【PyTorch】MNIST手写数字识别实践
文章目录
- 一、数据集
- 1.1 数据集介绍
- 1.2 数据集下载和加载
- 1.2.1 在线加载
- 1.2.2 本地加载
- 1.3 数据预览
- 1.4 网络模型搭建
- 1.5 模型训练
- 1.6 模型测试
一、数据集
1.1 数据集介绍
MNIST数据集(官网)被分成两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。
每一个MNIST数据单元由两部分组成:一张包含手写数字的图片和一个对应的标签。每一张图片包含28X28个像素点。我们可以用一个数字数组来表示这张图片:
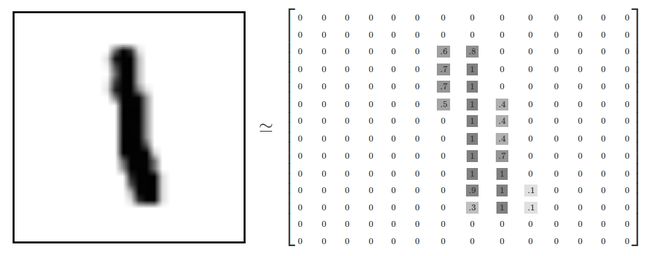
1.2 数据集下载和加载
1.2.1 在线加载
在Pycharm中新建项目并命名为pytorch_mnist,在根目录下新建dataset.py文件用于存放数据集相关代码,代码说明请看注释。完整代码如下:
import torch
from torchvision import datasets, transforms
class Dataset():
def __init__(self):
# 注意这是python 2.0的写法
super(Dataset, self).__init__()
# python 3.0+可省略super()中的参数
# super().__init__()
# 一个批次加载的图片数量
self.batch_size = 64
# 数据预处理
# Compose用于将多个transfrom组合起来
# ToTensor()将像素转换为tensor,并做Min-max归一化,即x'=x-min/max-min
# 相当于将像素从[0,255]转换为[0,1]
# Normalize()用均值和标准差对图像标准化处理 x'=(x-mean)/std,加速收敛的作用
# 这里0.131是图片的均值,0.308是方差,通过对原始图片进行计算得出
# 想偷懒的话可以直接填Normalize([0.5], [0.5])
# 另外多说一点,因为MNIST数据集图片是灰度图,只有一个通道,因此这里的均值和方差都只有一个值
# 若是普通的彩色图像,则应该是三个值,比如Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
self.transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.131], [0.308])])
# 下载数据集
# 训练数据集 train=True
# './data/mnist'是数据集存放的路径,可自行调整
# download=True表示叫pytorch帮我们自动下载
self.data_train = datasets.MNIST('./data/mnist',
train=True,
transform=self.transforms,
download=True
)
# 测试数据集 train=False
self.data_test = datasets.MNIST('./data/mnist',
train=False,
transform=self.transforms,
download=True
)
# 加载数据集
# shuffle=True表示加载时打乱图片顺序,有一定的防止过拟合效果
self.loader_train = torch.utils.data.DataLoader(self.data_train,
batch_size=self.batch_size,
shuffle=True)
# 测试集就不需要打乱了,因此shuffle=False
self.loader_test = torch.utils.data.DataLoader(self.data_test,
batch_size=self.batch_size,
shuffle=False)
这里我们可以尝试对数据集进行加载,在dataset.py继续添加如下代码:
if __name__ == '__main__':
dst = Dataset()
这段代码是对Dataset类进行了实例化,会自动调用Dataset类中的构造方法__init__,并执行数据下载和加载代码。运行效果如下:

数据下载完成后,观察我们的项目目录会发现数据集已经下载到本地了,如下:
看到这里说明你的数据加载已经没问题了,走向成功的第一步已经ok。
1.2.2 本地加载
如果你已经将MNIST下载到了本地,还是用上面的datasets.MNIST来加载数据的话,则需将下载好的数据集按如下目录存放,不然会出问题。

其中data/mnist是在datasets.MNIST填写的下载路径,需要修改dataset.py中的部分代码,将download=False即可,如下:
datasets.MNIST('./data/mnist',
train=True,
transform=self.transforms,
download=False)
好了本地数据集加载已经搞定啦。
1.3 数据预览
前面我们已经下载好了数据集并写好了数据加载器,现在实现数据预览,在项目根目录新建main.py文件,添加如下代码:
import torch
import torchvision
from dataset import Dataset
import cv2
dst = Dataset()
def show():
imgs, labels = next(iter(dst.loader_train))
# 将一个批次的图拼成雪碧图展示
# 此时img的维度为[channel, height, width]
img = torchvision.utils.make_grid(imgs)
# 转换为numpy数组并调整维度为[height, width, channel]
# 因为下面的cv2.imshow()方法接受的数据的维度应该这样
img = img.numpy().transpose(1, 2, 0)
# 因为之前预处理对数据做了标准差处理
# 这里需要逆过程来恢复
img = img * 0.308 + 0.131
# 打印图片对应标签
print(labels)
# 展示图片
cv2.imshow('mnist', img)
# 等待图片关闭
key_pressed = cv2.waitKey(0)
if __name__ == '__main__':
show()
需要注意这里我们使用了opencv的cv2库进行数据预览,需要预先下载该模块,具体下载方法这里就不细说了。
运行结果如下:

看到这里,说明我们的数据加载也没问题了,接下载可以开始构建我们的网络模型了。
1.4 网络模型搭建
这里我们使用两种网络模型,第一种由我们自己定义,第二种借鉴经典网络LeNet5。
在项目根目录下新建文件夹models,并在该目录下新建MyCNN.py文件。这里我们构建一个只有一个卷积层,一个池化层,和三个全连接层的简陋网络。
import torch.nn as nn
class MyCNN(nn.Module):
# 因为分10类,设置n_classes=10
def __init__(self, n_classes=10):
super(MyCNN, self).__init__()
# 关于pytorch中网络层次的定义有几种方式,这里用的其中一种,用nn.Sequential()进行组合
# 另外还可用有序字典OrderedDict进行定义
# 再或者不使用nn.Sequential()进行组合,而是每一层单独定义
# 看具体需求和个人爱好
self.features = nn.Sequential(
# 输入28×28,灰度图in_channels=1
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=7, stride=1, padding=0), # 输出22×22
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 输出11×11
)
self.classifier = nn.Sequential(
nn.Linear(16 * 11 * 11, 160),
nn.Linear(160, 80),
nn.Linear(80, n_classes)
)
# 定义前向传播函数
def forward(self, x):
# 将输入送入卷积核池化层
out = self.features(x)
print(out.shape)
# 这里需要将out扁平化,展开成一维向量
# 具体可惨开view()的用法
out = out.view(out.size()[0], -1)
# 将卷积和池化后的结果送入全连接层
out = self.classifier(out)
return out
if __name__ == '__main':
print(MyCNN())
在models目录下 新建LeNet5.py文件,添加如下代码:
import torch.nn as nn
from collections import OrderedDict
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 这里演示用OrderedDict定义网络模型结果
# 注意每一层的命名不要重复,不然重复的会不起作用
self.conv = nn.Sequential(OrderedDict([
('c1', nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)),
('relu1', nn.ReLU()),
('s2', nn.MaxPool2d(kernel_size=2, stride=2)),
('c3', nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)),
('relu3', nn.ReLU()),
('s4', nn.MaxPool2d(2, 2))
]))
self.fc = nn.Sequential(OrderedDict([
('f6', nn.Linear(16 * 5 * 5, 120)),
('relu6', nn.ReLU()),
('f7', nn.Linear(120, 84)),
('relu7', nn.ReLU()),
('f8', nn.Linear(84, 10)),
]))
def forward(self, x):
x = self.conv(x)
x = x.view(x.size()[0], -1)
x = self.fc(x)
return x
至此,我们的自定义网络模型已经搭建好了,接下来开始训练。
1.5 模型训练
在main.py中添加如下代码:请忽略之前已经写过的代码show()
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from dataset import Dataset
from models.MyCNN import MyCNN
from models.LeNet5 import LeNet5
import cv2
dst = Dataset()
# 模型实例化
my_model = MyCNN()
# my_model = LeNet5()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(my_model.parameters(), lr=1e-4)
# 将模型的所有参数拷贝到到GPU上
if torch.cuda.is_available():
my_model = my_model.cuda()
# 为了节省时间成本,这里我们只训练5个epoch
# 可以根据实际情况进行调整
def train(epoches=5):
for epoch in range(1, epoches + 1):
print('Epoch {}/{}'.format(epoch, epoches))
print('-' * 20)
# 损失值
running_loss = 0.0
# 预测的正确数
running_correct = 0
for batch, (imgs, labels) in enumerate(dst.loader_train, 1):
if torch.cuda.is_available():
# 获取输入数据X和标签Y并拷贝到GPU上
# 注意有许多教程再这里使用Variable类来包裹数据以达到自动求梯度的目的,如下
# Variable(imgs)
# 但是再pytorch4.0之后已经不推荐使用Variable类,Variable和tensor融合到了一起
# 因此我们这里不需要用Variable
# 若我们的某个tensor变量需要求梯度,可以用将其属性requires_grad=True,默认值为False
# 如,若X和y需要求梯度可设置X.requires_grad=True,y.requires_grad=True
# 但这里我们的X和y不需要进行更新,因此也不用求梯度
X, y = imgs.cuda(), labels.cuda()
else:
X, y = imgs, labels
# 将输入X送入模型进行训练
outputs = my_model(X)
# torch.max()返回两个字,其一是最大值,其二是最大值对应的索引值
# 这里我们用y_pred接收索引值
_, y_pred = torch.max(outputs.detach(), dim=1)
# 在求梯度前将之前累计的梯度清零,以免影响结果
optimizer.zero_grad()
# 计算损失值
loss = loss_fn(outputs, y)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 计算一个批次的损失值和
running_loss += loss.detach().item()
# 计算一个批次的预测正确数
running_correct += torch.sum(y_pred == y)
# 打印训练结果
if batch == len(dst.loader_train):
print(
'Batch {batch}/{iter_times},Train Loss:{loss:.2f},Train Acc:{correct}/{lens}={acc:.2f}%'.format(
batch=batch,
iter_times=len(dst.loader_train),
loss=running_loss / batch,
correct=running_correct.item(),
lens=32 * batch,
acc=100 * running_correct.item() / (dst.batch_size * batch)
))
print('-' * 20)
# 保存我们训练好的模型
if epoch == epoches:
torch.save(my_model, 'models/MyModels.pth')
print('Saving models/MyModels.pth')
if __name__ == '__main__':
train()
查看训练结果:

LeNet5的训练结果:
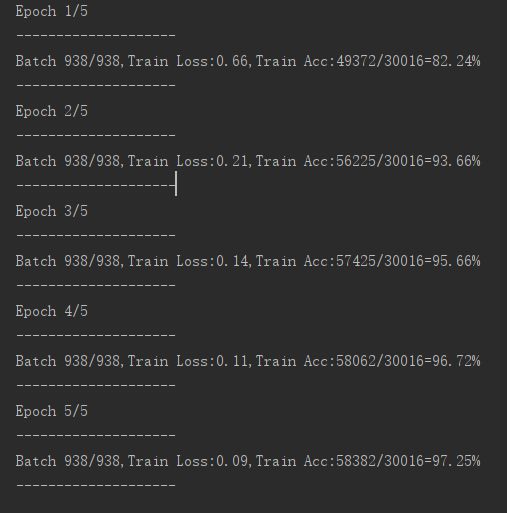
没想到我们自定义的网络模型能训练的准确率比LeNet5高呐(手动滑稽)?
废话不多说,下面开始测试。
1.6 模型测试
在main.py中添加如下代码:请忽略之前已经写过的代码show()和train()
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from dataset import Dataset
from models.MyCNN import MyCNN
from models.LeNet5 import LeNet5
import cv2
dst = Dataset()
def test():
# 加载训练好的模型
model = torch.load('models/MyModels.pth')
testing_correct = 0
for batch, (imgs, labels) in enumerate(dst.loader_test, 1):
if torch.cuda.is_available():
X, y = imgs.cuda(), labels.cuda()
else:
X, y = imgs, labels
outputs = model(X)
_, pred = torch.max(outputs.detach(), dim=1)
testing_correct += torch.sum(pred == y)
if batch == len(dst.loader_test):
print('Batch {}/{}, Test Acc:{}/{}={:.2f}%'.format(
batch, len(dst.loader_test), testing_correct.item(),
batch * dst.batch_size, 100 * testing_correct.item() / (batch * dst.batch_size)
))
if __name__ == '__main__':
# train()
test()
查看测试结果:
![]()
至此,我们的MNIST手写数字识别已经大功告成了。
项目完整代码请移步至我的github查看,如果觉得还不错的话,希望能得到你的Star哟~