知识储备:Java面试知识储备
应聘软件开发职位前必须知道的事
总之,机会是留给又准备的人,把可预见的事情做好,把未来控制在自己所能控制的范围内。
面试资料的准备
1、作品:(微博 + 学讯通 + 校园神器)
2、证书:CET-6
3、个人简历
4、成绩单
面试的准备
面试公司及面试单位的准备
面试的方式
- 笔试
1)不会答的题目也尽量要写好解题思路、流程甚至是伪代码
2)把会答的题目写清楚(有的公司可能会因为一道题而要你)
3)在纸上写程序 - 电话面试
1) 自我介绍
2) 会让你提问 - 面试
常见的面试问题
1)介绍你自己
2)对公司了解有多少
3)你的优点与缺点
4)五年内的打算(与这份工作相关的目标,而不是“转行”)
Java基础知识
- JDK与JRE的区别与各自的作用
jre:Java runtime envrionment运行时环境,里面包含了Java运行环境jvm,用来执行Java程序对应的字节码文件,以及一些Java程序运行时所依赖的类库对应的class文件。
jdk:Java开发工具包,jdk不仅包括了jre,同时还包括了Java编译环境,将就java文件编译成jvm可执行的二进制文件。 - CLASSPATH环境变量的作用
CLASSPATH环境变量配置的是Java程序编译和运行会所依赖的一些类库路径,我想Java程序就是根据这个环境变量链接到相应的类库实现编译和运行的 - Java与C++程序在编译和运行上的区别
任何高级语言程序都会变成机器码(二进制)以后,才会被计算机识别的,C++、Java语言也一样
C++程序编译后,生成特定机器上可以直接运行的二进制文件;
Java程序编译后,先生成的是字节码文件(也就是class文件),字节码文件再在虚拟机上运行。(这也就是Java语言的一大特性:跨平台性,不是因为Java语言本身是跨平台的,而是JVM是跨平台的) - 什么是JVM及其工作原理
1、JVM:Java虚拟机负责执行Java程序编译好的字节码文件。
2、Java语言之所以被称为一种跨平台的语言,并不是因为Java语言本身是跨平台的,而是因为这个JVM,Java虚拟机,就像Java程序和操作系统的一个中间平台,可以屏蔽不同系统之间的差异,因此可以做到跨平台性。
3、jvm里面也提供了相应的垃圾回收机制,这时相对于C++程序的一个改进吧,它防止了程序员因为忘记手动释放内存而导致的内存溢出 - Java的内存回收机制(delete语句)
Java中的垃圾回收机制是相对于C++的一种改进,它避免了程序员因为忘记释放内存而导致的内存溢出,Java中的句JVM提供了
相应的垃圾回收机制,能自动回收相应的内存 - Java内存机制(java中的数据存储)
Java中的内存分为两种:栈内存空间还有堆内存空间。
1、栈内存:栈内存主要存放的是函数中定义的一些基本类型的变量啊、对象的引用啊。在定义的时候为这些变量啊、引用啊分配内存空间;超出了作用域范围之后,释放相应的占内存空间。
2、堆内存:new关键字创建的对象存储在堆内存中的,而且java提供了相应的垃圾回收机制,用于回收对象所占用的堆内存空间。系统在确认某个对象是不再被引用的对象时,会自动调用相应的方法(finalize())释放对象所占用的堆内存空间 - Java中变量及其作用范围
Java中变量可以分为三种类型:静态变量、成员变量、局部变量
静态变量是指在类中用static修饰的变量,它属于这个类,生存周期由类来决定
成员变量是在类中没有用static关键字修饰的变量,它的生存周期是由它们所属的对象决定的
局部变量指的是方法中的变量,有相应的作用域。 - Java中的数据类型
Java中的数据类型可以分为两大类:8种原生数据类型和引用类型
原生数据类型:byte short int long float double boolean char
java中对原生数据类型储存的是值本身,而对引用类型存储的是对象的地址,对象则保存在堆存储区中。 - Java原生数据类型及其对应的包装类
Java5.0提供了原生数据类型与对应包装类的自动装箱和自动拆箱功能。Byte Short Integer Long Float Double Boolean Character - java中的引用和C++中指针的区别
本质上,Java中的引用和C++中的指针都是想通过这种引用或者指针的机制来找到内存中想要操作的目标。总的来说,Java采用引用的方式方式更安全,但是没有C++指针那么灵活。
区别的话主要有:C++指针可以看成是Int类型的数据,可加可减,引用存放的是对象的地址;Java中有相应的内存回收机制,而C++没有,要手动回收。 equals和 == 的区别
“==”用到原生数据类型的比较时,比较值本身是否相等。用到引用类型的比较时,比较这两个对象的引用是否相等,也就是这两个引用是否指向同一个对象。
equals方法的初始功能比较这两个引用所指向的对象是否相同。因为equals方法是Object方法的,其它对象都可以重写equals,譬如说String类就重写了equals方法,则比较的是String值本身是否相等。Java中静态成员的特点
Java中静态成员有三种,静态成员变量、静态方法、静态代码块
通过static关键字修饰,特点为:
在类加载的时候,就一同创建和初始化
一个类只有一份;
不属于某个特定对象,类的对象都能访问抽象类与接口的区别
抽象类:用关键字abstract修饰的类;一个类含有抽象方法这个类一定是抽象类;抽象方法只有定义没有实现;抽象类中可以有具体方法;抽象方法的访问修饰符不能是private的;子类继承抽象类要么实现抽象类的全部抽象方法,要么还是定义成抽象类。
接口:用interface定义接口;里面只能含有抽象方法一个类可以实现多个接口;接口中的成员变量只能是public static final类型的(注意:类可以实现多个接口,若不成员变量不定义static的话万一实现的接口有重名的呢?? + 如果接口的成员变量不定义成final,就表示可以被接口中的方法调用,但是abstract方法只有申明没有实现怎么访问呢)、方法的话修饰符都是public abstract类型的;方法的一个类实现了接口要么实现该啊必须是接口的全部方法,要么定义成抽象类。Java中的几种内部类
定义在类内部的类成为内部类,有四种内部类
静态内部类:类内部用static修饰的类,外部类在加载的时候也会加载静态内部类
成员内部类:外部类创建对象的时候才加载该成员内部类
局部内部类:定义在方法中的类
匿名内部类:没有名字,实现某个接口Java访问控制修饰符
(子类的访问修饰符权限小于父类的网文修饰符权限)
Java中提供了四类访问修饰符:private default protected public
这四类修饰符修饰的成员,对它们的访问权限不一样:

private修饰的成员的话只能该类本身访问
default(默认没有访问修饰符)修饰的成员可以被类本身 + 同一包下的类访问
protected修饰的成员可以被类本身 + 同一包中下的类访问 + 子类访问
public修饰的成员的话可以被所有类访问int和Integer的区别
int是原生数据类型,它一般被保存在JVM的栈存储区中。
Integer是int的包装类,在创建时会在开辟一个堆存储区。int和integer之间可以自动装箱和拆箱各原生数据类型的取值范围
int:占4个字节,32位,第一位为符号位,负数用1和补码形式表示,例如(正数—0变1,1变0—加1)-2的31次方–2的31次方-1
(0123表示八进制的123;0x123表示16进制的123)
long:占8个字节,64位,-2的63次方–2的63次方-1
float i = 0.1 编译通不过,0.1默认是double,应改成float i= 0.1f或者float i= (float)0.1
(char 占两个字节 范围为0-2的16次方 可以与int short byte long类型相互转换,可以用来储存汉字,因为都是使用Unicode编码方式)字符串字符串池的理解
字符串在程序中会被很频繁的使用,为了避免频繁地创建和释放对象,JVM引入了字符串池的概念,当执行字符串赋值时(String s1 = “dengqi”),首先会在字符串对象池中查找是否有该字符串,有则不再池中创建该对象,而是直接返回池中对象的引用;无则在字符串对象池中创建该对象
使用new关键字创建字符串对象都会在池中还有堆中创建,并返回堆中字符串对象的引用。String和StringBuffer的区别
1、使用String类创建的字符串对象有一个特点,那就是不变性(也就说明共享性好),也就是说如果对String字符串修改的话会创建新的String字符串对象,然后返回新创建的字符串对象的引用;
2、StringBuffer类创建的字符串对象,如果对它进行修改的话不会创新新的对象的,而是在分配给原来的StringBuffer堆内存空间里面修改的;
所以说如果经常要对一个字符串进行修改:譬如说插入、删除、追加操作的话使用StringBuffer创建String字符串更适合一些。一维数组的三种初始化方式
第一种:
int[] a = new int[4];
a[0] = ?;
第二种:
int[] a = {1, 2, 3, 4};
第三种:
int a = new int[]{1, 2, 3, 4};
注意:
①:数组是引用类型而不是输入八种基本数据类型
②:使用new int[5]只是创建了一个数组实例,并未给这些元素赋值,路new Object[5]只是创建了一个Object数组实例,而并没有创建五个Object实例集合(Collection)的概念
集合和数组有点类似,数组是用来储存相同类型的数据,而集合可以存放任意的数据类型(对象)。
集合框架体系:
Collection—Set(HashSet)—SortedSet(TreeSet)
Collection—List(ArrayList + LinkedList)
Map—SortedMap
Collection:根接口,没有直接的实现类
列表(List):有序 + 可重复
集合(Set):无序 + 不可重复
SortedSet:排好序的Set
映射Map:键值对
SortedMap:排好序的MapArrayList的实现原理
(简单理解:底层Object类型的数组,有点类似于线性表中顺序存储结构的顺序表)
1、构造方法:底层调用的是new Object[initialCapacity(10)];
2、add方法:首先调用ensureCapacity,判断ArrayList中的数据是否大于ArrayList的长度;如果大于了,则创建一个新的Object数组,大小为原Object数组大小的1.5倍 + 1,在将原数组拷贝到新的数组中。LinkedList的实现原理
(简单理解:底层是双向链表实现的)
1、构造方法:即构造一个空的双向链表:header.previous = header.next = header
2、Entry可以看成是一个节点(Object + previous + next)
3、add操作即为双向链表的添加操作;其中往LinkList中添加的数据不是原数据本身的引用,而是一个Entry对象。该Entry对象的结构为:
Class Entry{
Object Data;//添加的真正数据
Entry previous;
Entry next;
}
即LinkedList中所维护的是一个个Entry对象HashSet的实现原理
不能添加重复的元素,add能否将数据添加成功取决于条件hashCode()与equals的关系
①、同一对象的hashcode在依次执行过程中的多次调用,都是一样的
②、对于两个对象,如果equals,则hashcode相同
③、对于两个对象,如果not equals,则不要求hashcode相同
常用于Set中添加元素。
因为Set集合不允许添加重复元素,应该用equals判断。Iterator迭代器模式
迭代器(游标)模式概念:提供一种方法访问一个容器对象中各个元素,而不需要暴露该容器对象的内部细节。
对于Java中的集合来说,iterator模式分离了集合对象的遍历行为,抽象出一个迭代类来负责,这样既可以不暴露集合的内部实现,又能实现对集合中元素的访问。
迭代器模式的四中角色
1、容器角色:负责提供创建具体迭代器角色的接口(例如Set,list.iterator)
2、具体的容器角色:负责提供实现创建具体迭代器角色的接口(例如HashSet中hashSet.iterator,该具体的迭代器角色与容器的结构有关)
3、迭代器角色(Iterator):定义了访问和遍历元素的接口
(next(),haveNext())
4、具体的迭代器角色:该具体迭代器角色与容器的结构有关,根据具体的容器角色实现了相应的遍历算法。
迭代器使用的具体步骤是:获得具体容器对象对应的迭代器(iterator)——用hasNext作为迭代的循环条件——用next取得具体容器对象中的元素,同时指向下一个对象中的元素往TreeSet集合中添加元素需要注意些什么(即比较器)
TreeSet集合实现了SortedSet接口,里面的元素是有序存放的,TreeSet使用add方法添加元素时,需要元素是按一定顺序添加进去。对于一些基本数据类型来说,有默认的次序;但是对于自定义的类来说, 需要集成Comparator重写compare方法来实现自定义的比较规则。
Set set = new TreeSet(new Comparator(){});策略模式详细介绍(比较器就使用了这种策略模式)
策略模式:可以想象在现实生活中,去旅游的多中方式。
1、Strategy pattern模式体现面向对象向编程的两个重要原则:
①封装变化的概念(例如比较器Comparator,如何实现比较就是一个会变化的量,应该封装起来)
②编程中使用接口,而不是使用对接口的实现(多态的概念,不接受具体的实现类,而是接受什么就是什么)
2、策略模式的定义:
策略模式定义了一组算法,并将每一种算法封装起来,使它们可以互换。策略模式让算法与使用它的客户端相互独立,互补影响。
3、策略模式的意义:大大提高了软件的可重用性
4、策略模式的三种角色
①抽象的策略角色:是一个接口或者抽象类,里面定义了一组算法的公共接口(例如Comparator中的compare(a, b))
②具体的策略角色:继承或者实现了抽象的策略角色,并且实现自己的算法(例如编写自己的MyComparator和自定义的比较方法)
③环境角色:里面有一个抽象策略角色的引用,用于接收具体的策略角色,最终客户端会根据这个引用调用具体的算法。(new出那个比较器,在add元素时就会根据这个比较器来添加元素)。HashMap映射的常见方法
1、put(key, value)(有相同key则会覆盖) + get(key)(没有则返回的value为空)
2、keySet()返回Map中key的集合,由于key不允许重复,因此返回类型是Set。values()返回的是Map中值得集合,因为value可以重复,即返回类型为collections
3、遍历map的两种常见方式
①:keySet + Iterator
②:Map.Entry entrySet(),返回值为Set,获得Map对应的Entry对象以后,就能直接获得Map中key和value的值了,也就是说Map.Entry维护了两个信息:key + value的信息HashSet的底层实现方式
1、底层实现是HashMap
2、HashSet的add(e)方法底层是:map.add(e,PRESENT(一个Object类型的对象)),即HashSet使用add添加元素时,实际上是往HashSet底层维护的HashMap的key,而map的value即是一个没有用的Object。HashMap的底层实现方式
1、构造方法new HashMap()底层实现实际上是一个Entry类型 的数组:Entry[] table = new Entry[初始大小:16],而Entry类型的信息会维护key和value两个信息
2、Entry是什么呢?是一个内部类,实现了Map.Entry class Entry{ K key; V value; Entry next; }
3、put方法的实现 里面的数据存储是采用hash散列的方式存放的,因此会维护一个“负载因子(0.75)”,也就是当数据占据内存的75%时,会开辟新的Entry数组存放数据 put的实现步骤为:
①、首先根据key的hashCode计算出一个位置,这个位置是将Entry对象准备存放的位置
②、如果该位置没有对象存在,则直接将对象放入数组中。
③、如果该位置有对象存在,则将该要添加的entry对象与这个位置的Entry链表元素进行比较,如果没有相同的Entry对象,则将该对象放到数组中,然后将数组位置上以前存在的Entry链表放到新增Entry对象的后面。泛型基本基本知识详解
泛型概念概括:泛型即变量类型的参数化,只有在创建对象的时候才知道泛型的类型。
使用泛型的好处:使用泛型在添加元素的时候,就确定了元素的类型,从里面取对象的时候就可以避免手动强制类型转换了 + 在代码编译的时候没有出现警告,在运行的时候就不会出现类型转换的错误。
泛型高阶:
①:[T extends List]则T只能是List的子类型(默认是T extend Object),是定义的时候使用。
②:[? extends List],是初始化的时候使用JFrame基础知识介绍
1、JFrame是创建GUI的基础类,可以把它想象成一个容器或者是一个窗口,里面包含了很对组件(创建的步骤为:new一个JFrame对象 + 设置其关闭行为 + 设置外观、布局等 + 添加组件 + 为组建添加监听)
2、JTextField文本框和JTextArea文本域:JTextField是一个单行输入框;JTextArea是一个多行输入框,enter键换行AWT事件介绍
1、事件:譬如说一个按钮的点击、鼠标的滑动这些称之为一个事件,是一个对象(事件类在Java中已经定义好了)。产生事件之后,会将这个事件对象向传递给相应的事件处理器
2、事件源:产生事件的对象
3、事件处理器:与事件源关联的类,能接收并处理事件的方法(会被自动调用)
譬如说按钮的点击:首先按钮通过addXXXListener方法关联一个事件处理器类,点击一个按钮,会产生一个事件对象ActionEvent,并传递给与该按钮关联的事件处理器(实际上是一个方法),该事件处理器通过这个传进来的事件对象获得事件源及事件的信息,并且处理相应的事件。观察者模式介绍
1、观察者模式的定义
定义了一种一对多的依赖关系,多个观察者(可以有很多与事件源相关联的事件处理器)同时监听某一个对象(事件源Button),当这个对象发生变化的时候(事件源Button被点击,产生了事件对象),会通知所有的观察者对象,让它们自动执行相应的操作。
2、观察者模式的四中角色
①抽象的主题角色:定义了一组接口,用于添加、删除和通知(notify)观察者执行更新(update)的方法
②具体的主题角色(Button):继承了抽象的主题角色,实现了具体的添加、删除和通知所有观察者执行更行的方法(有一个List集合用于保存添加进来的观察者 + 通知观察者执行更新方法的实现:遍历list集合中所有的观察者,执行自己的更新方法)
③:抽象的观察者角色(ActionListener):为具体的观察者角色定义了一个接口,提供了一个update更新自己的接口
④具体的观察者角色(实现了ActionListener的监听器):实现了具体的更新方法,当接收到具体主题角色发送过来的通知之后,会执行自己的更新方法。
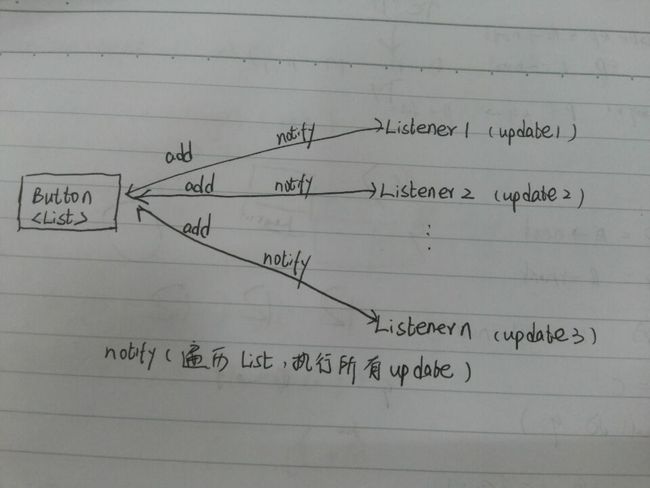
观察者模式与Button监听器类比:Button是一个具体的主题角色,里面维护了一个监听器对象的List列表,执行addXXXListener()方法实际上是将这个监听器添加到Button所维护的List列表中;点击按钮操作相当于调用了Button中的notify方法,首先会生成一个事件对象,notify方法会将这个事件对象传递给相应的监听器,然后遍历List中所有的监听器执行update方法实现更新。try、catch、finally的执行顺序
1、一般来说finally中执行的内容是关闭连接啊、关闭流对象啊这些操作,所以不管try、catch中会不会出现异常、有没有return语句,都会执行finally中的内容,再去执行try、catch中的return语句。
2、如果在finally中已经有return语句了,就不会再去执行try、catch中的return语句了
3、finally和try、catch、finally之外不能同时又return语句;try、catch都有return语句的话,try、catch、finally之外也不能
要有return语句。方法重写与方法重载
1、方法重写:子类继承父类,在子类中可以重写父类的方法,子类中重写的方法,它的返回值啊、方法名称啊、参数名称啊、参数个数啊这些都要与父类的一样;唯一可以不同的就是函数体吧。
2、方法重写的一些细节
①、super关键字调用父类的方法
②、父类中方法的访问修饰符权限要比子类的大(譬如如果父类方法的访问修饰符为private的话,该方法就不能被重写了,因为子类不能访问父类的private成员)
③、子类中抛出的异常不能多于父类中抛出的异常,范围也不能超出。
④、体现的是面向对象中继承的思想
3、方法重载:在同一类中里面的方法名相同、但是参数不同,参数不同可以使参数的类型、个数、或者是顺序可以不一样。但是其它都一样而只是返回类型不一样的话不能算是重载。譬如说我们常见的构造方法的重载,根据传进来的参数来调用相应的构造方法。
4、方法重载的一些细节:
① 、对权限没有要求
②、体现面向对象多态的原则数据库范式:
1、范式引入的目的:设计关系型数据库的时候遵循这些范式准则的话能够很好地减少数据库冗余信息,从而设计出合理的关系型数据库。
2、数据库里面有6大范式:1FN、2FN、3FN、BCFN、4FN、5FN
3、各类范式的简单介绍:
①、1FN:属性不可再分;也就是要求关系数据库的属性要有原子性。不满足第一范式的数据库,不是关系数据库。
②、2FN:在1FN的基础上要求非主属性完全依赖于主键。加入设置[1,2]为主键,确定非主属性3,但实际上只是2就能唯一的确定非主属性3,这就称之为非主属性不完全依赖(部分依赖)主键。
不符合2FN的关系型数据库很有可能会造成删除异常、插入异常和修改异常
③、3FN:在2FN的基础上消除传递依赖,即要求关系中不包含已在其它关系已包含的非主关键字信息;可以引入外键来消除传递依赖吧。
④、BCFS:在3FN的基础上要求主键的属性只能是一个
⑤、4FN: 在3FN的基础上要求把同一表内的多对多关系删除。
⑥、5FN:从最终结构重新建立原始结构。
java常见的基础选择题
异常
1、分类
①、checked exception(非运行时异常),继承Exception,编译时就会检查
②、unchecked exception(运行时异常),继承RuntimeException,运行时才检查、常见的运行时异常有:ClassCastException、IndexOutofBoundException、NullPointerException、ArrayStoreException、BufferOverflowException
2、异常的两种处理方式
①、try catch finally
②、throw new exception()Constructor
普通的类方法是可以和类名同名的,和构造方法唯一的区分就是,构造方法没有返回值。- 下列属于关系型数据库的是(AB)
A. Oracle B MySql C IMS D MongoDB
解答:IMS(Information Management System )数据库是IBM公司开发的两种数据库类型之一;
一种是关系数据库,典型代表产品:DB2;
另一种则是层次数据库,代表产品:IMS层次数据库。
非关系型数据库有MongoDB、memcachedb、Redis等 - java中的用户线程(User Thread)和守护线程(Daemon Thread)
总结:java中的线程分为两种:用户线程和守护线程;守护线程可以理解成视为用户线程提供服务的;JVM中只要有一个非守护线程在工作的话,守护线程就会全部工作;但是如果非守护线程全部结束的话,守护线程也会结束,譬如说GC就是一个典型守护线程的一个应用; - java创建对象的四种方式
1、用new语句创建对象,这是最常见的创建对象的方法。
2、运用反射手段,调用java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
3、调用对象的clone()方法。
4、运用反序列化手段,调用java.io.ObjectInputStream对象的 readObject()方法。
(1)和(2)都会明确的显式的调用构造函数 ;(3)是在内存上对已有对象的影印,所以不会调用构造函数 ;(4)是从文件中还原类的对象,也不会调用构造函数。 -
- ArrayList list = new ArrayList(20);中的list扩充几次(0次)
解析:这里有点迷惑人,大家都知道默认ArrayList的长度是10个,所以如果你要往list里添加20个元素肯定要扩充一次(扩充为原来的1.5倍),但是这里显示指明了需要多少空间,所以就一次性为你分配这么多空间,也就是不需要扩充了。
- ArrayList list = new ArrayList(20);中的list扩充几次(0次)
- 下面哪些是对称加密算法()
A DES B AES C DSA D RSA
答案:AB
解析:常用的对称加密算法有:DES、3DES、RC2、RC4、AES
常用的非对称加密算法有:RSA、DSA、ECC
使用单向散列函数的加密算法:MD5、SHA - 新建一个流对象,下面哪个选项的代码是错误的?()
A)new BufferedWriter(new FileWriter(“a.txt”));
B)new BufferedReader(new FileInputStream(“a.dat”));
C)new GZIPOutputStream(new FileOutputStream(“a.zip”));
D)new ObjectInputStream(new FileInputStream(“a.dat”));
答案:B
解析:请记得13题的那个图吗?Reader只能用FileReader进行实例化。 - 静态代码块、构造代码块、构造方法的执行顺序
执行次序:父类静态代码块—子类静态代码块—父类构造代码块—子类构造代码快—父类构造方法—子类构造方法
class HelloA {
public HelloA() {
System.out.println("HelloA");
}
{ System.out.println("I'm A class"); }
static { System.out.println("static A"); }
}
public class HelloB extends HelloA {
public HelloB() {
System.out.println("HelloB");
}
{ System.out.println("I'm B class"); }
static { System.out.println("static B"); }
public static void main(String[] args) {
new HelloB();
}
}输出为:
static A
static B
I'm A class
HelloA
I'm B class
HelloB- Java中所有定义的基本类型或对象都必须初始化才能输出值
public static void main (String[] args){
String s;
System.out.println("s=" + s);
}程序编译错误,改成int类型也是一样
11. 序列化Serializable、transient关键字小结
1、序列化Serializable概念
序列化是将对象以字节流的形式保存,并在以后可以通过反序列化还原该对象(即将内存中对象保存在文件中)
2、实现序列化必须实现Serializable对象
3、如果被序列化的对象中含有其他对象,那么他内部包含的对象也会被序列化
4、只序列化非静态成员变量,不可序列化的成员变量可以使用transient关键字
5、序列化对象:ObjectOutput;对应的方法为writeObject(Object) + 反序列化对象:ObjectInput;对应的方法:readObject
6、transient关键字只能修饰变量,而不能修饰方法和类;
7、一个静态变量不管是否被transient修饰,均不能被序列化;
12. 子类调用父类构造函数的次序
总结:子类没有显示调用父类构造函数(super),不管子类构造函数是否带参数都默认调用父类无参的构造函数,若父类没有则编译出错
Android常见笔试题
- 内存回收机制
A、程序员必须创建一个线程来释放内存 (错误,由gc自动回收)
B、 内存回收程序负责释放无用内存(正确、对象没有引用指向是)
C、 内存回收程序允许程序员直接释放内存(错误,不允许的,是靠gc自动回收)
D、 内存回收程序可以在指定的时间释放内存对象(gc空闲时才回收,不能自动回收)
- Runtime Exception
ArithmeticException + IllegalArgumentException + NullPointerException + BufferUnderflowException - Math.round(11.5)等于多少(12). Math.round(-11.5)等于多少(-11):round四舍五入
- intent能传递的数据类型
Serializable + charsequence(StringBuffer) + Parcelable(另一种序列化方式) + Bundle - 下列属于SAX解析xml文件的优点的是:不用事先调入整个文档,占用资源少(SAX:事件驱动的解析方式 + 每次只加载一行XML数据)
- 在android中使用Menu时可能需要重写的方法有onCreateOptionsMenu() + onOptionsItemSelected()
- SELECT @@IDENTITY:identity不可能为负数
- ContenValues他和Hashtable比较类似,也是负责存储一些名值对,但是他存储的名值对当中的名是String类型,而值都是基本类型
- android的动画分类的有:Tween(可以对view实现一系列的转换,例如:移动、渐变、伸缩、旋转) + Frame(帧动画是一系列的图片按顺序显示)
- DVM指dalivk的虚拟机.每一个Android应用程序都在它自己的进程中运行,都拥有一个独立的 Dalvik虚拟机实例.而每一个DVM都是在Linux 中的一个进程,所以说可以认为是同一个概念.
- assets:Android除了提供/res目录存放资源文件外,在/assets目录也可以存放资源文件,而且/assets目录下的资源文件不会在R.java自动生成ID,所以读取/assets目录下的文件必须指定文件的路径;
主要放置多媒体等数据文件。 - res/raw:存放通用的文件, 该文件夹内的文件将不会被编译成二进制文件,按原样复制到设备上
- android NDK的理解正确的是(ABCD)
A、 NDK是一系列工具的集合
B、 NDK 提供了一份稳定、功能有限的 API 头文件声明。
C、 使 “Java+C” 的开发方式终于转正,成为官方支持的开发方式
D、 NDK 将是 Android 平台支持 C 开发的开端 - android中常用的四个布局是framlayout(放置在屏幕的左上角并覆盖),linenarlayout,relativelayout和tablelayout
- java.io包中的objectinputstream和objectoutputstream类主要用于对对象(Object)的读写
- id 中service的实现方法是:startservice和bindservice
- android的数据存储的方式sharedpreference,文件,SQlite,contentprovider,网络
- 应用程序结构是:
Linux Kernel(Linux内核)、Libraries(系统运行库或者是c/c++核心库)、Application Framework(开发框架包)、Applications (核心应用程序
Service的生命周期
1.Service常用生命周期回调方法如下:
onCreate() 该方法在服务被创建时调用,该方法只会被调用一次,无论调用多少次startService()或bindService()方法,
服务也只被创建一次。 onDestroy()该方法在服务被终止时调用。
2. Context.startService()启动Service有关的生命周期方法onStart() 只有采用Context.startService()方法启动服务时才会回调该方法。该方法在服务开始运行时被调用。
多次调用startService()方法尽管不会多次创建服务,但onStart() 方法会被多次调用。
3. Context.bindService()启动Service有关的生命周期方法
onBind()只有采用Context.bindService()方法启动服务时才会回调该方法。该方法在调用者与服务绑定时被调用,当调用者与服务已经绑定,多次调用Context.bindService()方法并不会导致该方法被多次调用。
onUnbind()只有采用Context.bindService()方法启动服务时才会回调该方法。该方法在调用者与服务解除绑定时被调用。
备注:
1. 采用startService()启动服务Intent intent =new Intent(DemoActivity.this, DemoService.class);
startService(intent);
2.Context.bindService()启动
Intent intent =new Intent(DemoActivity.this, DemoService.class);
bindService(intent, conn, Context.BIND_AUTO_CREATE);
//unbindService(conn);//解除绑定