Redis开发与运维的读书总结
第一章 为什么使用redis
- redis的使用场景
从redis可以做什么,不可用做什么引申出了redis的使用准则。从两个方面分析:数据规模和冷热数据。
数据规模来讲:虽然内存已经很便宜了,但是对于大数据规模的场景,redis还是不适用。并不是说不适合大数据生态,是不能承载大数据的存储,作为缓存来说依然是非常优秀的组件。
数据冷热来讲:肯定是适合作为热数据,应该redis的特点就是快速响应,快速存储。冷数据无此要求。
2 redis的版本
redis的发布版本号借鉴linux的版本号规则。单数是不稳定的版本,双数是稳定的版本。首先发布一个不稳定的版本,然后验证、测试等到稳定后发布双数版本。
3.生产版本中使用配置文件启动redis
第二章 redis有哪些功能
- redis提供了5 + 4中类型数据类型。string、hash、set、zset、list、geo、bitmap、hyperloglog、stream
string:raw、embstr
hash:ziplist、hashtable
set:intset、hashtable
zset:ziplist、skiplist
list:quicklist - 使用场景:
zset:排行榜
set:给用户打标签
list:栈、队列、有限集合、消息队列 - 持久化
persist可以取消键的过期时间。set也可以取消键的过期时间 - migrate
原子性的槽迁移。 - scan
渐进式的便利key。scan、hscan、zscan
Redis为什么快?
单线程价格、纯内存操作、io多路复用技术
内存操作的速度在100纳秒。 所以理论QPS上线是10w/s
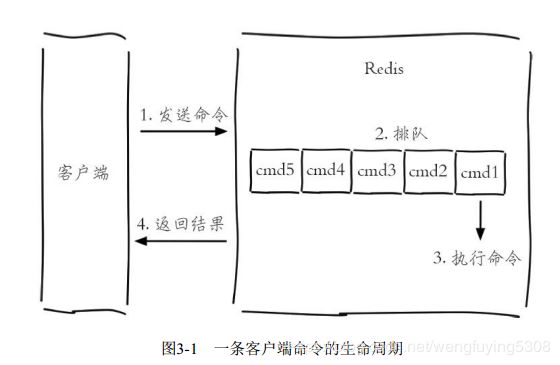
第三章 功能介绍
-
慢查询
redis的慢查询由两个参数控制:showlog-log-slower-than和slowlog-max-len
慢查询不包含命令网络传输和排队时间。只统计第三部执行命令的时间。
-
redis提供了三种使用的工具redis-cli redis-server redis-benchmark
-
pipeline是客户端把命令一起发送给服务端,服务器能够识别多个命令
-
redis的事务是满足ACID。持久性的定义依赖于刷盘策略。
事务不支持回滚。 语法错误的命令会导致整个事务不执行。 运行时错误的命令会被忽略,不会回滚整个事务。
lua脚本是非常强大的功能,定位是内嵌到其他程序中。 -
bitmap内部是字符串结构。bitcount、bitpos、setbit、bitop。
使用得当可以节省很多内存 -
hyperloglog常常用来计算uv。pfadd、pfcount、pfmerge
-
redis的pub/sub存在些许问题,stream可以说是pub/sub的超集。
当没有订阅者时,消息是直接丢弃的。消息没有持久化功能。 -
geo是使用的物理位置计算的数据结果。可以用来计算两点之间的距离。以及一个点范围内的其他点。
存在的问题是:有精度丢失问题,适合附近的人等社交使用场景。
第四章
- redis通信协议:RESP(REdis Serialization Protocol ,Redis序列化协议)。
| 符号 | 含义 |
|---|---|
| * | 命令+key+值的个数 |
| $ | 命令或者key或者值的长度 |
| \r\n | 命令或者key或者值独占一行 *开头也独占一行 |
| + | 状态回复 |
| - | 错误回复 |
| : | 整数回复 |
| $ | 字符串回复 |
| * | 多条字符串回复 |
- client信息
client list可以查看所有客户端的信息。其中qbuf、qbuf-free是客户端输入缓冲区的容量和使用情况
client缓冲区不受maxmemory的限制。
client输入缓冲区最大为1g,超过会被kill
obl、oll、omem分别是输出缓冲区的:固定缓冲区的长度,动态缓冲区的长度和使用的字节数
client-output-buffer-limit normal 20mb 10mb 120 限制输出缓冲区的大小
maxclients是设置最大连接数的配置
- 问题分析
redis内存使用陡增,主要有以下几种可能:
在iops很高的redis实例,有客户端在执行monitor命令。 输出缓冲区会慢。可以使用info client 查找最大的输入和输出缓冲区。发现是此问题后,可以使用client list 定位具体是哪个客户端。 使用redis kill $client_id 杀掉客户端实例。
客户端连接超时,可能的原因如下:
慢查询导致了连接超时。
第五章 持久化
- rdb持久化
rdb的优点:
- 二进制格式,节省存储空间。
- 恢复启动快
缺点: - 无法做到秒级保存数据。 如果实例宕机,数据恢复不完整。
- rdb版本不兼容
- fork创建进程的代价很高。需要复杂主线程的内存页空间
- iops很高时,cow机制需要维护大量内存页。
满足以下条件就会触发bgsave
save 900 1
save 600 100
save 10 10000
- aof持久化方法
启动aof持久化。文件存放目录由dir配置指定
appendonly yes
aof文件保存的命令范围:写命令,对redis内存中的数据有改动的命令。
aof文件有自己的文件缓冲区,redis会append到文件缓冲区,再根据aof文件的刷盘时机的配置appednfsync(always、everysec、no)会fsync到磁盘文件。
append操作会执行write和fsync函数。 write操作会触发延迟写。使用的是linux在内核提供页缓冲区来提供硬盘性能
aof重写机制
手动执行bgrewriteaof命令。可以考虑半夜执行脚本来完成
由以下配置决定什么时候自动触发aof重写。
第一个参数是:aof文件要达到多大触发重写
第二个参数是:aof文件比上一次大多少百分比触发重写
auto-aof-rewrite-min-size
auto-aof-rewrite-percentage
aof重写是基于redis当前内存中的数据重写。使用批量命令写入aof文件,所以才能减少文件的大小。
aof运行流程

redis启动流程
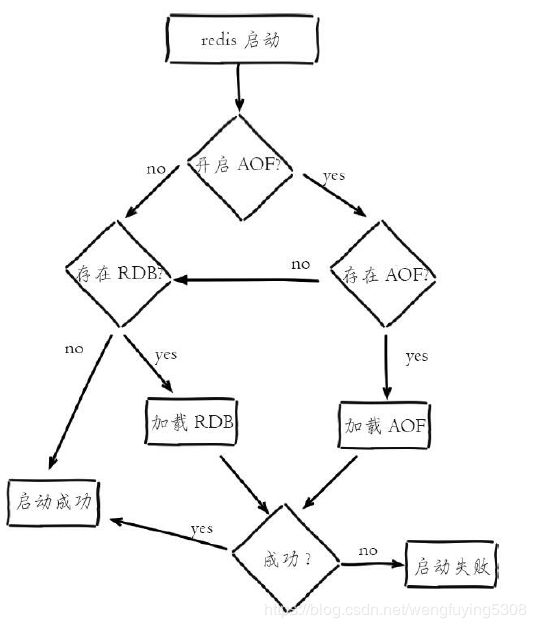
工具
可以使用redis-aof-check 会校验aof文件和修复文件(删除不完整的命令)。 redis-rdb-check只能校验rdb文件。
-
问题定位
fork子线程的耗时与redis的内存占用成线性比例。每gb消耗20毫秒,推荐10gb以内。可以使用info stats 查看lastest_fork_usesc -
子进程开销监控和优化
使用多核cpu,虽然redis是单进程架构
aof和rdb重写时需要占用内存消耗,具体可以查看执行过程的日志
机械磁盘不太行,推荐使用ssd
aof配置刷盘机制是everysec,每秒由刷盘线程负责把缓冲区的内容刷到磁盘。 但是如果磁盘资源繁忙,导致2秒还没有刷盘成功,那么redis主线程会阻塞。 可以在日志中找到redis主线程阻塞的情况。
刷盘流程

-
多实例部署
redis算是IO密集型应用。 因此适合单节点部署多实例,每个实例写入不同磁盘。 合理利用cpu资源。
也可关闭redis的自动bgrewriteaof机制。 增加外置程序。循环校验(aof_current_size - aof_base_size)/ aof_base_size的增长率。当满足条件后执行bgrewriteaof,并检查aof_rewrite_in_porgress保证单实例重写完成再调度其他实例。这样就可以减轻多实例部署的竞争磁盘资源的问题。
第六章 复制
-
redis主从复制
建立连接:slaveof ip port 写在配置文件中或者客户端执行或者在redis启动中带上–slaveof ip port
断开连接:slaveof no one
传输延迟:repl-disable-tcp-nodelay。 是否合并小的tcp包,适合跨机房复制时使用 -
部署拓扑结构
一主一从:架构简单,也满足了基本的数据安全性。
一主多从:适合读写分离的场景,使用从节点分担读的压力。
树状主从:避免多主节点的影响,让从节点也提供复制能力。尤其适合跨机房主从复制 -
原理
从节点依次向主节点发送ping、sync.主节点就会认为是从节点来进行复制了。会传输全量的rdb和aof缓冲区。此后每次写命令都会发送到从服务器。
psync:解决短时间从服务器断开后又要全量复制的问题。减少主节点的负担。使用复制缓冲区实现
- 复制导致的问题
数据延迟。写完后不能马上读。(此问题可以使用集群模式减缓)
读到过期数据。 配置主节点过期键删除策略。 定期删除。
主从节点的配置需要一样。
全量复制和单机复制导致的问题:使用树状结构可以减轻此问题。
第七章 阻塞
redis是单线程架构,因此尤其需要关注会影响主线程阻塞的点:
内在原因:不合理的使用api导致内存剧增和多次读写。 cpu饱和、持久化阻塞。
外在原因:cpu竞争、内存交换、网络问题。
主要是通过redis的监控平台、应用的错误日志以及慢日志分析来查找问题。 找到问题后再针对解决。
注重redis提供的节省内存的数据结构,已经切换节省内存的数据结构和标准数据结构的配置项。使用不当会导致算法复杂度的增加。
fork阻塞、aof刷盘阻塞、HugePage写操作阻塞
redis阻塞的官方check list 传送门
cpu绑定会导致子进程和父进程cpu竞争。
内存不足导致使用swap空间。
最大客户端连接数的配置maxclients。使用keep-alive是timeout保持监控的连接数
连接溢出:操作系统有进程(ulimit -n 65535 解除linux对tcp的文件句柄限制)和backlog队列溢出问题。
网络延迟
网络软中断
第八章 内存
redis的内存包括4部分:自身的内存使用,用户的数据,内存碎片,缓冲区
内存碎片的问题可以通过重启来解决。
使用maxmemory限制最大内存。这个值限制的是redis的使用内存量,不包括内存碎片
内存溢出控制策略:内存使用量达到maxmemory设置的上限后会触发相应的溢出控制策略
设置内存溢出控制策略
maxmemory-policy allkeys-lru
| 策略 | 解释 |
|---|---|
| noeviction | 不删除数据,拒绝写入 |
| volatile-lru | 过期键,从最长时间没使用的键删除 |
| volatile-random | 过期键,随机删除 |
| volatile-ttl | 过期键,快超时的先删除 |
| allkeys-random | 所有键,随机删除 |
| allkeys-lru | 所有键, 从最长时间没使用的键删除 |
减少内存占用的技巧:
使用高效的序列化工具:protostuff
string:控制字符串的长度在39字节内
使用共享对象池:0-9999范围内的整数对象
redis内部编码配置

使用ziplist存储大量的小对象可以有效减低内存的使用
第9章 哨兵
高可用架构==主从+sentinel哨兵
主观下线:在down-after-milliseconds没有有效回复
客观下线:当sentinel有quorum个节点都认为无响应后,认为客户下线。
故障转移过程:使用raft协议的领头选举算法,选举出主sentinel进行故障恢复。择优 择数据全 择最先启动选择一台从节点。执行slaveof no one,其他slave节点切换主节点。 通过客户端消息,记录旧master为新master的从节点
在有sentinel的集群情况下,应用客户端应该连接sentinel并指定哪一个集群。 客户端会订阅sentinel的topic,监听主从切换。
sentinel的三个定时监控任务:
- 每隔10秒,每个sentinel节点向主节点和从节点发送info命令获取最新的拓扑结构
- 每隔2秒,每个sentinel节点会向redis数据节点的
__sentinel__:hello频道发送sentinel节点对于主节点的判断以及当前sentinel节点的信息,并且订阅此频道,了解其他节点对主节点的判断 - 每隔1秒,每个sentinel节点会向主节点、从节点、其余sentinel节点发送一条ping命令做一次心跳检测,是否存活。
第10章 集群
- 数据分区
通常把整个数据集按哈希或者顺序分散到集群的各个节点
| 分区方式 | 特点 |
|---|---|
| 哈希 | 数据离散程度好、业务无关、无法顺序访问 |
| 顺序 | 数据容易倾斜、支持某个维度的顺序访问 |
哈希分区规则大概有以下几种
节点取余分区:这是比较简单的
一致性hash:添加或删除节点时只影响一部分数据
虚拟槽:添加节点或删除节点不影响数据。
redis节点之间通过gossip协议进行通信,保证最终一致性。
大概实现思路如下:
A节点根据规则选择一部分节点,发送自身的数据+已知节点/10的数据量。因此大集群光光集群之间的通信就可能达到40m/s的量
开发运维集群常见的问题:超大规模集群带宽消耗,pub/sub广播问题, 集群节点倾斜问题, 手动故障转移, 在线迁移数据
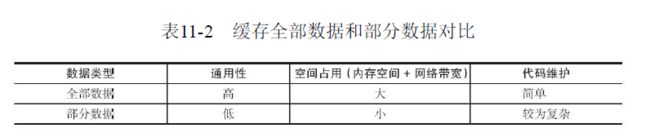
第11章 缓存设计
缓存使用的成本:
运维
数据不一致:存在这一定时间窗口的不一致性。
代码维护成本
缓存使用场景:
缓存开销大的计算结果
加速请求响应时间
推荐使用超时剔除和主动更新配合使用

推荐只查询mysql必需的数据和缓存必需的数据。并且在操作缓存时使用先操作数据库,再删除缓存的方法。(存在数据不一致问题)
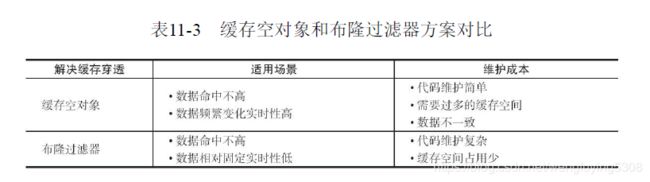
常见问题:
缓存穿透:使用缓存空对象解决或者布隆过滤器拦截
集群模式下,批量键的获取方式
- n次get
- 通过计算key所在的node,合并一个node的key,串行发起请求。
- 第二中情况改成并行发起请求。
- 通过只对key的一部分求hash,把多个key分配到了一个node中。

雪崩优化
问题介绍:由于缓存层宕机导致的存储层请求量暴增,造成存储层也级联宕机情况。
- 保证缓存层的高可用。主从架构或者集群模式
- 为后端限流降级。使用阿里的sentinel等工具降级存储层
热点key重建优化
问题介绍:缓存使用往往是会加上过期时间的。那么缓存失效的时候就会导致多个线程重建热点key。
解决版本:
互斥锁保证只有一个线程重建缓存。
永不过期。(不适用,因为热点key会越来越多)
二级缓存策略:设置二级缓存,一级缓存失效的时候。获取二级缓存,增加二级缓存的过期时间,setnx 一级缓存。二级缓存的时间大于一级缓存。
第12章 开发运维的陷阱
linux优化:
overcommit_memory
内存分配策略

设置内存分配策略
![]()
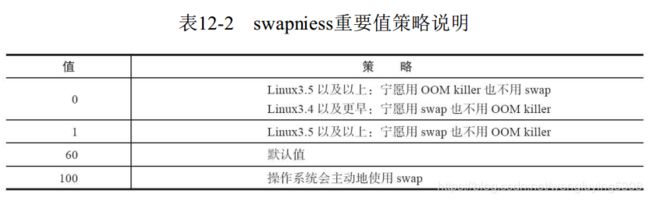
swappiness
取值范围是0-100,表示操作系统使用swap的概率
有的时候kill比僵死好
THP
关闭THP:echo never > /sys/kernel/mm/transparent_hugepage/enabled
NTP
使用时间同步协议。 保持各个节点的时间一致
热点key
- 拆分数据结构:大的hashkey迁移到几个不同的key中。
- 迁移热点key:
- 本地缓存加通知机制:使用本地缓存的速度大于redis几十倍。 存在多机数据不一致问题。 使用发布订阅通知修改数据,仍然存在一定的数据不一致性。
- TMC。有赞的缓存平台,通过客户端代理自动发现热点key并且缓存在本地,并且保证key的数据一致性问题。
1) Linux相关优化:
·vm.overcommit_memory建议为1。
·Linux>3.5, vm.swappiness建议为1, 否则建议为0。
·Transparent Huge Pages(THP) 建议关闭掉, 但需要注意Linux发行版本
改变了THP的配置位置。
·可以为Redis进程设置oom_adj, 减少Redis被OOM killer杀掉的概率,
但不要过度依赖此特性。
·建议对Redis所有节点所在机器使用NTP服务。
·设置合理的ulimit保证网络连接正常。
·设置合理的tcp-backlog参数。
2) 理解Redis的持久化有助于解决flush操作之后的数据快速恢复问题。
3) Redis安全建议:
·根据具体网络环境决定是否设置Redis密码。
·rename-command可以伪装命令, 但是要注意成本。
·合理的防火墙是防止攻击的利器。
787·bind可以将Redis的访问绑定到指定网卡上。
·定期备份数据应该作为习惯性操作。
·可以适当错开Redis默认端口启动。
·使用非root用户启动Redis。
4) bigkey的危害不容忽视: 数据倾斜、 超时阻塞、 网络拥塞, 可能是
Redis生产环境中的一颗定时炸弹, 删除bigkey时通常使用渐进式遍历的方
式, 防止出现Redis阻塞的情况。
5) 通过客户端、 代理、 monitor、 机器抓包四种方式找到热点key, 这几
种方式各具优势, 具体使用哪种要根据当前场景来决定。
第13章 cache cloud
第三方的私有云平台。
第14章
redis的配置讲解。