Hotspot JVM常用选项
一、选项的分类
Hotspot JVM提供以下三大类选项:
1. 标准选项:这类选项的功能是很稳定的,在后续版本中也不太会发生变化,即使有变化也必须保证向后兼容。运行java或java -help可以看到所有的标准选项。所有的标准选项都是以“-”开头,比如-version,-server等。
2. X选项:比如-Xms。这类选项以“-X”开头,它们也被称为X选项。运行java -X命令可以看到所有的X选项。这类选项的功能还是很稳定,但是官方的说法是它们的行为可能在后续版本中改变,也有可能不在后续版本中提供了。
3. XX选项:这类选项是属于实验性,主要是给JVM开发者用于开发和调试JVM的,在后续版本中行为有可能会变化。运行java -XX:+PrintCommandLineFlags, java -XX:+PrintFlagsInitial和java -XX:+PrintFlagsFinal可查看该类选项的值,具体差异见后文。
二、XX选项的语法
1. 如果是bool类型的选项,它的格式为-XX:+flag或者-XX:-flag,分别表示开启和关闭该选项。
2. 针对非bool类型的选项,它的格式为-XX:flag=value。
三、常用选项
1. 指定JVM的类型:-server,-client
Hotspot JVM有两种类型,分别是server和client。它们的区别是Server VM的初始堆空间会大一些,默认使用并行垃圾回收器。Client VM相对会保守些,初始堆空间会小一些,默认使用串行垃圾回收器,它的目标是为了让JVM的启动速度更快。
JVM在启动的时候会根据硬件和操作系统自动选择使用Server还是Client类型的JVM。
- - 在32位Windows系统上,不论硬件配置如何,默认都使用Client类型的JVM。
- - 在其它32位操作系统上,如果机器配置有2GB集群以上的内存同时有2个以上的CPU,则默认会使用Server类型的JVM。
- - 64位机器上只有Server类型的JVM。也就是说Client类型的JVM只只32位机器上提供。
- - 你可以使用-server和-client选项来制定JVM的类型,不过只在32位机器上有效。
2. 指定JIT编译器模式:-Xint, -Xcomp, -Xmixed
Java是一种解释型语言,但随着JIT技术的进步,它能在运行时将Java的字节码编译成本地代码。以上几个选项解释如下:
- -Xint表示禁用JIT,所有字节码都被解释执行,这个模式的速度最慢。
- -Xcomp表示所有字节码都首先被编译成本地代码,然后再执行。
- -Xmixed,默认模式,让JIT根据程序运行的情况,有选择地将某些代码编译成本地代码。-Xcomp和-Xmixed到底谁的速度快,针对不同的程序可能有不同的结果,基本还是推荐使用默认模式。
3. -version和-showversion
-version就是查看当前机器的Java是什么版本,是什么类型的JVM(Server/Client),采用的是什么执行模式。
-showversion的作用是在运行一个程序的时候首先把JVM的版本信息打印出来,这样便于问题诊断。个人建议Server类型的程序都把这个选项打开,这样可以发现一些配置问题,比如程序需要jdk1.7才能运行,而有的机器上装有多个jdk的版本,打开这个选项可以避免使用错误的版本。
4. 查看XX选项的值:-XX:+PrintCommandLineFlags,-XX:+PrintFlagsInitial和-XX:+PrintFlagsFinal
-XX:+PrintCommandLineFlags可以在程序运行前打印出用户手动设置或者JVM自动设置的XX选项,建议加上这个选项以辅助问题诊断。
相关的另外两个选项:-XX:+PrintFlagsInitial表示打印出所有XX选项的默认值,-XX:+PrintFlagsFinal表示打印出XX选项在运行程序时生效的值。
5. 内存大小相关的选项
- -Xms 设置初始堆的大小,也是最小堆的大小,它等价于:-XX:InitialHeapSize。
- -Xmx 设置最大堆的大小,它等价于-XX:MaxHeapSize。
比如,下面这条命令就是设置堆的初始值为128M,最大值为2G:
java -Xms128m -Xmx2g MyApp
如果堆的初始值和最大值不一样的的话,JVM会根据程序的运行情况,自动调整堆的大小,这可能会影响到一些效率。针对服务端程序,一般是把堆的最小值和最大值设为一样来避免堆扩展和收缩对性能的影响。
- -XX:PermSize 设置永久区的初始大小
- -XX:MaxPermSize 设置永久区的最大值
永久区是存放类及常量池的地方,如果程序需要加载的class文件非常多的话,就需要增大永久区的大小。
- -Xss 设置线程栈大小,线程栈的大小会影响到递归调用的深度,同时也会影响到能同时开启的线程数。
6. OutOfMemory(OOM)相关选项
如果程序发生OOM后,JVM可以配置一些选项来做一些善后工作,比如把内存dump下来,或者自动采取一些报警等动作。
- -XX:+HeapDumpOnOutOfMemoryError 表示在内存发生OOM的时候,把Heap转存(Dump)到文件以便后续分析,文件名通常是java_pid
.hprof,其中pid为该进程的进程号,例如java_pid345.hprof。 - -XX:HeapDumpPath=
用来指定heap转存文件的存储路径,需要指定的路径下有足够的空间来保存该文件。 - -XX:OnOutOfMemoryError=
用来指定一个可行性程序或可执行脚本文件路径,当发生OOM的时候,去执行这个脚本。
7. 新生代相关选项
在介绍新生代相关选项前,先简单介绍下Hotspot VM的Heap分代背景。很多面向对象程序在运行时都具有如下两点特征:
- 新创建的对象通常不会存活多长时间。
IBM公司的专项研究表明,新生代中的对象98%都是“朝生夕死”。
- 很少有老对象引用到新对象。
基于这两点,把新老对象放到不同的区域(分别叫做新生代和老年代)可以针对新老对象的特点使用不同的回收算法,同时在遍历新对象的时候不用遍历老对象,从而提高垃圾回收效率。
在Hotspot JVM中,新生代进一步被分成了三个区域:一个稍大的区域Eden和两个较小但大小相等的Survivor区域(分别叫From和To)。一般来讲,新对象首先分配在Eden区,当Eden区满的时候,会执行一次Minor GC。Minor GC使用的是标记-拷贝算法。垃圾回收器会首先标记Eden区和From区中还存活的对象,然后把他们全都移到To区域,这样Eden和From区域的空间就全部可以回收了。下次回收则是Eden区和To区移动到From区。
下图展示了MinorGC的流程,绿色区域表示空闲空间,红色表示活动对象,黄色表示可以回收的对象。
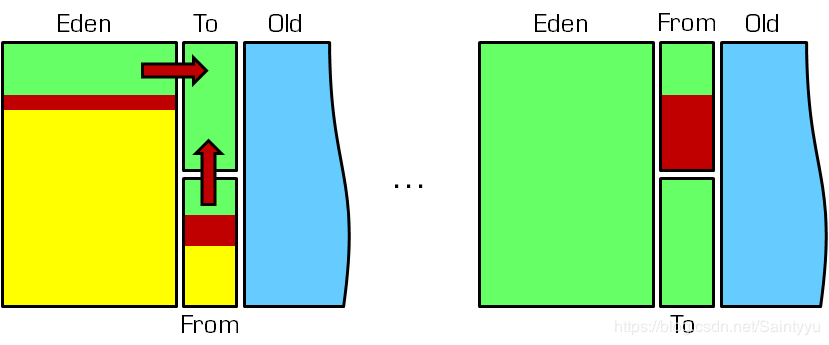
简要总结一下,对象在新生代的生命周期是,它首先在Eden区诞生,如果对象在Minor GC后还存活的话,就移动到Survivor区。在后续MinorGC的时候,如果对象还存活的话,就在两个Survivor区来回倒腾,直到满足以下条件之一则移动到老年代:
- Minor GC后,Survivor仍然放不下;
- 对象在Survivor区域每倒腾一次其年龄就加1,如果一个对象的年龄达到了一定阈值,则会被移动到老年代;
- 大对象在创建的时候就会被直接放到老生代。
由此可见,新生代空间大小很重要:如果新生代空间过小,就会导致对象很快被移动到老年代,从而使得某些原本可以及时回收的对象存活的时间过长,而且老生代回收的代价更大。相反,如果新生代空间过大,就会使得某些存活时间长的对象在新生代倒腾很多次,影响到新生代垃圾回收效率。这就需要根据应用的特点,选择合适的值。Hotspot提供了如下选项来调节新生代的参数:
- -XX:NewSize和-XX:MaxNewSize分别用来设置新生代的最小和最大值。需要注意的是,新生代是JVM堆的一部分,新生代的空间不能大于老年代,因为在极端情况下,新生代中对象可能会全部移动到老年代,因此-XX:MaxNewSize最大只能设为-Xmx的一半。
- -XX:NewRatio用来设置老年代和新生代的比例,比如-XX:NewRatio=2表示1/3是新生代,2/3是老年代。使用这个选项的好处是新生代的大小能随着Heap的变化而变化。JVM默认的NewRatio值不同jdk版本可能会有差异,本机默认值为2(有些博客提到Sun官方推荐该值为3/8)。
- -XX:SurvivorRatio用来设置新生代中Eden和Survivor空间大小的比例,需要注意的是有两个Survivor。比如-XX:SurvivorRatio=8表示Eden区占新生代的8/10,而两个Survivor分别占1/10。调节Survivor空间的时候也需要注意折衷,如果survivor空间小的话,那么很可能一次Minor GC的时候Survivor就满了,从而对象就被移动到了老年代;如果Survivor空间太大的话,那么Eden区域就小了,从而导致Minor GC发生得更频繁。
总的来说,调节新生代的目标是:1、避免对象过早地移到老年代;2、避免需要长期存活的对象在新生代呆太久时间,这会提高Minor GC发生频率以及增加单次Minor GC的耗时。这需要对程序运行情况进行分析。接下来介绍一个参数用来分析新生代对象年龄分布。
8. -XX:+PrintTenturingDistribution
该参数让JVM在每次Minor GC之后打出Survivor空间中对象的年龄分布。比如:
Desired survivor size 75497472 bytes, new threshold 15 (max 15)
- age 1: 19321624 bytes, 19321624 total
- age 2: 79376 bytes, 19401000 total
- age 3: 2904256 bytes, 22305256 total从第一行可以看出,JVM期望的Survivor空间占用72M,对象被移动到老年代的晋升阈值年龄为15。期望Survivor空间的计算公式为:
Desired survivor size = 单个Survivor区的实际大小 * -XX:TargetSurvivorRatio期望Survivor空间的作用是用于动态计算对象的晋升阈值(tenuring threshold)。JVM有一个晋升年龄阈值参数:-XX:MaxTenuringThreshold,默认值为15。但实际上新生代的对象并不一定是达到该值才会晋升到老年代,而是动态地计算实际的晋升阈值tenuring threshold。具体来说就是,JVM会将每个对象的年龄信息、每个年龄段对象的总大小记录在“age table”表中。按照age table中年龄从小到大排,如果所有小于等于某个age值的对象占用空间大于Desired survivor size,则最新的晋升阈值即为age和MaxTenuringThreshold两者的最小值,如果所有age值的对象占用空间大小都小于Desired survivor size,则tenuring threshold以MaxTenuringThreshold为准。
接下来以age开头的各行,表示年龄为1的对象约19M,年龄为2的对象约为79K,年龄为3的对象为占2.9M。每行最后面的数字表示所有小于等于该行年龄对象的总大小。目前因为Survivor空间中对象的大小22M小于期望Survivor空间的大小72M,所以没有对象会被移动到老年代。
假设下一次Minor GC后的输出结果为:
Desired survivor size 75497472 bytes, new threshold 2 (max 15)
- age 1: 68407384 bytes, 68407384 total
- age 2: 12494576 bytes, 80901960 total
- age 3: 79376 bytes, 80981336 total
- age 4: 2904256 bytes, 83885592 total上次MinorGC后还存活的对象在这次MinorGC年龄都增加了1,可以看到上次年龄为2和3的对象(对应在这次GC后的年龄为3和4)依然存在(大小未变),而一部分上次对象年龄为1的对象在这次GC时被回收了。同时可以看到这次新增了约68M的新对象。这次MinorGC后Survivor区域中对象总的大小为约83M,大于了期望的Survivor空间的大小72M,因此它就把对象移到老年代的年龄的阈值调整为2,在下次MinorGC时一部分对象就会被移到老年代了。
相关的调整选项有:
- -XX:InitialTenuringThreshold 表示对象被移动到老年代的年龄阈值的初始值,本机默认值为7。该参数在第一次Minor GC时用于判断对象是否需要移动到老年代。
- -XX:MaxTenuringThreshold 表示对象被移动到老年代的年龄阈值的最大值,默认值为15。这个参数是给Serial收集器和没有开启UseAdaptiveSizePolicy的ParNew GC收集器用的,对于PSGC而言,第一次以InitialTenuringThreshold(默认值为7)来算,之后的MinorGC会动态估算(另外,也会根据TargetSurvivorRatio来动态计算晋升阈值)。
- -XX:TargetSurvivorRatio 表示Minor GC结束后Survivor区域中占用空间的期望比例。
这些参数的调节没有统一的标准,但有两点可以借鉴:
- 如果Survivor中对象的年龄分布显示很多对象在经历了多次GC最终年龄达到了-XX:MaxTenuringThreshold才被移到老年代,这可能说明-XX:MaxTenuringThreshold设置得过大,也有可能是Survivor的空间过大。
- 如果-XX:MaxTenuringThreshold的值大于1,但是很多对象年龄都不大于1,那就得关注一下期望Survivor空间。如果每次GC后Survivor中对象的大小都没有超过期望的Survivor空间大小,则说明GC工作得很好。反之,则说明Survivor空间小了,使得新生成的对象很快就被移动到老年代了。
9. 吞吐量优先收集器的相关选项
衡量JVM垃圾收集器的两个基本指标是吞吐量和停顿时间。吞吐量是指执行用户代码的时间占总的时间的比例,总的时间包括执行用户代码的时间和执行垃圾回收的时间。在垃圾回收的时候执行用户代码的线程必须暂停,这会导致程序暂时失去响应。停顿时间就是衡量垃圾回收时造成用户线程暂停的时间。这两个指标在一定程度时相互矛盾的,不可能让一个程序的吞吐量很高的同时停顿时间也很短,只能优先选择一个目标或者折衷一下。因此,不同的垃圾回收器有不同的侧重点。
Parallel Scavenge
在Hotspot JVM中,侧重于吞吐量的垃圾回收器是Parallel Scavenge,它的相关配置如下:
- -XX:+UseParallelOldGC 表示新生代和老年代都使用并行回收器,其中Old表示老年代的意思,而不是旧的意思。Parallel Old是Parallel Scavenge的老年代版本,使用标记整理算法。从Java1.6开始提供,在Java6以前,Parallel Scavenge新生代收集器只能和Serial Old收集器搭配使用,到了Java6及以后Parallel Scavenge和Parallel Old是默认搭配的。
- -XX:ParallelGCThreads=n 表示配置多少个线程来执行垃圾回收。默认的配置是如果处理器的个数小于或等于8,则就是处理器的个数;如果处理器个数大于8个,则其值为3+5N/8。也可以根据程序的需要去设置这个值,比如你的机器有16核,同时运行4个Java程序,那么这个值设置为4比较合理,因为JVM不会去探测同一个机器上有多少个Java程序。
- -XX:UseAdaptiveSizePolicy 表示是否开启自适应策略,打开这个开关之后,JVM会自动调节新生代大小,Eden和Survivor的比例等参数。用户只需要设置期望的吞吐量(-XX:GCTimeRatio)和期望停顿时间(-XX:MaxPauseTimeMillis)。然后JVM会尽量向用户期望的方向去优化。不过使用此参数建议显式设置-XX:SurvivorRatio=8这个参数,以固定Eden和Survivor区之间的比例,否则可能导致JVM过度优化Eden和Survivor的比例,从而引发GC问题。详见参考博文7。
此外,如果机器只有一个核的话,采用并行回收器可能得不偿失,因为多个回收线程会争抢CPU资源,反而造成更大的消耗。这时,就最好采用串行回收器,相关的参数是-XX:+UseSerialGC。
CMS收集器
CMS收集器(ConcurrentMarkSweep),是一个关注系统停顿时间的收集器。它的主要思想是把收集器分成了不同的阶段,其中某些阶段是可以和用户线程并行的,从而减少整体停顿时间。它主要分成以下几个阶段:
- 初始标记阶段:initial mark
- 并发标记:concurrent mark
- 重新标记: remark
- 并发清理:concurrent clean
- 并发重置:concurrent reset
上述过程,凡是以concurrent开头的的阶段都是可以和用户线程并行的,其他阶段则是要暂停用户线程。
CMS虽然能减少系统停顿时间,但它也有缺点:
- 它是一个标记-清除收集器,也就是说运行一段时间之后会产生内存碎片,如果无法找到一块足够大的连续内存存放对象时,将会触发因此Full GC。CMS提供一个开关参数-XX:+UseCMSCompactAtFullCollection,用于指定在Full GC之后进行内存整理,内存整理会使得垃圾收集停顿时间变长,CMS提供了另外一个参数-XX:CMSFullGCsBeforeCompaction,用于设置在执行多少次不压缩的Full GC之后,跟着再来一次内存整理。
- CMS无法处理浮动垃圾(Floating Garbage),可能会导致Concurrent ModeFailure失败而导致另一次Full GC。由于CMS收集器和用户线程并发运行,因此在收集过程中不断有新的垃圾产生,这些垃圾出现在标记过程之后,CMS无法在本次收集中处理掉它们,只好等待下一次GC时再将其清理掉,这些垃圾就称为浮动垃圾。
- CMS在运行过程中会咱用一些内存,同时系统也在运行,如果系统产生新对象的速度比CMS清理的速度快的话,会导致CMS运行失败。
它的相关选项如下:
- -XX:+UseConcMarkSweepGC 表示老年代开启CMS收集器,而新生代默认会使用并行收集器(ParNew)。
- -XX:ConcGCThreads 指定用多少个线程来执行CMS的并发阶段。
- -XX:CMSInitiatingOccupancyFraction 指定在老年代用掉多少内存之后开始进行垃圾回收。与吞吐量优先的回收器不同的是,吞吐量优先的回收器在老生代内存用尽了以后才开始进行收集,这对CMS来讲是不行的,因为吞吐量优先的垃圾回收器运行的时候会停止所有用户线程,所以不会产生新的对象,而CMS运行的时候,用户线程还有可能产生新的对象,所以不能等到内存用光后才开始运行。比如-XX:CMSInitiatingOccupancyFraction=75表示老生代用掉75%后开始回收垃圾。默认值是68。
- -XX:+ExplicitGCInvokesConcurrent 如果在代码里显式调用了System.gc(),那么它还是会执行Full GC从而导致用户线程被暂停。采用这个选项使得显式触发GC的时候还是使用CMS收集器。
- -XX:+DisableExplicitGC 这个选项是禁止显式调用GC。
GC日志相关的选项
下面是一些GC日志相关的选项:
- -XX:+PrintGC,等同于-verbose:gc 表示打开简化的GC日志,相关输出如下:
[GC 425355K->351685K(506816K), 0.2175300 secs]
[Full GC 500561K->456058K(506816K), 0.6421920 secs]其中以GC开头的行表示发生了一次Minor GC,后面的数字表示收集前后Heap空间的占用量,圆括号里面表示Heap大小,最后的数字表示用了多长时间。当然,通过这些选项只能看到一些基本信息,而且所有收集器的输出在这个模式下都是一样的。
- -XX:+PrintGCDetails 这个选项会打出更多的GC日志,不同的收集器产生的日志会不一样。
- -XX:+PrintGCTimeStamps打印GC发生的时间相对于JVM启动时间
- -XX:+PrintGCDateStamps表示打印出GC发生的具体时间。
- -Xloggc:
表示把GC日志写入到一个文件中去,而不是打印到标准输出中。
实战示例
下面是同时使用-XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps三个参数,且垃圾回收器为ParNew+CMS组合的Minor GC和Full GC示例:
59.084: [GC (Allocation Failure) 59.084: [ParNew: 533152K->33193K(566208K), 0.0724682 secs] 579540K->80100K(3082816K), 0.0726588 secs] [Times: user=0.10sys=0.00, real=0.07 secs]
59.167: [GC (CMS Initial Mark) [1 CMS-initial-mark: 46907K(2516608K)] 90342K(3082816K), 0.0208217 secs] [Times: user=0.03 sys=0.01, real=0.03 secs]
59.188: [CMS-concurrent-mark-start]
59.285: [CMS-concurrent-mark: 0.096/0.097 secs] [Times: user=0.17 sys=0.00, real=0.09 secs]
59.285: [CMS-concurrent-preclean-start]
59.292: [CMS-concurrent-preclean: 0.007/0.007 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
59.292: [CMS-concurrent-abortable-preclean-start]
60.451: [GC (Allocation Failure) 60.451: [ParNew: 536489K->33189K(566208K), 0.0486481 secs] 583396K->80804K(3082816K), 0.0488954 secs] [Times: user=0.09sys=0.01, real=0.05 secs]
61.445: [CMS-concurrent-abortable-preclean: 2.094/2.153 secs] [Times: user=3.34 sys=0.57, real=2.15 secs]上面的GC(Allocation Failure)表示Minor GC:其中ParNew: 533152K->33193K(566208K)表示年轻代GC前已使用空间为533152K,GC后已使用空间为33193K,年轻代总空间为566208K。紧随其后的579540K->80100K(3082816K)表示GC前整个堆的已使用空间为579540K,GC后已使用空间为80100K,堆的总空间为3082816K。
上面的GC (CMS Initial Mark)表示Full GC:其中CMS-initial-mark: 46907K(2516608K)表示老年代在已使用空间为46907K时开始执行初始标记,标记时老年代总空间为2516608K,紧随其后的90342K(3082816K)表示初始标记时堆的已使用空间为90342K,然后堆的总空间为3082816K。
需要注意的是,这些和GC日志相关的选项可以在JVM已经启动后再开启,可以通过jinfo这个工具去设置。这样就可以在需要诊断问题的时候再开启GC日志。以下为常用示例:
- jinfo pid 输出进程号为pid的JVM进程的全部参数和系统属性
- jinfo -flag name pid 输出对应名称的参数
- jinfo -flag [+|-]name 开启或关闭对应名称的参数
- jinfo -flag name=value 修改指定参数的值
- jinfo -flags pid 输出全部的参数
- jinfo -sysprops pid 输出当前JVM的全部系统属性
不过在java 8 中 jinfo 命令提示不在支持了,但是还可以使用。后面的版本可能会抛弃它。建议采用 jps 和 jsadebugd 两个命令取代 jinfo 命令。详见参考博客20。
参考博文:
1.https://www.zybuluo.com/jewes/note/57352 Java程序员必学的Hotspot JVM选项
2. https://blog.csdn.net/qq_35576994/article/details/87777052 Gabage Collection-垃圾回收中为什么新生代的Eden:Survivor from:Survivor to = 8:1:1
3. https://blog.csdn.net/zero__007/article/details/52797684 MaxTenuringThreshold 和 TargetSurvivorRatio参数说明
4. https://segmentfault.com/a/1190000004657756 Survivor空间溢出实例
5. https://blog.csdn.net/lovewebeye/article/details/80911838 JAVA(-Xms,Xmx,Xmn-XX:newSize,-XX:MaxnewSize,-XX:PermSize,-XX:MaxPermSize)区别
6. http://www.it610.com/article/2113431.htm JVM heap参数配置法则
7. https://www.jianshu.com/p/7414fd6862c5 JVM GC 之「AdaptiveSizePolicy」实战
8. https://www.jianshu.com/p/8b03428458e7 JVM垃圾收集算法和垃圾收集器原理
9. https://www.jianshu.com/p/61bf0e9011c4 -XX:CMSInitiatingOccupancyFraction
10. https://www.jianshu.com/p/bdd6f03923d1 垃圾回收器比较: G1 vs CMS
11. https://blog.csdn.net/chjttony/article/details/7883748 Serial、ParNew、Parallel Scavenge、CMS、G1等的搭配组合
12. https://www.jianshu.com/p/1d7f4fda1efe Java G1 垃圾回收
13. http://blog.jobbole.com/109170/ 深入理解 Java G1 垃圾收集器
14. https://www.jianshu.com/p/548c67aa1bc0 G1从入门到放弃
15. http://outofmemory.cn/java/jvm/jvm-tools-jps-jstat-jinfo-jmap-jhat-jstack JVM监控工具:jps、jstat、jinfo、jmap、jhat、jstack使用介绍
16. https://www.jianshu.com/p/8d8aef212b25 jvm 性能调优工具之 jinfo
17. https://www.cnblogs.com/w-wfy/p/6415856.html jvm-java启动参数
18.https://www.jianshu.com/p/314272e6d35b 图解JVM GC过程
19.https://www.jianshu.com/p/1196cf7cb8b8 Minor GC ,Full GC 触发条件是什么
20.https://www.xttblog.com/?p=3623 一个不再被支持的命令jinfo了解一下