涅槃重生:KRPC 实现 Impala 的飞跃

据不完全统计,在生产环境中部署 Impala 集群时,大部分大数据工程师也会赠送一套 Kudu 环境,当然用不用另说。如果只部署了 Impala 而没有 Kudu,那应该是一个意外。如果部署了 Kudu,而没有 Impala,说明用户都是高手,喜欢有挑战性的工作。当然如果没有 Impala 和 Kudu,就很正常了,因为可能用了 Presto、Clickhouse 或 Doris 等。
今天笔者给大家带来一篇借助 Kudu 来提升 Impala 稳定性和吞吐量的文章,素材来自 Cloudera 工程师在 Strata Data Conference 2019 大会上分享的主题,《Accelerating analytical antelopes: Integrating Apache Kudu's RPC into Apache Impala》。
本篇文章非常值得读者阅读,请耐心点。
概要
Apache Impala 自 2012 年首次发布以来,已经在各种不同大小的集群上进行了部署和使用。近年来,Impala 部署的规模越来越大,然而 Impala 的 RPC 层(基于 Apache Thrift RPC)可能无法满足需求了。它的同步特性和缺乏连接多路复用使得 Impala 消耗了过多的内核资源,经常导致 Impala 集群的不稳定性和查询失败。
在社区的不懈努力下,Apache Kudu 的 RPC 框架(KRPC)已经成功地集成到 Impala 中。其实 KRPC 最初是为 Kudu 项目开发的,它从头开始构建,以支持跨多路连接的大量节点之间的异步通信,它还支持 TLS 和 Kerberos。
小小剧透一下
一开始先剧透一下,KRPC 与 Thrift RPC 的性能比较,稍微有点打脸的感觉。
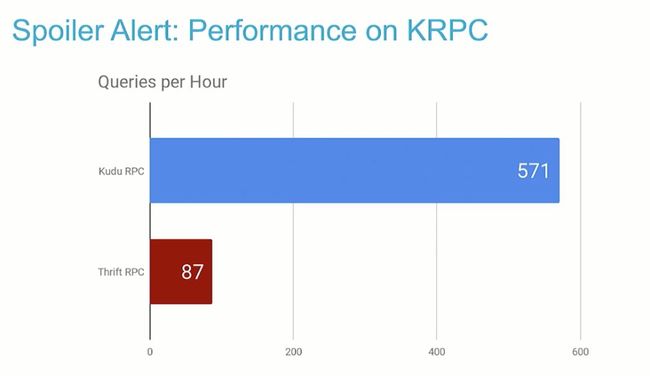
这里笔者提一下,在 CDH 5.15.0 版本中,Impala 默认启用 KRPC,在性能和稳定性方面有了显著的改进,特别是在高并发工作负载的情况下。
Impala 回顾
架构

熟悉 Impala 的读者,这张 slide 应该倒背如流了,笔者再总结一下,照顾到所有读者:
开源
如果不想基于 Cloudera CDH 或 CDP 集成,也可以单独使用 Apache Impala 源代码编译后部署使用。
快
笔者可没有说超级快、最快等,所以 ClickHouse 等技术爱好者不要出来搅局。Impala 是真正基于 MPP 架构的查询引擎,即大规模并行处理技术。另外后端使用 C++ 开发,降低运行负载,并且使用运行时代码生成(LLVM IR),提高效率。
如果简单介绍 MPP 架构的话,即每个节点的 CPU、内存和存储等都是独立的,不存在共享,每个节点都是一个单独的数据库。节点之间的信息和数据交互是通过网络实现,彼此协同工作,通过将数据分布到多个节点上来实现规模数据的存储,以及并行查询处理来提高查询的性能。
灵活性
支持多个存储引擎,比如 HDFS、S3、Kudu 等。
企业级产品
Impala 提供权限授权和认证,以及血缘关系追踪、审计和加密等功能。
可扩展性
多达 400+ 节点数的生产集群规模,支持 Short-Circuit Local Read 本地查询,提升查询性能。
RPC 请求连接数

假设 Impala 集群有 100 个节点,执行 32 个并发查询 SQL,每个 SQL 查询有 50 个 fragments(fragment 指查询 SQL 生成的分布式执行计划中的一个子任务,它包括执行计划的一个子树),那么每个节点的连接数就是 160000。
查询过程
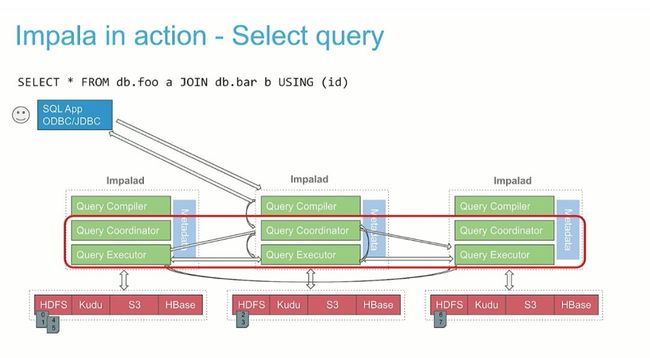
Impalad 包含如下三层:
Query Planner
接受并验证 SQL 查询,将其转换为数学计划,最后将其编译为由 Fragment(片段) 组成的分布式查询计划,并将其移交给 Query Coordinator。
Query Coordinator
Query Coordinator,即查询协调器,将片段分布并协调它们在集群中节点之间的执行。该组件收集所有结果,并将答案发送回客户端。
Query Executor
Query Executor 实际上执行查询的一部分(一个或多个 Fragment),并与其他 Query Executor 协同合作。
为了更好地说明查询流程,笔者使用下面的图进行较为完整的介绍:
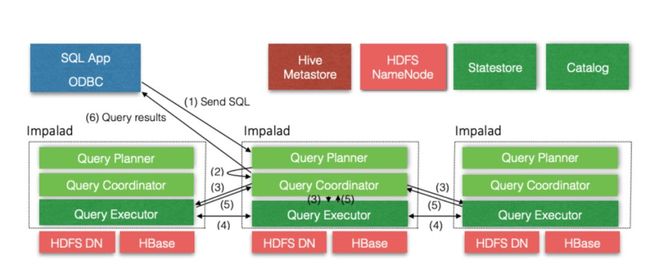
1. 提交查询
用户通过 JDBC 或 ODBC 等方式提交 SQL 查询,可以根据负载均衡策略发送到 Impala 集群的一个 Impalad 节点。
2. 生成单机和分布式的执行计划
接收到查询 SQL 的 Impalad 节点,由 FE 模块处理,通过 Analyser 依次对这个 SQL 执行词法分析、语法分析、语义分析、查询重写等操作,生成该 SQL 的 statement 信息,根据这个信息,Planner 生成单机的执行计划,这个计划是由 planNode 组成的一棵树,也有一些 SQL 优化。将 Planner 的单机执行计划转换成分布式的并行的物理执行计划(由多个 Fragment 组成),Fragment 之间有数据的依赖,新的计划也会加入一些 ExchangeNode 和 DataStreamSinK 信息等。
3. 执行分布式计划
由 BE 模块处理生成的分布式物理执行计划,将 Fragment 根据数据的分区信息发配到不同的 Impalad 节点上执行,每个 Impalad 节点接收到 Fragment 并执行处理。
4. Fragment 之间的数据依赖
每一个 Fragment 的执行输出通过 DataStreamSink 发送到下一个 Fragment,由下一个 Fragment 的 ExchangeNode 接收,Fragment 运行的过程中不断的向 Coordinator 节点汇报当前的运行状态。
5. 结果汇总
用于查询的 SQL 通常会有一个单独的 Fragment 用于结果的汇总,这个 Fragment 只会在Coordinator 中运行,将多个 Impalad 的最终执行结果汇总,然后转换成最终用户查询的数据。
6. 读取查询的结果
用户读取查询的结果,然后关闭本次查询。
查询计划相关术语
Query Plan
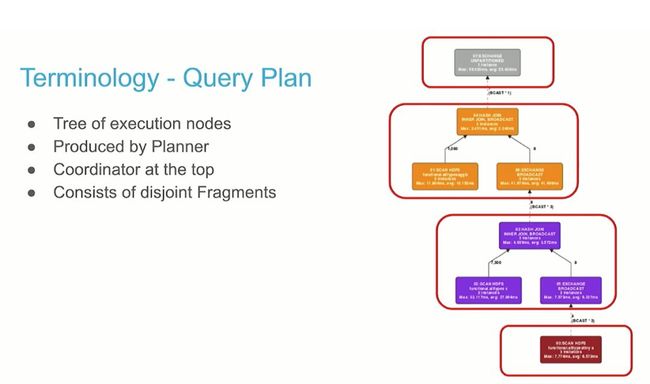
这部分介绍了 Impala 的查询计划,笔者额外总结一下工作:
将查询的文本表示解析为逻辑计划
优化执行计划
最后将计划划分为多个 fragment,以便在 Impala 集群中的不同节点上并行运行
Plan Fragment
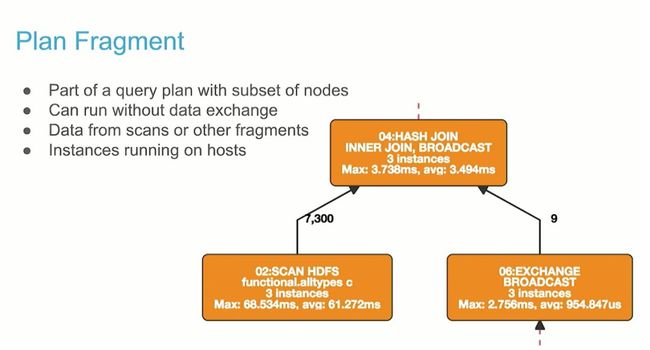
Query Planner 的最后一个任务是将优化的计划划分为 Plan Fragment。每个 Plan Fragment 分布到集群中的一个或多个 Impalad 节点。
Fragment Instance
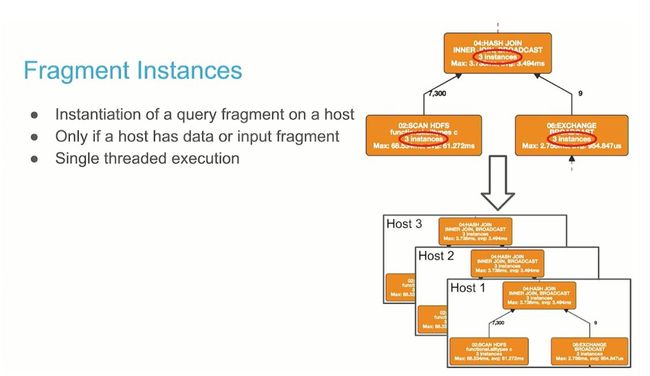
分配到 Plan Fragment 的 Impalad 节点,实例化 Plan Fragment
仅当节点有数据或接收到执行计划分配的 Fragment 时
单线程执行 Plan Fragment
Channel 和 RPC
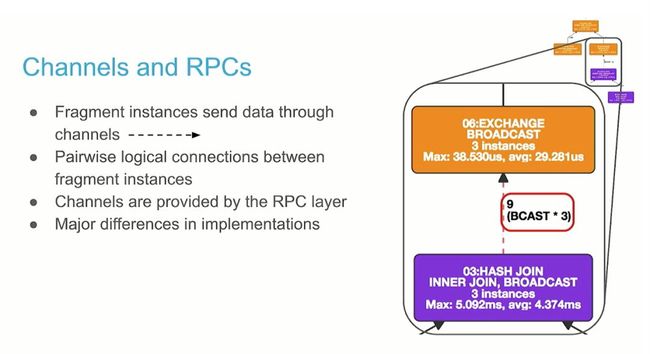
Fragment 实例通过 channel 发送查询 fragment
Fragment 实例之间的成对地逻辑连接
Channels 是通过 RPC 层提供的,实现通信
通信模式
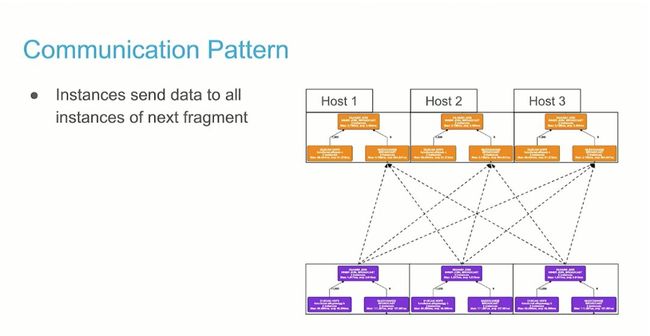
Fragment 实例发送数据到下一个 Fragment 的所有实例上。
连接数问题总结
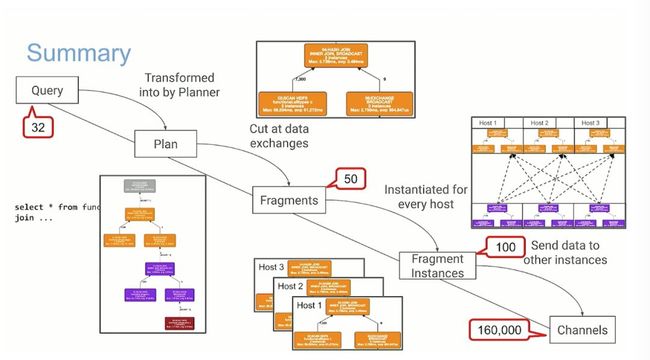
如果上面介绍的 Impala 一些专业术语比较难懂的话,读者结合这张图再次理解一遍,就应该清晰很多了,并且能够得到笔者前面抛出的 160000 这个数据,真正明白其中的含义。
可伸缩性挑战
Thrift RPC 伸缩性挑战
Impala 守护程序(Impalad)之间的通信通过使用 Apache Thrift 库的远程过程调用(RPC)进行的。处理查询时,Impalad 经常必须与集群中的所有其他节点交换大量数据,例如在分区中进行 hash join 等。
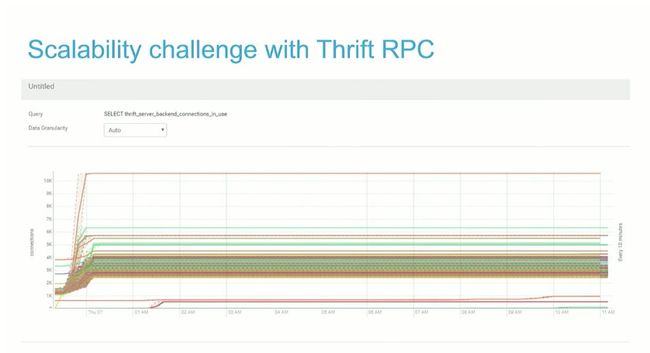

根据连接数的变化,很明显看出 RPC 存在的问题:
集群中的连接数为 O(#fragments * #host^2)
1. 存在过多的资源消耗
2. 容易存在建立连接失败
3. KDC 瓶颈(开启 Kerberos 情况下)
Thrift RPC 只支持同步的 RPC
节点之间的 Channels == TCP
连接 Thrift 服务模型中每个连接的线程。
超过系统线程限制
如果 Impala 集群存在大量的并发查询,线程数会达到系统的限制,给查询服务和系统带来不稳定性,以及较差的系统调度行为。
Thrift RPC
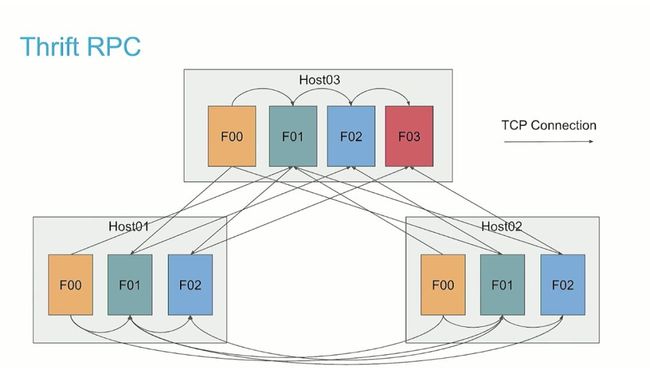
Impala 之前的 RPC 实现仅支持同步 Thrift RPC。为了模拟异步 RPC,在每个查询片段(即 fragment)线程池中创建了 RPC 线程。RPC 服务器实现还使用了 thread-per-connection 模型。由于此实现的体系结构限制,每个主机上的 RPC 线程数与以下乘积成比例增长:
(Number of Hosts) x (Query Fragments per Host)
回到了笔者前面提到的问题,对于具有 32 个并发查询的 100 个节点的 Impala 集群,每个查询有 50 个片段,这将导致每个节点有 100 x 32 x 50 = 160,000 个连接和线程。而在整个集群中,将有 1600 万个连接。
此外,每个 RPC 线程都必须打开并维护自己的连接。没有任何机制可以支持通过单个连接在两台计算机之间并行处理并行请求,这意味着每个查询的每个片段都必须维护与集群中所有其他主机的连接。为了避免创建过多的连接,Impalad 实施了连接缓存来回收网络连接。但是,连接缓存无法很好地处理失效的连接,这会导致意外的查询失败,甚至导致错误的结果。
随着数据和工作负载的增长,越来越多的节点被添加到 CDH 集群中,CDH 5.15.0 版本之前的 Impalad 遇到了可扩展性的限制。在高负载下创建的 RPC 线程和网络连接的数量过多会导致不稳定和糟糕的 Impala 性能。通常,管理员需要调优操作系统参数,以避免 Impalad 在运行高度并发的工作负载时超过默认的系统限制,即使在一个中等大小的集群(例如,100个节点)中也是如此。即便经过管理员优化,表现仍然不佳。
为了解决上述问题,社区经过不断探索,决定在内部 RPC 上采用 Apache Kudu 项目的 RPC 实现(即 KRPC)。
KRPC

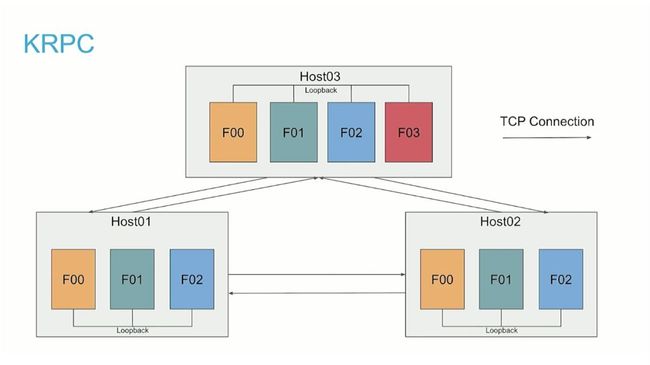
从 CDH 5.15 版本开始,对某些 RPC,Impala 采用 Kudu RPC 实现
Kudu RPC (KRPC) 支持异步 RPC,这样每个连接就不需要一个线程。主机之间的连接是长期的。两个主机之间的所有 RPC 在同一个已建立的连接上进行多路复用,这大大减少了主机之间的 TCP 连接数量,并将连接数量与查询片段的数量解耦。
Impala 线程
通过 Thrift RPC 和 KRPC 对比,结果显而易见。
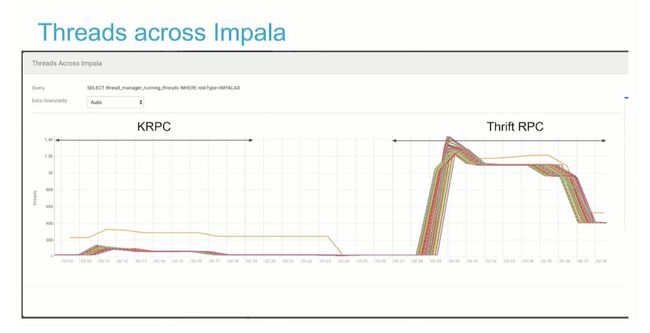
评估
为了验证真实的生产环境效果,我们对具有 135 个节点的集群中的 TPC-DS 10 TB 数据量进行了评估,使用不同的并发级别进行验证。集群中的每个节点都具有 88个 vcore 和 264 GB 的内存,操作系统为 CentOS。
对于 KRPC 和 Thrift RPC 进行操作,我们都测量了吞吐量(每小时查询)和查询成功率(已完成并没有任何错误的查询百分比)。该集群的设置如下:
一个节点用作专用协调器 Coordinator,但不充当 Executor
132 个节点作为 Executor
一个节点用于运行 Catalog daemon
一个节点用于运行 Statestore
操作系统的文件句柄缓存大小配置为 131 K,该值大于系统默认值,以防止 HDFS Namenode 成为瓶颈。在实验运行之间重新启动集群,并且每次迭代都对所有查询进行了初步的预热操作以引入元数据,这为结果的可重复性确保了一致的环境,测试结果如以下各部分所示。
稳定性
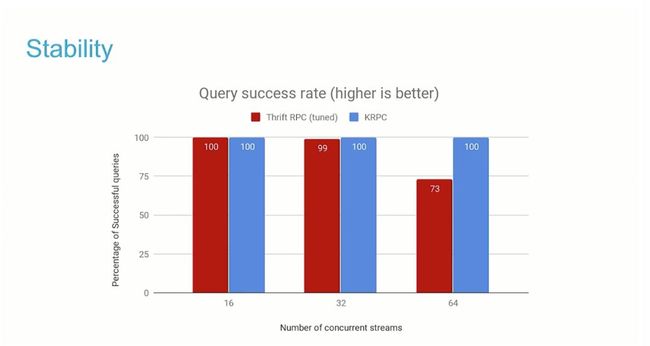
使用 Thrift RPC 运行这些基准测试需要调整操作系统参数,以增加资源使用量。如果不进行此调整,则查询成功率会大大降低。
对于 KRPC,可以立即获得 100% 的成功率,而不必更改这些操作系统参数。而对于 Thrift RPC,并发数增加,查询成功率降低。
吞吐量
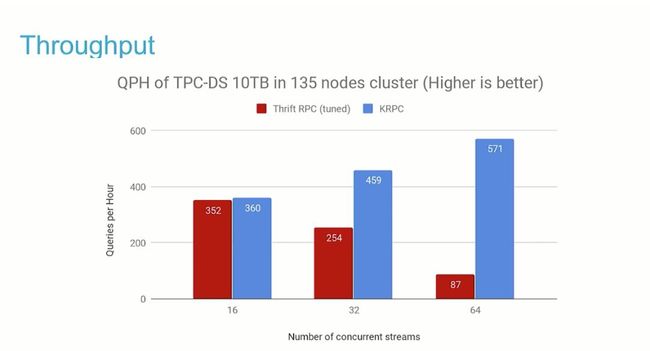
如上图所示,使用 KRPC 时,32 个并发的 TPC-DS 查询流显示出 2 倍的吞吐量。对于 64 个并发流,KRPC 提升效果甚至更为显着(6倍多)。
经验总结
这部分是 Cloudera 团队通过将 Apache Kudu 的 RPC 集成到 Apache Impala 中所积累的经验总结,感兴趣的读者,请继续阅读,笔者不再详解。
Impala 的 RPC 项目改造

90-90 法则

这里解释一下,90-90 法则,笔者习惯称为九九定律,是计算机编程和软件工程领域的一个有名的法则,即:
(开发软件时)前 90% 的代码要花费 90% 的开发时间,剩余的 10% 的代码要再花费 90% 的开发时间。
参考
https://conferences.oreilly.com/strata/strata-ca-2019/public/schedule/detail/73012


你若喜欢,点个在看哦
