开放、普惠、高性能-SLS时序存储助力打造企业级全方位监控方案
无所不在的时序数据
时间带走一切,长年累月会把你的名字、外貌、性格、命运都改变。 ---柏拉图
随着时间的推移,万事万物都在不停的变化,而我们也会用各种数字去衡量这些变化信息,比如年龄、重量、速度、温度、金钱...在数字化时代中,我们会把这些随着时间变化的数据保存起来,挖掘这些数据的价值。通常我们会称这类数据为---时序数据。
时序数据用于描述物体在时间维度上的状态变化信息。

时序数据在各行各业都得到了非常广泛的应用,例如股票走势、交易趋势、服务器指标、脉搏心跳、定位坐标、能耗趋势等等,而这些数据几乎在所有的场景中都得到了应用,例如:
- 各类炒股软件提供众多不同维度的股票K线图,为广大股民提供参考标准;
- Apple Watch通过监控佩戴者的心率信息,帮助人们提早发现严重的心脏疾病;
- 国家电网通过分析各个小区、住户的用电量曲线,来判断是否有偷电漏电情况;
- 电商类的公司会监控平台的下单、交易、退货、评价等关键流程的变化趋势,用来快速发现各类异常;
- 各个游戏平台通过分析每个用户角色的操作、位置等变化规律,来判断是否使用了作弊辅助工具...
我们需要一个什么样的时序存储
为了能够支撑各种场景的时序分析、监控等需求,近几年在开源和商业领域均出现了一些时序存储的引擎,例如TimescaleDB、CrateDB、InfluxDB、OpenTSDB、Prometheus等,这些存储引擎分别有自己的生态和适用场景,在某些场景下具有较高的优势,例如TimescaleDB基于PostgreSQL,如果是PG的用户可以快速上手;InfluxDB具有非常完善的生态,TICK(Telegraf、 InfluxDB、Chronograf、Kapacitor)可以快速上手;Prometheus对于云原生场景支持非常友好,PromQL也非常便捷灵活,已经成为Kubernetes上监控的实事标准。
然而从实际公司的业务场景出发,对于时序数据会有更多的要求:
- 高性能:时序数据通常流量大、保存周期长且需要长时间的范围查询,能够支撑大规模的写入与快速查询是必备条件;
- 开放:通常公司内部会有多个部门对不同系统的时序数据进行不同类型的分析、监控等需求,因此时序存储需具备足够的开放能力,支持各种数据的接入以及下游消费;
- 低成本:这里的成本主要包括两方面:资源成本和人力运维成本。有摩尔定律的存在,单位资源成本越来越低,而单位人力成本每年都在提升,因此低成本的核心在于运维这套时序存储的人力成本;
- 智能化:尤其在海量监控对象的场景中,纯粹的静态规则很难发现某个监控对象的异常,因此时序存储上层需要附加智能化的算法,提升监控的准确率。
SLS时序存储发布
SLS的日志存储引擎在2016年对外发布,目前承接阿里内部以及众多企业的日志数据存储,每天有数十PB的日志类数据写入。其中有很大一部分属于时序类数据或者用来计算时序指标,为了让用户能够一站式完成整个DevOps生命周期的数据接入、清洗、加工、提取、存储、可视化、监控、问题分析等过程,我们专门推出了时序存储的功能,与日志存储一道为大家解决各类机器数据的存储问题。
时序存储整体架构如上图所示,接入层可以对接各类开源的采集软件以及SLS自己开发的高性能Logtail,同时支持各种语言SDK直接写入,也支持Kafka、Syslog等开放性协议;存储层是完全分布式架构,每个时序库可通过Sharding方式水平扩展,数据默认3副本高可靠存储;计算层与存储层分离,提供SQL、PromQL纯分析型语法,同时提供智能分析能力。基于SLS提供的采集、存储、分析等功能可快速构建企业自己的业务监控、微服务监控等方案。
功能特点

SLS时序存储从设计之初就是为了解决阿里内部与众多头部企业客户的时序存储需求,并借助于阿里内部多年的技术积累,使之可以适应绝大部分企业级时序监控/分析诉求。SLS时序存储的特点主要有:
- 丰富上下游:数据接入上SLS支持众多采集方式,包括各类开源Agent以及阿里云内部的监控数据通道;同时存储的时序数据支持对接各类的流计算、离线计算引擎,数据完全开放;
- 高性能:SLS存储计算分离架构充分发挥集群能力,尤其在大量数据下端对端的速度提升显著;
- 免运维:SLS的时序存储完全是服务化,无需用户自己去运维实例,而且所有数据都是3副本高可靠存储,不用担心数据的可靠性问题;
- 开源友好:SLS的时序存储原生支持Prometheus的写入和查询,并支持SQL92的分析方法,可以原生对接Grafana等可视化方案;
- 智能:SLS提供了各种AIOps算法,例如多周期估算、预测、异常检测、时序分类等各类时序算法,可以基于这些算法快速构建适应于公司业务的智能报警、诊断平台。
典型应用场景
应用/业务监控
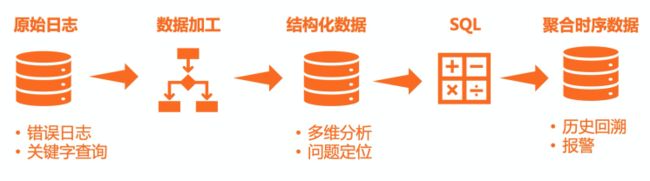
应用/业务监控是公司层面重要的工作之一,在阿里内部一直作为最重要的监控项在建设。通过SLS提供的各类数据采集功能将所有应用/业务数据统一、实时采集,利用数据加工把各个不同时期、不同风格的数据做结构化处理,基于结构化的数据就可以做一定的分析,但通常业务数据量级较大,我们还会使用SQL的聚合功能对数据进行一定的降维,使用降维后的聚合时序数据来做告警以及长期的监控指标回溯。
云原生监控

随着云原生技术的普及,越来越多的公司开始技术转型到云原生架构,借助于Prometheus、OpenTelemetry等CNCF的开源Project可以快速采集到Kubernetes以及各类中间件、应用的监控信息,阿里云上的云监控获取到所有云产品的监控数据。利用SLS时序存储以及日志/Trace存储的能力,可以支持各类监控数据的统一存储,数据可无缝对接Grafana的可视化,在Grafana上构建基础设施、云产品、中间件、应用软件的全方位监控大盘。
访问日志分析
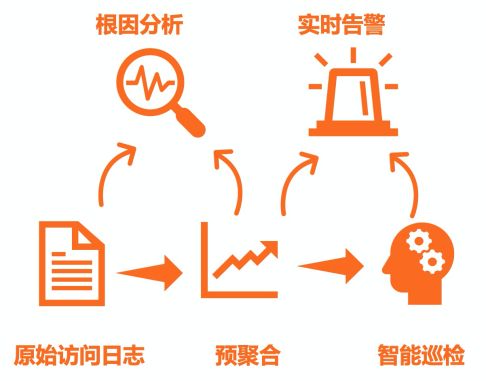
访问日志作为网站、APP的入口流量记录,能够直接反映出当前应用是否正常,因此运维领域的必备监控项。通过Logtail采集原始的访问日志,可用来分析/调查每个用户的请求,也可用作归档/审计需求;但原始访问日志量较大,不太适合直接的监控,通常会通过预聚合的方式对数据进行降维,基于聚合后的时序数据进行实时监控,并可应用SLS提供的智能巡检功能对每个业务站点进行独立的智能监控。
无所不在的时序数据
时间带走一切,长年累月会把你的名字、外貌、性格、命运都改变。 ---柏拉图
随着时间的推移,万事万物都在不停的变化,而我们也会用各种数字去衡量这些变化信息,比如年龄、重量、速度、温度、金钱...在数字化时代中,我们会把这些随着时间变化的数据保存起来,挖掘这些数据的价值。通常我们会称这类数据为---时序数据。
时序数据用于描述物体在时间维度上的状态变化信息。
时序数据在各行各业都得到了非常广泛的应用,例如股票走势、交易趋势、服务器指标、脉搏心跳、定位坐标、能耗趋势等等,而这些数据几乎在所有的场景中都得到了应用,例如:
- 各类炒股软件提供众多不同维度的股票K线图,为广大股民提供参考标准;
- Apple Watch通过监控佩戴者的心率信息,帮助人们提早发现严重的心脏疾病;
- 国家电网通过分析各个小区、住户的用电量曲线,来判断是否有偷电漏电情况;
- 电商类的公司会监控平台的下单、交易、退货、评价等关键流程的变化趋势,用来快速发现各类异常;
- 各个游戏平台通过分析每个用户角色的操作、位置等变化规律,来判断是否使用了作弊辅助工具...
我们需要一个什么样的时序存储
为了能够支撑各种场景的时序分析、监控等需求,近几年在开源和商业领域均出现了一些时序存储的引擎,例如TimescaleDB、CrateDB、InfluxDB、OpenTSDB、Prometheus等,这些存储引擎分别有自己的生态和适用场景,在某些场景下具有较高的优势,例如TimescaleDB基于PostgreSQL,如果是PG的用户可以快速上手;InfluxDB具有非常完善的生态,TICK(Telegraf、 InfluxDB、Chronograf、Kapacitor)可以快速上手;Prometheus对于云原生场景支持非常友好,PromQL也非常便捷灵活,已经成为Kubernetes上监控的实事标准。
然而从实际公司的业务场景出发,对于时序数据会有更多的要求:
- 高性能:时序数据通常流量大、保存周期长且需要长时间的范围查询,能够支撑大规模的写入与快速查询是必备条件;
- 开放:通常公司内部会有多个部门对不同系统的时序数据进行不同类型的分析、监控等需求,因此时序存储需具备足够的开放能力,支持各种数据的接入以及下游消费;
- 低成本:这里的成本主要包括两方面:资源成本和人力运维成本。有摩尔定律的存在,单位资源成本越来越低,而单位人力成本每年都在提升,因此低成本的核心在于运维这套时序存储的人力成本;
- 智能化:尤其在海量监控对象的场景中,纯粹的静态规则很难发现某个监控对象的异常,因此时序存储上层需要附加智能化的算法,提升监控的准确率。
SLS时序存储发布
SLS的日志存储引擎在2016年对外发布,目前承接阿里内部以及众多企业的日志数据存储,每天有数十PB的日志类数据写入。其中有很大一部分属于时序类数据或者用来计算时序指标,为了让用户能够一站式完成整个DevOps生命周期的数据接入、清洗、加工、提取、存储、可视化、监控、问题分析等过程,我们专门推出了时序存储的功能,与日志存储一道为大家解决各类机器数据的存储问题。
时序存储整体架构如上图所示,接入层可以对接各类开源的采集软件以及SLS自己开发的高性能Logtail,同时支持各种语言SDK直接写入,也支持Kafka、Syslog等开放性协议;存储层是完全分布式架构,每个时序库可通过Sharding方式水平扩展,数据默认3副本高可靠存储;计算层与存储层分离,提供SQL、PromQL纯分析型语法,同时提供智能分析能力。基于SLS提供的采集、存储、分析等功能可快速构建企业自己的业务监控、微服务监控等方案。
功能特点
SLS时序存储从设计之初就是为了解决阿里内部与众多头部企业客户的时序存储需求,并借助于阿里内部多年的技术积累,使之可以适应绝大部分企业级时序监控/分析诉求。SLS时序存储的特点主要有:
- 丰富上下游:数据接入上SLS支持众多采集方式,包括各类开源Agent以及阿里云内部的监控数据通道;同时存储的时序数据支持对接各类的流计算、离线计算引擎,数据完全开放;
- 高性能:SLS存储计算分离架构充分发挥集群能力,尤其在大量数据下端对端的速度提升显著;
- 免运维:SLS的时序存储完全是服务化,无需用户自己去运维实例,而且所有数据都是3副本高可靠存储,不用担心数据的可靠性问题;
- 开源友好:SLS的时序存储原生支持Prometheus的写入和查询,并支持SQL92的分析方法,可以原生对接Grafana等可视化方案;
- 智能:SLS提供了各种AIOps算法,例如多周期估算、预测、异常检测、时序分类等各类时序算法,可以基于这些算法快速构建适应于公司业务的智能报警、诊断平台。
典型应用场景
应用/业务监控
应用/业务监控是公司层面重要的工作之一,在阿里内部一直作为最重要的监控项在建设。通过SLS提供的各类数据采集功能将所有应用/业务数据统一、实时采集,利用数据加工把各个不同时期、不同风格的数据做结构化处理,基于结构化的数据就可以做一定的分析,但通常业务数据量级较大,我们还会使用SQL的聚合功能对数据进行一定的降维,使用降维后的聚合时序数据来做告警以及长期的监控指标回溯。
云原生监控
随着云原生技术的普及,越来越多的公司开始技术转型到云原生架构,借助于Prometheus、OpenTelemetry等CNCF的开源Project可以快速采集到Kubernetes以及各类中间件、应用的监控信息,阿里云上的云监控获取到所有云产品的监控数据。利用SLS时序存储以及日志/Trace存储的能力,可以支持各类监控数据的统一存储,数据可无缝对接Grafana的可视化,在Grafana上构建基础设施、云产品、中间件、应用软件的全方位监控大盘。
访问日志分析
访问日志作为网站、APP的入口流量记录,能够直接反映出当前应用是否正常,因此运维领域的必备监控项。通过Logtail采集原始的访问日志,可用来分析/调查每个用户的请求,也可用作归档/审计需求;但原始访问日志量较大,不太适合直接的监控,通常会通过预聚合的方式对数据进行降维,基于聚合后的时序数据进行实时监控,并可应用SLS提供的智能巡检功能对每个业务站点进行独立的智能监控。
无所不在的时序数据
时间带走一切,长年累月会把你的名字、外貌、性格、命运都改变。 ---柏拉图
随着时间的推移,万事万物都在不停的变化,而我们也会用各种数字去衡量这些变化信息,比如年龄、重量、速度、温度、金钱...在数字化时代中,我们会把这些随着时间变化的数据保存起来,挖掘这些数据的价值。通常我们会称这类数据为---时序数据。
时序数据用于描述物体在时间维度上的状态变化信息。
时序数据在各行各业都得到了非常广泛的应用,例如股票走势、交易趋势、服务器指标、脉搏心跳、定位坐标、能耗趋势等等,而这些数据几乎在所有的场景中都得到了应用,例如:
- 各类炒股软件提供众多不同维度的股票K线图,为广大股民提供参考标准;
- Apple Watch通过监控佩戴者的心率信息,帮助人们提早发现严重的心脏疾病;
- 国家电网通过分析各个小区、住户的用电量曲线,来判断是否有偷电漏电情况;
- 电商类的公司会监控平台的下单、交易、退货、评价等关键流程的变化趋势,用来快速发现各类异常;
- 各个游戏平台通过分析每个用户角色的操作、位置等变化规律,来判断是否使用了作弊辅助工具...
我们需要一个什么样的时序存储
为了能够支撑各种场景的时序分析、监控等需求,近几年在开源和商业领域均出现了一些时序存储的引擎,例如TimescaleDB、CrateDB、InfluxDB、OpenTSDB、Prometheus等,这些存储引擎分别有自己的生态和适用场景,在某些场景下具有较高的优势,例如TimescaleDB基于PostgreSQL,如果是PG的用户可以快速上手;InfluxDB具有非常完善的生态,TICK(Telegraf、 InfluxDB、Chronograf、Kapacitor)可以快速上手;Prometheus对于云原生场景支持非常友好,PromQL也非常便捷灵活,已经成为Kubernetes上监控的实事标准。
然而从实际公司的业务场景出发,对于时序数据会有更多的要求:
- 高性能:时序数据通常流量大、保存周期长且需要长时间的范围查询,能够支撑大规模的写入与快速查询是必备条件;
- 开放:通常公司内部会有多个部门对不同系统的时序数据进行不同类型的分析、监控等需求,因此时序存储需具备足够的开放能力,支持各种数据的接入以及下游消费;
- 低成本:这里的成本主要包括两方面:资源成本和人力运维成本。有摩尔定律的存在,单位资源成本越来越低,而单位人力成本每年都在提升,因此低成本的核心在于运维这套时序存储的人力成本;
- 智能化:尤其在海量监控对象的场景中,纯粹的静态规则很难发现某个监控对象的异常,因此时序存储上层需要附加智能化的算法,提升监控的准确率。
SLS时序存储发布
SLS的日志存储引擎在2016年对外发布,目前承接阿里内部以及众多企业的日志数据存储,每天有数十PB的日志类数据写入。其中有很大一部分属于时序类数据或者用来计算时序指标,为了让用户能够一站式完成整个DevOps生命周期的数据接入、清洗、加工、提取、存储、可视化、监控、问题分析等过程,我们专门推出了时序存储的功能,与日志存储一道为大家解决各类机器数据的存储问题。
时序存储整体架构如上图所示,接入层可以对接各类开源的采集软件以及SLS自己开发的高性能Logtail,同时支持各种语言SDK直接写入,也支持Kafka、Syslog等开放性协议;存储层是完全分布式架构,每个时序库可通过Sharding方式水平扩展,数据默认3副本高可靠存储;计算层与存储层分离,提供SQL、PromQL纯分析型语法,同时提供智能分析能力。基于SLS提供的采集、存储、分析等功能可快速构建企业自己的业务监控、微服务监控等方案。
功能特点
SLS时序存储从设计之初就是为了解决阿里内部与众多头部企业客户的时序存储需求,并借助于阿里内部多年的技术积累,使之可以适应绝大部分企业级时序监控/分析诉求。SLS时序存储的特点主要有:
- 丰富上下游:数据接入上SLS支持众多采集方式,包括各类开源Agent以及阿里云内部的监控数据通道;同时存储的时序数据支持对接各类的流计算、离线计算引擎,数据完全开放;
- 高性能:SLS存储计算分离架构充分发挥集群能力,尤其在大量数据下端对端的速度提升显著;
- 免运维:SLS的时序存储完全是服务化,无需用户自己去运维实例,而且所有数据都是3副本高可靠存储,不用担心数据的可靠性问题;
- 开源友好:SLS的时序存储原生支持Prometheus的写入和查询,并支持SQL92的分析方法,可以原生对接Grafana等可视化方案;
- 智能:SLS提供了各种AIOps算法,例如多周期估算、预测、异常检测、时序分类等各类时序算法,可以基于这些算法快速构建适应于公司业务的智能报警、诊断平台。
典型应用场景
应用/业务监控
应用/业务监控是公司层面重要的工作之一,在阿里内部一直作为最重要的监控项在建设。通过SLS提供的各类数据采集功能将所有应用/业务数据统一、实时采集,利用数据加工把各个不同时期、不同风格的数据做结构化处理,基于结构化的数据就可以做一定的分析,但通常业务数据量级较大,我们还会使用SQL的聚合功能对数据进行一定的降维,使用降维后的聚合时序数据来做告警以及长期的监控指标回溯。
云原生监控
随着云原生技术的普及,越来越多的公司开始技术转型到云原生架构,借助于Prometheus、OpenTelemetry等CNCF的开源Project可以快速采集到Kubernetes以及各类中间件、应用的监控信息,阿里云上的云监控获取到所有云产品的监控数据。利用SLS时序存储以及日志/Trace存储的能力,可以支持各类监控数据的统一存储,数据可无缝对接Grafana的可视化,在Grafana上构建基础设施、云产品、中间件、应用软件的全方位监控大盘。
访问日志分析
访问日志作为网站、APP的入口流量记录,能够直接反映出当前应用是否正常,因此运维领域的必备监控项。通过Logtail采集原始的访问日志,可用来分析/调查每个用户的请求,也可用作归档/审计需求;但原始访问日志量较大,不太适合直接的监控,通常会通过预聚合的方式对数据进行降维,基于聚合后的时序数据进行实时监控,并可应用SLS提供的智能巡检功能对每个业务站点进行独立的智能监控。
作者:元乙
原文链接:https://developer.aliyun.com/article/768895?utm_content=g_1000161276
本文为阿里云原创内容,未经允许不得转载