neo4j导入数据
**
可以参考我的数据格式 :具体数据下载位置:链接:https://pan.baidu.com/s/1A3HYXUzsrqzN3HXGpq2HMA 提取码:mfsr
**
1.导入数据:
将hudong_pedia.csv导入neo4j:开启neo4j,进入neo4j控制台。将hudong_pedia.csv放入neo4j安装目录下的/import目录。在控制台依次输入:
数据格式如下图:
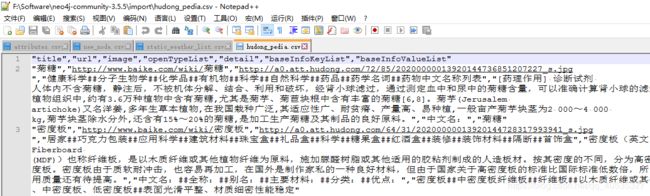
“title”,“url”,“image”,“openTypeList”,“detail”,“baseInfoKeyList”,“baseInfoValueList”
“菊糖”,“http://www.baike.com/wiki/菊糖”,"http://a0.att.hudong.com/72/85/20200000013920144736851207227_s.jpg
具体数据下载位置:链接:https://pan.baidu.com/s/1A3HYXUzsrqzN3HXGpq2HMA
提取码:mfsr
// 将hudong_pedia.csv 导入
LOAD CSV WITH HEADERS FROM “file:///hudong_pedia.csv” AS line
CREATE (p:HudongItem{title:line.title,image:line.image,detail:line.detail,url:line.url,openTypeList:line.openTypeList,baseInfoKeyList:line.baseInfoKeyList,baseInfoValueList:line.baseInfoValueList})
// 新增了hudong_pedia2.csv
LOAD CSV WITH HEADERS FROM “file:///hudong_pedia2.csv” AS line
CREATE (p:HudongItem{title:line.title,image:line.image,detail:line.detail,url:line.url,openTypeList:line.openTypeList,baseInfoKeyList:line.baseInfoKeyList,baseInfoValueList:line.baseInfoValueList})
// 创建索引
CREATE CONSTRAINT ON (c:HudongItem)
ASSERT c.title IS UNIQUE
以上两步的意思是,将hudong_pedia.csv导入neo4j作为结点,然后对titile属性添加UNIQUE(唯一约束/索引)
(如果导入的时候出现neo4j jvm内存溢出,可以在导入前,先把neo4j下的conf/neo4j.conf中的dbms.memory.heap.initial_size 和dbms.memory.heap.max_size调大点。导入完成后再把值改回去)
进入/wikidataSpider/wikidataProcessing中,将new_node.csv,wikidata_relation.csv,wikidata_relation2.csv三个文件放入neo4j的import文件夹中(运行relationDataProcessing.py可以得到这3个文件),然后分别运行
// 导入新的节点
LOAD CSV WITH HEADERS FROM “file:///new_node.csv” AS line
CREATE (:NewNode { title: line.title })
//添加索引
CREATE CONSTRAINT ON (c:NewNode)
ASSERT c.title IS UNIQUE
//导入hudongItem和新加入节点之间的关系
LOAD CSV WITH HEADERS FROM “file:///wikidata_relation2.csv” AS line
MATCH (entity1:HudongItem{title:line.HudongItem}) , (entity2:NewNode{title:line.NewNode})
CREATE (entity1)-[:RELATION { type: line.relation }]->(entity2)
LOAD CSV WITH HEADERS FROM “file:///wikidata_relation.csv” AS line
MATCH (entity1:HudongItem{title:line.HudongItem1}) , (entity2:HudongItem{title:line.HudongItem2})
CREATE (entity1)-[:RELATION { type: line.relation }]->(entity2)
导入实体属性(数据来源: 互动百科)
将attributes.csv放到neo4j的import目录下,然后执行
LOAD CSV WITH HEADERS FROM “file:///attributes.csv” AS line
MATCH (entity1:HudongItem{title:line.Entity}), (entity2:HudongItem{title:line.Attribute})
CREATE (entity1)-[:RELATION { type: line.AttributeName }]->(entity2);
LOAD CSV WITH HEADERS FROM “file:///attributes.csv” AS line
MATCH (entity1:HudongItem{title:line.Entity}), (entity2:NewNode{title:line.Attribute})
CREATE (entity1)-[:RELATION { type: line.AttributeName }]->(entity2);
LOAD CSV WITH HEADERS FROM “file:///attributes.csv” AS line
MATCH (entity1:NewNode{title:line.Entity}), (entity2:NewNode{title:line.Attribute})
CREATE (entity1)-[:RELATION { type: line.AttributeName }]->(entity2);
LOAD CSV WITH HEADERS FROM “file:///attributes.csv” AS line
MATCH (entity1:NewNode{title:line.Entity}), (entity2:HudongItem{title:line.Attribute})
CREATE (entity1)-[:RELATION { type: line.AttributeName }]->(entity2)
//我们建索引的时候带了label,因此只有使用label时才会使用索引,这里我们的实体有两个label,所以一共做2*2=4次。当然,可以建立全局索引,即对于不同的label使用同一个索引
导入气候名称:
将wikidataSpider/weatherData/static_weather_list.csv放在指定的位置(import文件夹下)
//导入节点
LOAD CSV WITH HEADERS FROM “file:///static_weather_list.csv” AS line
MERGE (:Weather { title: line.title })
//添加索引
CREATE CONSTRAINT ON (c:Weather)
ASSERT c.title IS UNIQUE
导入气候与植物的关系
将wikidataSpider/weatherData/weather_plant.csv放在指定的位置(import文件夹下)
//导入hudongItem和新加入节点之间的关系
LOAD CSV WITH HEADERS FROM “file:///weather_plant.csv” AS line
MATCH (entity1:Weather{title:line.Weather}) , (entity2:HudongItem{title:line.Plant})
CREATE (entity1)-[:Weather2Plant { type: line.relation }]->(entity2)
导入城市的气候
将city_weather.csv放在指定的位置(import 文件夹下)
(这步大约需要15分钟左右)
//导入城市对应的气候
LOAD CSV WITH HEADERS FROM “file:///city_weather.csv” AS line
MATCH (city{title:line.city}) , (weather{title:line.weather})
CREATE (city)-[:CityWeather { type: line.relation }]->(weather)
以上步骤是导入爬取到的关系
2.下载词向量模型:(如果只是为了运行项目,步骤2可以不做,预测结果已经离线处理好了)
http://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.zh.zip
将wiki.zh.bin放入 KNN_predict 目录 。
3.修改Neo4j用户
进入demo/Model/neo_models.py,修改第9行的neo4j账号密码,改成你自己的