io的区别
java.io设计的一个优雅部分是如何将流分层以进行加密和压缩等转换。okio通过source和sink分别做读写分层,接口还可以向下扩展RealBufferedSink--RealBufferedSource 、HashingSink--GzipSource、GzipSink--GzipSource等
Source:
public interface Source extends Closeable {
/**
* Removes at least 1, and up to {@code byteCount} bytes from this and appends
* them to {@code sink}. Returns the number of bytes read, or -1 if this
* source is exhausted.
*/
long read(Buffer sink, long byteCount) throws IOException;
/** Returns the timeout for this source. */
Timeout timeout();
/**
* Closes this source and releases the resources held by this source. It is an
* error to read a closed source. It is safe to close a source more than once.
*/
@Override void close() throws IOException;
}
Sink:
public interface Sink extends Closeable, Flushable {
/** Removes {@code byteCount} bytes from {@code source} and appends them to this. */
void write(Buffer source, long byteCount) throws IOException;
/** Pushes all buffered bytes to their final destination. */
@Override void flush() throws IOException;
/** Returns the timeout for this sink. */
Timeout timeout();
/**
* Pushes all buffered bytes to their final destination and releases the
* resources held by this sink. It is an error to write a closed sink. It is
* safe to close a sink more than once.
*/
@Override void close() throws IOException;
}
可以看到Buffer是和读写io操作息息相关的
Buffer:
结构图:
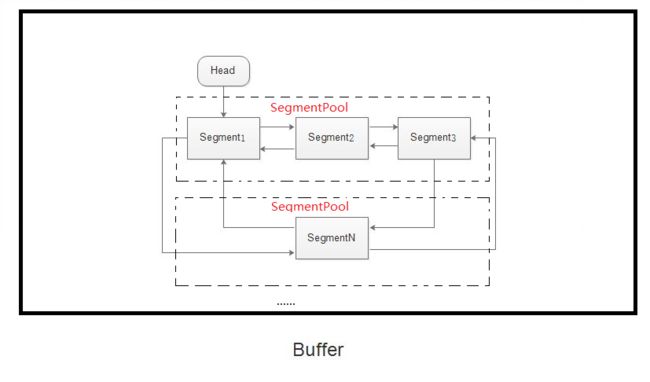
Buffer的实现,是通过一个循环双向链表来实现的。每一个链表元素是一个Segment。每一个Segment里有数据,每个Segment是有大小限制的,每8个Segment放在一个SegmentPool里,SegmentPool在Buffer里,Buffer封装了对数据的读写操作,通过SegmentPool控制Segment,take获取head,然后通过Segment的方法链接下一个Segment并填入byte数据,当Segment里的数据量太少,会通过Segment的compact方法将Segment的pop方法和SegmentPool的recycle方法回收。
① Buffer一共实现了三个接口,读,写,以及clone。
public final class Buffer implements BufferedSource, BufferedSink, Cloneable {
② Buffer采用的是深拷贝的方式:clone过程实现了Segment中没实现的闭环
result.head.pre = result.head.next = result.head;
public Buffer clone(){
//返回新的一个内存地址而不是this
Buffer result = new Buffer();
if (size == 0){
return result;
}
result.head = new Segment(head);
result.head.pre = result.head.next = result.head;
for (Segment s = head.next ; s != head ; s = s.next){
result.head.pre.push(new Segment(s)); //这里选择的pre上push一个segment
}
result.size = size;
return result;
}
③ 创建了双向链表,clone也有实现
Segment writableSegment(int minimumCapacity) {
if (minimumCapacity < 1 || minimumCapacity > Segment.SIZE)
throw new IllegalArgumentException();
if (head == null) {
head = SegmentPool.take();
return head.next = head.pre = head;
}
//head 不为null 的情形
Segment tail = head.pre;
//如果tail会导致大于Segment的上限 或是owner为false 也就是不可写
if (tail.limit + minimumCapacity > Segment.SIZE || !tail.owner) {
tail = tail.push(SegmentPool.take()); //在tail的后面插入一个空的segment
}
return tail;
}
④ 实现BufferedSource, BufferedSink接口读写的精妙表达这里就省略,大家可以自己深入研究下,提高基本功
下面我们看
Segment:
① 最大byte - 8K
② Segment next 和 Segment prev;保存前后Segment对象引用,形成双向链接
③ shared owner 是否共享数据
④ pop push split compact writeTo
final class Segment {
/** The size of all segments in bytes. */
static final int SIZE = 8192;
/** Segments will be shared when doing so avoids {@code arraycopy()} of this many bytes. */
static final int SHARE_MINIMUM = 1024;
final byte[] data;
/** The next byte of application data byte to read in this segment. */
int pos;
/** The first byte of available data ready to be written to. */
int limit;
/** True if other segments or byte strings use the same byte array. */
boolean shared;
/** True if this segment owns the byte array and can append to it, extending {@code limit}. */
boolean owner;
/** Next segment in a linked or circularly-linked list. */
Segment next;
/** Previous segment in a circularly-linked list. */
Segment prev;
Segment() {
this.data = new byte[SIZE];
this.owner = true;
this.shared = false;
}
Segment(Segment shareFrom) {
this(shareFrom.data, shareFrom.pos, shareFrom.limit);
shareFrom.shared = true;
}
Segment(byte[] data, int pos, int limit) {
this.data = data;
this.pos = pos;
this.limit = limit;
this.owner = false;
this.shared = true;
}
/**链接前后Segment,自己前后引用置空,脱离双向链表
* Removes this segment of a circularly-linked list and returns its successor.
* Returns null if the list is now empty.
*/
public @Nullable Segment pop() {
Segment result = next != this ? next : null;
prev.next = next;
next.prev = prev;
next = null;
prev = null;
return result;
}
/**当前和下一个之间插入一个Segment并返回
* Appends {@code segment} after this segment in the circularly-linked list.
* Returns the pushed segment.
*/
public Segment push(Segment segment) {
segment.prev = this;
segment.next = next;
next.prev = segment;
next = segment;
return segment;
}
/**
* Splits this head of a circularly-linked list into two segments. The first
* segment contains the data in {@code [pos..pos+byteCount)}. The second
* segment contains the data in {@code [pos+byteCount..limit)}. This can be
* useful when moving partial segments from one buffer to another.
*
* Returns the new head of the circularly-linked list.
*/
public Segment split(int byteCount) {
if (byteCount <= 0 || byteCount > limit - pos) throw new IllegalArgumentException();
Segment prefix;
// We have two competing performance goals:
// - Avoid copying data. We accomplish this by sharing segments.
// - Avoid short shared segments. These are bad for performance because they are readonly and
// may lead to long chains of short segments.
// To balance these goals we only share segments when the copy will be large.
if (byteCount >= SHARE_MINIMUM) {
prefix = new Segment(this);
} else {
prefix = SegmentPool.take();
System.arraycopy(data, pos, prefix.data, 0, byteCount);
}
prefix.limit = prefix.pos + byteCount;
pos += byteCount;
prev.push(prefix);
return prefix;
}
/**压缩机制:数据过少就会压缩
* Call this when the tail and its predecessor may both be less than half
* full. This will copy data so that segments can be recycled.
*/
public void compact() {
if (prev == this) throw new IllegalStateException();
if (!prev.owner) return; // Cannot compact: prev isn't writable.
int byteCount = limit - pos;
int availableByteCount = SIZE - prev.limit + (prev.shared ? 0 : prev.pos);
if (byteCount > availableByteCount) return; // Cannot compact: not enough writable space.
writeTo(prev, byteCount);
pop();
SegmentPool.recycle(this);
}
/**写数据: owner和Shared主要是用来判断如果是共享就无法写,以免污染数据,会抛出异常。当然,
*如果要写的字节大小加上原来的字节数大于单个segment的最大值也是会抛出异常,也存在一种情况就是
*虽然尾节点索引和写入字节大小加起来超过,但是由于前面的pos索引可能因为read方法取出数据,pos索
*引后移这样导致可以容纳数据,这时就先执行移动操作,使用系统的 System.arraycopy 方法来移动到pos
*为0的状态,更改pos和limit索引后再在尾部写入byteCount数的数据,写完之后实际上原segment读了
*byteCount的数据,所以pos需要后移这么多
*Moves {@code byteCount} bytes from this segment to {@code sink}.
*/
public void writeTo(Segment sink, int byteCount) {
if (!sink.owner) throw new IllegalArgumentException();
if (sink.limit + byteCount > SIZE) {
// We can't fit byteCount bytes at the sink's current position. Shift sink first.
if (sink.shared) throw new IllegalArgumentException();
if (sink.limit + byteCount - sink.pos > SIZE) throw new IllegalArgumentException();
System.arraycopy(sink.data, sink.pos, sink.data, 0, sink.limit - sink.pos);
sink.limit -= sink.pos;
sink.pos = 0;
}
System.arraycopy(data, pos, sink.data, sink.limit, byteCount);
sink.limit += byteCount;
pos += byteCount;
}
SegmentPool:
① 为了防止多线程同时操作造成数据的错乱,这里加了锁
② 64K也就是8个满完全充满byte的Segment
③ 这里的next命名虽然是next,但是实际上是整个对象池的头,但是next为空,表示池子为空,直接返回一个空对象,否则从里面拿出next,并将next的下一个节点赋为next
final class SegmentPool {
/** The maximum number of bytes to pool. */
// TODO: Is 64 KiB a good maximum size? Do we ever have that many idle segments?
static final long MAX_SIZE = 64 * 1024; // 64 KiB.
/** Singly-linked list of segments. */
static @Nullable Segment next;
/** Total bytes in this pool. */
static long byteCount;
private SegmentPool() {
}
static Segment take() {
synchronized (SegmentPool.class) {
if (next != null) {
Segment result = next;
next = result.next;
result.next = null;
byteCount -= Segment.SIZE;
return result;
}
}
return new Segment(); // Pool is empty. Don't zero-fill while holding a lock.
}
static void recycle(Segment segment) {
if (segment.next != null || segment.prev != null) throw new IllegalArgumentException();
if (segment.shared) return; // This segment cannot be recycled.
synchronized (SegmentPool.class) {
if (byteCount + Segment.SIZE > MAX_SIZE) return; // Pool is full.
byteCount += Segment.SIZE;
segment.next = next;
segment.pos = segment.limit = 0;
next = segment;
}
}
}
问题:如何和socket关联?为什么socket读写要用okio?
继续读readme:
和socket关联:
public static Sink sink(Socket socket) throws IOException {
if (socket == null) throw new IllegalArgumentException("socket == null");
AsyncTimeout timeout = timeout(socket);
Sink sink = sink(socket.getOutputStream(), timeout);
return timeout.sink(sink);
}
① BufferedSink和BufferedSource读写。
② Sinks buffer以最大限度地减少I / O操作,为了节省内存 Okio会在缓冲数据超过某个阈值时自动刷新。
③ Okio建立java.io.Socket连接。创建您的套接字作为服务器或客户端,然后用于Okio.source(Socket)读取和Okio.sink(Socket) 写入。这些API也适用于SSLSocket。
④ 通过调用从任何线程中取消套接字Socket.close(); 这将导致它的源和汇立即失败IOException。您也可以为所有套接字操作配置超时。您不需要引用套接字来调整超时:Source并Sink直接显示超时。即使流是经过修饰的,该API也可以工作。

很强大!
如何实现超时呢?
Okio的超时机制让IO不会因为异常阻塞在某个未知的错误上,Okio的基础超时机制是采用的同步超时
private static Sink sink(final OutputStream out , final Timeout timeout){
if (out == null) throw new IllegalArgumentException("out == null");
if (timeout == null) throw new IllegalArgumentException("timeout == null");
return new Sink() {
....
@Override
public void write(Buffer source, long byteCount) throws IOException {
Util.checkOffsetAndCount(source.size,0,byteCount);
while (byteCount > 0 ){
timeout.throwIfReached();
Segment head = source.head;
int toCopy = (int) Math.min(byteCount , head.limit - head.pos);
out.write(head.data,head.pos,toCopy);
byteCount -= toCopy;
source.size += toCopy;
head.pos += toCopy;
...
}
}
};
}
可以发现:
write方法中实际上有一个while循环,在每个开始写的时候就调用了 timeout.throwIfReached() 方法,这个方法里面去判断的时间是否超时,这很明显是一个同步超时机制,Source的read也一样。
public void throwIfReached() throws InterruptedIOException {
if (Thread.interrupted()){
throw new InterruptedIOException("thread interrupted");
}
if (hasDeadline && deadlineNanoTime - System.nanoTime() < 0){
throw new InterruptedIOException("deadline reached");
}
}
看socket那部分我们还发现
AsyncTimeout timeout = timeout(socket);
Sink sink = sink(socket.getOutputStream(), timeout);
AsyncTimeout 也就是 核心了
① enter方法,相当于注册了这个AsyncTimeout (配对的实现exit方法,这个exit有一个返回值会表明超时是否触发,请注意这个timeout是异步的,可能会在exit后才调用);判断以及设置inQueue的状态。
public final void enter() {
if (inQueue) throw new IllegalStateException("Unbalanced enter/exit");
long timeoutNanos = timeoutNanos();
boolean hasDeadline = hasDeadline();
if (timeoutNanos == 0 && !hasDeadline) {
return; // No timeout and no deadline? Don't bother with the queue.
}
inQueue = true;
scheduleTimeout(this, timeoutNanos, hasDeadline);
}
② 调用 scheduleTimeout 方法来加入到链表中// Insert the node in sorted order.
private static synchronized void scheduleTimeout(
AsyncTimeout node, long timeoutNanos, boolean hasDeadline) {
// Start the watchdog thread and create the head node when the first timeout is scheduled.
if (head == null) {
head = new AsyncTimeout();
new Watchdog().start();
}
long now = System.nanoTime();
if (timeoutNanos != 0 && hasDeadline) {
// Compute the earliest event; either timeout or deadline. Because nanoTime can wrap around,
// Math.min() is undefined for absolute values, but meaningful for relative ones.
node.timeoutAt = now + Math.min(timeoutNanos, node.deadlineNanoTime() - now);
} else if (timeoutNanos != 0) {
node.timeoutAt = now + timeoutNanos;
} else if (hasDeadline) {
node.timeoutAt = node.deadlineNanoTime();
} else {
throw new AssertionError();
}
// Insert the node in sorted order.
long remainingNanos = node.remainingNanos(now);
for (AsyncTimeout prev = head; true; prev = prev.next) {
if (prev.next == null || remainingNanos < prev.next.remainingNanos(now)) {
node.next = prev.next;
prev.next = node;
if (prev == head) {
AsyncTimeout.class.notify(); // Wake up the watchdog when inserting at the front.
}
break;
}
}
}
③ extends Thread
private static final class Watchdog extends Thread {
Watchdog() {
super("Okio Watchdog");
setDaemon(true);
}
public void run() {
while (true) {
try {
AsyncTimeout timedOut;
synchronized (AsyncTimeout.class) {
timedOut = awaitTimeout();
// Didn't find a node to interrupt. Try again.
if (timedOut == null) continue;
// The queue is completely empty. Let this thread exit and let another watchdog thread
// get created on the next call to scheduleTimeout().
if (timedOut == head) {
head = null;
return;
}
}
// Close the timed out node.
timedOut.timedOut();
} catch (InterruptedException ignored) {
}
}
}
}
awaitTimeout操作是判断是否超时的真正地方
④
/**
- Removes and returns the node at the head of the list, waiting for it to time out if necessary.
- This returns {@link #head} if there was no node at the head of the list when starting, and
- there continues to be no node after waiting {@code IDLE_TIMEOUT_NANOS}. It returns null if a
- new node was inserted while waiting. Otherwise this returns the node being waited on that has
- been removed.
*/
static @Nullable AsyncTimeout awaitTimeout() throws InterruptedException {
// Get the next eligible node.
AsyncTimeout node = head.next;
// The queue is empty. Wait until either something is enqueued or the idle timeout elapses.
if (node == null) {
long startNanos = System.nanoTime();
AsyncTimeout.class.wait(IDLE_TIMEOUT_MILLIS);
return head.next == null && (System.nanoTime() - startNanos) >= IDLE_TIMEOUT_NANOS
? head // The idle timeout elapsed.
: null; // The situation has changed.
}
long waitNanos = node.remainingNanos(System.nanoTime());
// The head of the queue hasn't timed out yet. Await that.
if (waitNanos > 0) {
// Waiting is made complicated by the fact that we work in nanoseconds,
// but the API wants (millis, nanos) in two arguments.
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
AsyncTimeout.class.wait(waitMillis, (int) waitNanos);
return null;
}
// The head of the queue has timed out. Remove it.
head.next = node.next;
node.next = null;
return node;
}
注释很详细了,这部分涉及wait,链表,加锁
remainingNanos 来判断预定的超时时间减去当前时间是否大于0,如果比0大就说明还没超时,于是wait剩余的时间,然后表示并没有超时,如果小于0,就会把这个从链表中移除
感谢:)非常感谢大家花时间,要结合源码需要细细阅读,
谢谢