最长和谐子序列
题目:和谐数组是指一个数组里元素的最大值和最小值之间的差别正好是1。现在,给定一个整数数组,你需要在所有可能的子序列中找到最长的和谐子序列的长度。
示例 1:
输入: [1,3,2,2,5,2,3,7]
输出: 5
原因: 最长的和谐数组是:[3,2,2,2,3].
说明: 输入的数组长度最大不超过20,000.
思路:第一思路,排序,遍历数组,map存储当前连续和谐数和最大连续和谐数。
这个题,看着简单错了n多次,我觉得我现在阅读理解有问题了,话不多说,用的map。直接上代码:
class Solution {
public int findLHS(int[] nums) {
if(nums.length==0) return 0;
Map map = new HashMap();
for(int i : nums){
if(map.containsKey(i)){
map.put(i,map.get(i)+1);
}else{
map.put(i,1);
}
}
int max = 0;
for (Integer key : map.keySet()) {
if(map.containsKey(key+1)){
max = Math.max(max,map.get(key)+map.get(key+1));
}
}
return max;
}
}
这期间主要的错误就是题意的理解,这个相差1 是不能多也不能少的。之前我以为1111这样的数组是4.后来才知道是0,因为没有相差1的。
好了这道题就到这了,怪我审题不清,题本身还是不难的。
又刷到几个sql题目。。都是来搞笑的吧,连多表联查都没有了,就是一个简单的sql。。
很好,刷了两道sql题转换了下心情,继续做题。
范围求和2
题目:给定一个初始元素全部为 0,大小为 m*n 的矩阵 M 以及在 M 上的一系列更新操作。操作用二维数组表示,其中的每个操作用一个含有两个正整数 a 和 b 的数组表示,含义是将所有符合 0 <= i < a 以及 0 <= j < b 的元素 M[i][j] 的值都增加 1。在执行给定的一系列操作后,你需要返回矩阵中含有最大整数的元素个数。
示例 1:
输入:
m = 3, n = 3
operations = [[2,2],[3,3]]
输出: 4
解释:
初始状态, M =
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]
执行完操作 [2,2] 后, M =
[[1, 1, 0],
[1, 1, 0],
[0, 0, 0]]
执行完操作 [3,3] 后, M =
[[2, 2, 1],
[2, 2, 1],
[1, 1, 1]]
M 中最大的整数是 2, 而且 M 中有4个值为2的元素。因此返回 4。
注意:
m 和 n 的范围是 [1,40000]。
a 的范围是 [1,m],b 的范围是 [1,n]。
操作数目不超过 10000。
思路:我用了几个测试案例试了一下,感觉这个题其实是求最小叠加面积的。每一个操作数组都是一个矩形面积,查看叠加层数最多的块数。我是这么理解的。而且有一点:这个必须从左上角开始加,所以只要知道最小的面积点或者说累加点就行了。接下来就要去看看代码怎么实现了。
比想的还要简单,刚刚灵机一动,果断成功,其实因为从左上角累加,所以只是知道最窄的长和宽就行了:
class Solution {
public int maxCount(int m, int n, int[][] ops) {
int min1 = m;
int min2 = n;
for(int i = 0;i至于这个性能也还不错了,1ms执行速度而已,感觉也没啥可优化的了,我去看看别人的代码:
class Solution {
public int maxCount(int m, int n, int[][] ops) {
int xMax = m;
int yMax = n;
for (int[] op : ops) {
if(op[0]感觉就是这个俩都是1增加的速度吧,反正这道题比较简单,所以先这样。
两个列表的最小索引总和
题目:假设Andy和Doris想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设总是存在一个答案。
示例 1:
输入:
["Shogun", "Tapioca Express", "Burger King", "KFC"]
["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"]
输出: ["Shogun"]
解释: 他们唯一共同喜爱的餐厅是“Shogun”。
示例 2:
输入:
["Shogun", "Tapioca Express", "Burger King", "KFC"]
["KFC", "Shogun", "Burger King"]
输出: ["Shogun"]
解释: 他们共同喜爱且具有最小索引和的餐厅是“Shogun”,它有最小的索引和1(0+1)。
提示:
两个列表的长度范围都在 [1, 1000]内。
两个列表中的字符串的长度将在[1,30]的范围内。
下标从0开始,到列表的长度减1。
两个列表都没有重复的元素。
思路:这个题有毛病吧,输出所有答案且不考虑顺序?什么意思?A,B B,A这种么属于两个?尤其是两个字符串数组的比较,除了暴力法我竟然只能想到map。算了,先试着做出来再说吧,就用map。
嗯,用了map勉强解了出来,性能也还能接受,超过百分之六十七的人。
其实逻辑还算简单,map是用来判断是否两个数组中都有,然后用map的value来算索引的和。如果有较小的存到list中,当有更小的出现clear list的同时,把新的较小的放进去。
class Solution {
public String[] findRestaurant(String[] list1, String[] list2) {
Map map = new HashMap();
int i = 0;
for(String s:list1){
map.put(s,i);
i++;
}
int res = 2000;
List list = new ArrayList();
int j = 0;
for(String str:list2){
if(map.containsKey(str) && res>=map.get(str)+j){
if(res>map.get(str)+j){
list.clear();
}
res = map.get(str)+j;
list.add(j);
}
j++;
if(j>res) break;
}
String[] result = new String[list.size()];
for(int k=0;k 感觉可优化点应该不少,我去看看题解。。优化点是判断list1,list2的长度。短的那个都存map,长的那个遍历就行。这样确实挺讨巧,可以省略很多无用功。我只加了个判断就性能超过百分之九十多的人了。
class Solution {
public String[] findRestaurant(String[] list1, String[] list2) {
if(list1.length>list2.length){
return findRestaurant(list2, list1);
}
Map map = new HashMap();
int i = 0;
for(String s:list1){
map.put(s,i);
i++;
}
int res = 2000;
List list = new ArrayList();
int j = 0;
for(String str:list2){
if(map.containsKey(str) && res>=map.get(str)+j){
if(res>map.get(str)+j){
list.clear();
}
res = map.get(str)+j;
list.add(j);
}
j++;
if(j>res) break;
}
String[] result = new String[list.size()];
for(int k=0;k 附上最终版代码,下一题。
种花问题
题目:假设你有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花卉不能种植在相邻的地块上,它们会争夺水源,两者都会死去。给定一个花坛(表示为一个数组包含0和1,其中0表示没种植花,1表示种植了花),和一个数 n 。能否在不打破种植规则的情况下种入 n 朵花?能则返回True,不能则返回False。
示例 1:
输入: flowerbed = [1,0,0,0,1], n = 1
输出: True
示例 2:
输入: flowerbed = [1,0,0,0,1], n = 2
输出: False
注意:
数组内已种好的花不会违反种植规则。
输入的数组长度范围为 [1, 20000]。
n 是非负整数,且不会超过输入数组的大小。
思路:这个乍一看挺简单,但是做一遍错一遍。本来我以为三个0能种一棵花,但是后来提交测试发现这个边上两个0就能种一颗,所以又分情况处理之类的,分来分去分的我晕了都,最后没忍住看了眼题解,人家大佬一个补0的思路让我惊为天人,然后就做出来了,直接上代码吧,这个只要能有思路其实很简单的
class Solution {
public boolean canPlaceFlowers(int[] flowerbed, int n) {
if(n==0) return true;
int max = 0;
//正常三个0中一个花,但是因为最开始如果连着俩0也能种一个花所以count初始值是1不是0
int count = 1;
for(int i=0;in) return true;
count=1;
}
}
if(count==2) max++;
return max>=n;
}
}
其实这个题真的是思路问题,题不难,但是我做了半个多小时得。下次遇到类似的我会记住哒!又学了一招。
根据二叉树创建字符串
题目:你需要采用前序遍历的方式,将一个二叉树转换成一个由括号和整数组成的字符串。空节点则用一对空括号 "()" 表示。而且你需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。

思路:如图所示吧,其实单纯数字来讲就是一个二叉树的遍历,这个不难,我个人感觉难的是括号好来括号去的。先说一下主思想就是递归。毕竟也算是二叉树的遍历了。只不过在递归中的输出值不是直接输出存数组list啥的,而且拼接字符串。我去试试吧
回来了,自我感觉贼好,性能贼打击人,
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public String tree2str(TreeNode t) {
String res = getStr(t);
return res.replace(")()",")");
}
public String getStr(TreeNode t){
if(t==null) return "";
if(t.left==null && t.right==null) return t.val+"";
return t.val + "("+getStr(t.left) + ")(" +getStr(t.right)+")";
}
}
这个replace是我测试了两三次才找到的规律,一来是是())被替换为)、后来一个测试案例根节点就没右节点,所以最后后面有一个(),我又开始判断结果的最后两个是不是()。最后才寻思过来,一共只有两个节点,如果
")()"长这样说明后面的节点是空,所以直接删除只剩下)就行了。
代码简单,而且逻辑清晰,但是!!!性能为什么这么低?因为我是字符串拼接么?换成变长字符串会更好么?emmm,,猜对了,排行第一的用的就是变长字符串sb。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private StringBuilder result=new StringBuilder();
public String tree2str(TreeNode t) {
if(t==null)
return "";
preOrderTraverse1(t);
return result.toString();
}
public void preOrderTraverse1(TreeNode root) {
result.append(root.val);
if(root.left!=null)
{
result.append("(");
preOrderTraverse1(root.left);
result.append(")");
}
else if(root.right!=null)
{
result.append("()");
}
if(root.right!=null)
{
result.append("(");
preOrderTraverse1(root.right);
result.append(")");
}
}
}
其实这个是应该想到的,我一开始写也考虑这个了,但是当时打算逻辑对了跑通了统一改,但是最后懒了,直接cv的人家的代码,哈哈。
合并二叉树
题目:给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
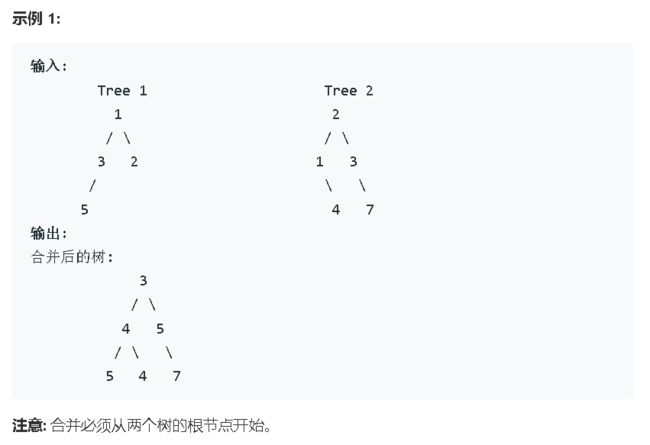
思路:感觉这道题又是以遍历二叉树为基础的,在这基础上的变种。主要就是值的累加,我去试试怎么做
这道题不难,所以直接上代码:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode mergeTrees(TreeNode t1, TreeNode t2) {
if(t2==null) return t1;
if(t1==null) return t2;
t1.val += t2.val;
t1.left = mergeTrees(t1.left,t2.left);
t1.right = mergeTrees(t1.right,t2.right);
return t1;
}
}
其实实在大佬思路下优化后的代码,我之前的判断繁重而复杂,判断1空不空2空不空, 1,2是不是都不空,或者其中一个空另一个不空反正好几个判断,但是看了人家的代码,只有两个,一个为空则直接接另一个,两个都空不过是return个null而已。很精巧的代码。另外一种不是在原树基础上改变的,而是新建一个树:
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode mergeTrees(TreeNode t1, TreeNode t2) {
if (t1 == null && t2 == null) {
return null;
}
// 先合并根节点
TreeNode t = new TreeNode((t1 == null ? 0 : t1.val) + (t2 == null ? 0 : t2.val));
// 再递归合并左右子树
t.left = mergeTrees(t1 == null ? null : t1.left, t2 == null ? null : t2.left);
t.right = mergeTrees(t1 == null ? null : t1.right, t2 == null ? null : t2.right);
return t;
}
}
这篇笔记就记录到这里,如果稍微帮到你了记得点个喜欢点个关注,也祝大家工作顺顺利利!