The Apache Way - 开源项目
臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣 ...
打住,打住!
百家讲坛,谈古论今,今天我们不讲三国,我们来讲地球脉动 ...
啊,停停停,爬错楼梯了,跑题啦,专业,专业!
好了,离远点,别扯淡了,今天笔者聊点不一样的东西,或许你觉得废话连篇,或许你觉得价值连城,亦或许弃之可惜食之无味。
笔者一直有一个似有似无的习惯,就是每个季度会去挑选一些开源项目去学习和研究。最近一个季度初略涉及多方面,包括:
TBase
企业级分布式 HTAP 数据库管理系统。
Polynote
Polynote 是一种多语言编程 notebook 环境,与 Apache Spark 集成,并为 Scala、Python 和 SQL 提供强大的支持。Polynote 旨在使数据科学家和 AI 研究人员将 Netflix 的机器学习框架与 Python 机器学习和可视化库相集成。
ClickHouse
ClickHouse 是一个开源的面向列的数据库管理系统,能够使用 SQL 查询实时生成分析数据报告。
Apache Doris
Apache Doris 是用于报告和分析的基于 MPP 的交互式 SQL 数据仓库。Doris主要集成了 Google Mesa 和 Apache Impala 的技术。与其他流行的基于 Hadoop 的 SQL 系统不同,Doris 被设计为一个简单且紧密耦合的单个系统,而不依赖于其他系统。
Milvus
Milvus 是一款开源的、针对海量特征向量的相似性搜索引擎。基于异构计算框架设计,成本更低,性能更好。在有限的计算资源下,十亿向量搜索仅毫秒响应。
DataSphere Studio
DataSphere Studio 定位为数据应用开发门户,闭环涵盖数据应用开发全流程。
还有其他一些项目都是持续研究的,这里就不再罗列,否则看起来不雅观。
开源世界
国内最近几年开源项目的确如雨后春笋般涌现,当然是不是春笋不是笔者所能定义的,开源本身就是勇气,需要大家始终如一地鼓励和积极忘我地参与。
但是笔者还是有几句话要说的,既然开源出来,还是要有点态度的,不能只管生不管养。这里有点态度是啥?当然代码本身质量就不说了,笔者认为最起码该有的文档还是不能缺少的,比如项目描述(准确定位)、使用场景和案例、架构图、部署和运维文档、调试和监控手册、用户文档、生态系统、开发文档、How To Contribute、FAQ 等,其实 Spark 和 Flink 项目文档化总体还是不错的,可以参考。
笔者的确遇到不少开源项目,部署完成后,遇到一些问题:
用户名和密码还要去查询数据库或者查看源码
各种依赖问题,无文档说明,需要去查看源码修复
项目定位不清晰,场景夸大
架构随便定义为高可用、高性能、高并发、在线扩容、各种中台等
开源项目里面包含一些非开源的代码,注意 The Apache Way
Issues 和 Bugs 就在那里,稳如磐石
QQ 群和微信群满天飞,私聊很难,私聊之前先来 fork 和 start 项目一下,开个玩笑哈。
最近在研究百度开源的 Doris 项目中,非常感激百度技术人积极主动地解答疑惑,无论是群聊还是私聊都是非常敬业的,再次谢过,Doris 本身也是很棒的 Apache 开源项目,值得研究和应用
开源世界太大,并非笔者所能够妄加论断,聊此一二,正所谓且行且珍惜。
说了那么多,还是要聊点技术的。上面列举了几个开源项目,今天笔者只会挑选 DataSphere Studio 来讲解,因为这个项目本周才开始调研。目前在部署的路上还是遇到不少问题的,所谓一边看源码一边部署,一边修 bug 一边打包,如此反复 ...,不过项目还处于快速迭代更新中。
一站式数据应用开发管理门户
先看一个视频,应该是一个动态 GIF,看完后,对于内行人来说,大致应该就知道产品的功能了,也可以访问 https://github.com/WeBankFinTech/DataSphereStudio 项目,里面有很多演示的动画。
https://github.com/WeBankFinTech/DataSphereStudio/blob/master/images/en_US/readme/DSS_gif.gif
项目概述
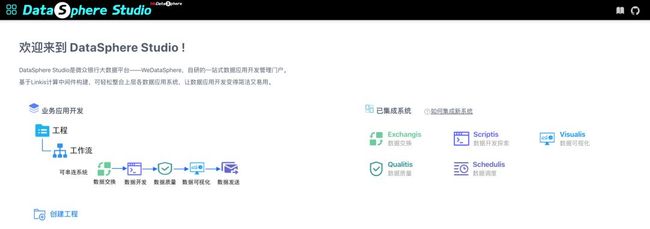
DataSphere Studio 是微众银行大数据平台自研的一站式数据应用开发管理门户,闭环涵盖数据应用开发全流程。在统一的 UI 下,以工作流式的图形化拖拽开发体验,满足从数据导入、脱敏清洗、分析挖掘、质量检测、可视化展现、定时调度到数据输出应用等,数据应用开发全流程场景需求。
基于 Linkis 计算中间件构建,可轻松整合上层各数据应用系统,让数据应用开发变得简洁又易用。并且借助于 Linkis 计算中间件的连接、复用与简化能力,DataSphere Studio 天生便具备了金融级高并发、高可用、多租户隔离和资源管控等执行与调度能力。
Linkis 是什么?
上面项目概述中多次提到 Linkis,这是什么呢?
其实大家看到上面的图,大概就应该知道 Linkis 的功能了。
Linkis 是一个打通了多个计算存储引擎,如 Spark、TiSpark、Hive、Python 和 HBase 等,对外提供统一 REST/WebSocket/JDBC 接口,提交执行 SQL、Pyspark、HiveQL、Scala 等脚本的计算中间件。
其实 Linkis 定义了 AppJoint(应用关节),定义了一套统一的前后台接入规范,可让外部数据应用系统快速简单地接入,成为 DataSphere Studio 数据应用开发中的一环。
比如笔者最近部署的 Qualitis 数据质量管理工具,实现 Qualitis AppJoint,依赖于 Linkis 进行数据计算和质量管理,比如可以对 Hive 表的字段进行各种规则校验。
DataSphere Studio 架构
其实 DataSphere Studio 项目属于一个高度集成的项目,整套产品集成了好几个产品,的确对部署和运维带来不小的挑战,这个就要看项目后续的发展了,目前集成的系统有:
1. Scriptis
开源项目地址:
https://github.com/WeBankFinTech/Scriptis
Scriptis 可以理解为统一 SQL 引擎,类似于 Hue 和 Zeppelin,但是提供了更多的功能。支持在线编写 SQL、Pyspark、HiveQL 等脚本,提交给 Linkis 执行的数据分析Web工具,且支持 UDF、函数、资源管控和智能诊断等企业级特性。
2. Visualis
开源项目地址:
https://github.com/WeBankFinTech/Visualis
基于宜信的开源项目 Davinci 开发的数据可视化 BI 工具,支持拖拽式报表定义、图表联动、钻取、全局筛选、多维分析、实时查询等数据开发探索的分析模式,并做了水印、数据质量校验等金融级增强。Davinci 本身是面向业务人员/数据工程师/数据分析师/数据科学家,致力于提供一站式数据可视化解决方案。
3. Qualitis
开源项目地址:
https://github.com/WeBankFinTech/Qualitis
数据质量管理工具,基于 Spring Boot 开发,依赖于 Linkis 进行数据计算,提供数据质量模型构建,数据质量模型执行,数据质量任务管理,异常数据发现保存以及数据质量报表生成等功能。并提供了金融级数据质量模型资源隔离,资源管控,权限隔离等企业特性,具备高并发,高性能,高可用的大数据质量管理能力。
在 DataSphere Studio 上面开发的工作流可以集成 Scriptis 数据查询、Visualis 图表分析以及 Qualitis 数据质量查看。
4. Azkaban
这一块大家都比较熟悉,业界开源的工作流调度工具,类似的还有 Apache Airflow。DataSphere Studio 集成 Azkaban,便于把用户开发的工作流提交给 Azkaban 进行调度执行。
5. Exchanges
数据交换平台,尚未开源。
使用场景
DataSphere Studio 是一个引领数据应用开发管理方向的开源项目,开源社区目前尚没有同类产品。
DataSphere Studio 官网列举出的适用于以下场景:
1. 正在筹建或初步具备大数据平台能力,但无任何数据应用工具的场景。
2. 已具备大数据基础平台能力,且仅有少数数据应用工具的场景。
3. 已具备大数据基础平台能力,且拥有全部数据应用工具,但工具间尚未打通,用户使用隔离感强、学习成本高的场景。
4. 已具备大数据基础平台能力,且拥有全部数据应用工具,部分工具已实现对接,但尚未定义统一规范的场景。
由于笔者刚开始研究,而且 DataSphere Studio 本身集成度的确不低,所以需要花时间去研究,扩展和落实。
总结
开源世界,还是需要以开源态度去对待,遵循 The Apache way,提供始终如一的高品质软件,进行尊重、诚实和技术为基础的交流。