需求
百亿级数据实时查询,数据有两列:电话MD5(rowkey CELLPHONE_MD5)、电话( CELLPHONE)
创建Hbase表
可以通过两种方式连接Hbase:phoenix 或者hbase shell
- phoenix可以提供类sql的方式进行hbase的操作,容易接受一些
- hbase shell 通过hbase相关命令操作,相对复杂
- phoenix提供相对格式化的输出,比较美观(例如执行查看所有表操作,phoneix输出的结果以table形式展现,而hbase shell通过字符串形式展现)。
需要注意的是,在phoenix中执行建表命令时会将小写的表名、字段名转换为大写,所以如果在程序中或者Hbase shell中使用相关表是需要注意大小写问题。
phoenix
linux console执行以下命令,进入phoenix:
[root@mmbps1 ~]# /opt/cloudera/parcels/CLABS_PHOENIX/bin/phoenix-sqlline.py zookeeper地址:2181:/hbase
hbase shell
linux console执行以下命令,进入hbase shell:
[root@mmbps1 ~]# hbase shell
命令对比
| 操作 | phoenix | hbase shell |
|---|---|---|
| 查看表结构 | !describe 表名 | describe '表名' |
| 查看表是否存在 | !table 表名 | exists '表名' |
| 列出所有表 | !tables | describe '表名' |
| 查看表结构 | !describe 表名 | list |
| 创建表 | CREATE TABLE IF NOT EXISTS cellphone_md5_info(cellphone_md5 varchar PRIMARY KEY ,列簇.cellphone varchar); | create 'cellphone_md5_info_test','cellphone_md5','cellphone' |
| 删除表 | drop table 表名 | disable '表名' 然后再 drop '表名' |
| 查询数据总量 | 当单表数据小于百万行,可以通过select count(1) from table;当单表数据过大,不宜在phoenix中执行,请在hbase shell中查询 | 当单表数据小于百万,可以通过在hbase shell中执行count命令统计:count '表名';当单表数据过大,通过开启mapreduce 任务进行统计:在linux shell中执行(注意不是hbase shell中): hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'CELLPHONE_MD5_INFO' |
hbase通过mapreduce统计表总量

spark-java插入hbase
pom.xml
通过maven-shade-plugin插件,让maven打jar包时包含导入的jar包,否则的话打jar包时不会将引用的jar包一并打包
4.0.0
com.spark.hbase
spark-to-hbase
1.0-SNAPSHOT
spark-to-hbase
spark存入HBASE
jar
2.6.0
1.2.0
org.apache.spark
spark-core_2.11
2.3.1
org.apache.hadoop
hadoop-client
2.6.0
org.apache.hbase
hbase-common
${hbase.version}
org.apache.hbase
hbase-client
${hbase.version}
org.apache.hbase
hbase-server
${hbase.version}
org.projectlombok
lombok
1.18.2
provided
com.alibaba
fastjson
1.2.3
org.apache.maven.plugins
maven-shade-plugin
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
${groupId}.com.bigdata.CellPhoneToHbase
false
org.apache.maven.plugins
maven-compiler-plugin
3.1
1.8
1.8
code
package com.bigdata;
import com.bigdata.common.utils.encrypt.Md5Encryption;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import org.apache.commons.lang.time.FastDateFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapred.TableOutputFormat;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class test {
private static final FastDateFormat ISO_DATE_FORMAT = FastDateFormat
.getInstance("yyyy-MM-dd HH:mm:ss");
private final static String CELLPHONE_TABLE_NAME = "CELLPHONE_MD5_INFO_TEST";
private final static String CELLPHONE_COLUMN_FAMILY = "PHONE_CF";
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setAppName("cellphone_info_to_hbase")
.setMaster("local[*]");
sparkConf.set("spark.sql.shuffle.partitions", "2");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
List list = Arrays
.asList("134", "135", "136", "137", "138", "139", "147", "150", "151", "152", "157", "158",
"159", "178", "182", "183", "184", "187", "188", "130", "131", "132", "155", "156",
"185", "186", "145", "176", "133", "153", "177", "180", "181", "189");
JavaRDD phoneRDD = jsc.parallelize(list);
phoneRDD.map(line -> {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "10.10.14.16");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set(TableOutputFormat.OUTPUT_TABLE, CELLPHONE_TABLE_NAME);
HBaseAdmin hBaseAdmin = new HBaseAdmin(conf);
if (hBaseAdmin.isTableAvailable(CELLPHONE_TABLE_NAME)) {
System.out.println("Table " + CELLPHONE_TABLE_NAME + " is available.");
} else {
throw new RuntimeException("Table " + CELLPHONE_TABLE_NAME + " is not available.");
}
HTable table = new HTable(conf, CELLPHONE_TABLE_NAME.getBytes());
int k = 0;
for (int i = 0; i < 1000; i++) {
List puts = new ArrayList<>();
//10w条数据发一次RPC请求到HBASE
for (int j = 0; j < 100000; j++) {
String phoneNum = line + String.format("%08d", k);
String phoneNumMd5 = Md5Encryption.encriptToUpper(phoneNum);
Put put = new Put(phoneNumMd5.getBytes());
//列簇、列、值
put.add(CELLPHONE_COLUMN_FAMILY.getBytes(), "CELLPHONE".getBytes(), phoneNum.getBytes());
puts.add(put);
k = k + 1;
}
table.put(puts);
System.out.println("插入hbase完毕10W条" + ISO_DATE_FORMAT.format(new Date()));
}
table.close();
hBaseAdmin.close();
return null;
}).collect();
System.out.println("插入hbase完毕:" + ISO_DATE_FORMAT.format(new Date()));
}
}
本地运行
首先在IDEA设置运行时最大内存:edit Configurations,在VM options选项中填入:
-Xmx1024m
运行查看日志输出:
.........
19/07/05 09:52:24 INFO ClientCnxn: Session establishment complete on server 10.10.14.16:2181, sessionid = 0x36867c728dce986, negotiated timeout = 90000
Table CELLPHONE_MD5_INFO_TEST is available.
Table CELLPHONE_MD5_INFO_TEST is available.
Table CELLPHONE_MD5_INFO_TEST is available.
Table CELLPHONE_MD5_INFO_TEST is available.
插入hbase完毕10W条2019-07-05 09:52:46
插入hbase完毕10W条2019-07-05 09:52:46
插入hbase完毕10W条2019-07-05 09:52:47
插入hbase完毕10W条2019-07-05 09:52:47
........
本地运行成功!
Hbase查询数据
注意:如果表是通过phoenix创建,则可以通过phoenix直接进行查询:
select * from CELLPHONE_MD5_INFO where CELLPHONE_MD5='xxxxxxx'
如果表是通过hbase shell命令创建,则在phoneix上无法直接查询,可以通过在phoenix上创建视图映射hbase表,然后进行查询。
或者在hbase shell上执行查询命令:
get 'CELLPHONE_MD5_INFO', 'xxxxxxx'

提交到spark集群
提交运行
将代码中本地运行模式注释
//.setMaster("local[*]")
maven clean package 打jar包后,上传到spark所在的任意一台机器中,通过spark submit命令提交到spark集群运行
spark2-submit --master yarn --deploy-mode cluster --driver-memory 10G --num-executors 4 --executor-memory 10G --executor-cores 10 --conf spark.dynamicAllocation.enabled=false --class com.bigdata.CellPhoneToHbase /home/xulu/spark-to-hbase-1.0-SNAPSHOT.jar
通过上面的提交命令,我们设置共开启4个线程,每个线程使用spark集群10个核心计算,控制台输出: 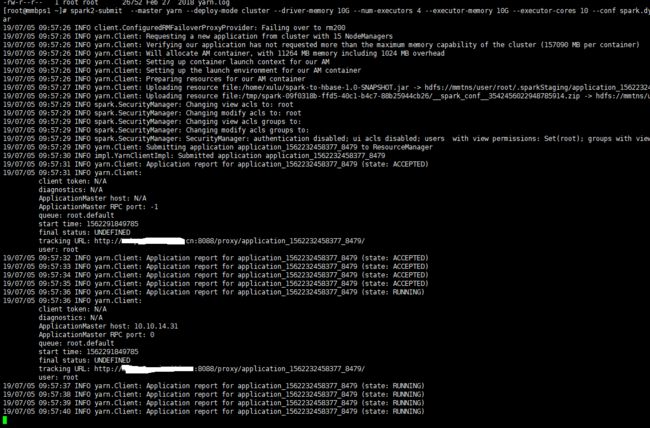
通过yarn查看运行情况及日志
通过上面控制台输出拿到application_id后,我们可以通过cloudera Manager查看运行情况以及日志:
cloudera manager管理界面 >> YARN >> 应用程序 >>输入:application_id=application_1562232458377_8563
点击ID,进入YARN管理界面,可以点击Tracking URL去spark界面上查看运行情况,或者查看YARN日志: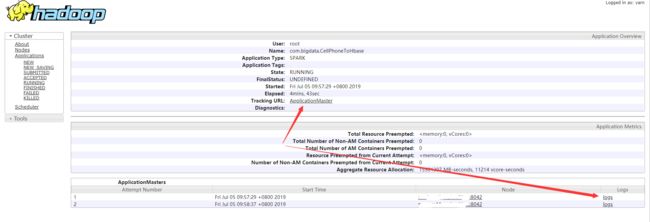
点击Tracking URL进入spark管理界面,可以看到任务运行情况以及资源分配;
通过分析代码可知我们的phoneRdd通过map算子生成了34个新的RDD,而我们提交任务时分配了40个线程(10 core * 4 executors),所以其中有6个是直接succeed状态。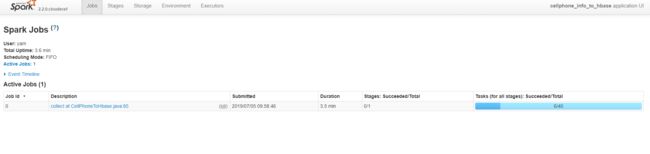
如果spark程序有异常,可能通过yarn界面看不到全部的日志,那么我们也可以使用命令来查询yarn日志:
yarn logs -applicationId spark提交时控制台输出的application_id
查看Hbase表占用的HDFS存储空间
如果需要查看hbase表占用的存储大小,可以使用hadoop命令进行查询:
hadoop fs -du -s -h /hbase/data/default/CELLPHONE_MD5_INFO

我们可以看到但副本占用178.2GB存储,三副本共占用534.5GB存储。
在hbase单表数据34亿条的情况下,使用hbase命令通过rokey查询数据都在200毫秒内返回结果:
hbase(main):001:0> get 'CELLPHONE_MD5_INFO', 'CA9CB6F6D6E78F93701B0FB9268BDDAF'
COLUMN CELL
PHONE_CF:CELLPHONE timestamp=1562145250209, value=18123644931
1 row(s) in 0.1640 seconds