Elasticsearch-CrossClusterSearch(CCS)
Elasticsearch-CrossClusterSearch(CCS)
1 概述
cross-cluster search,简称为CCS,即跨集群搜索。可以使得节点当做联邦客户端跨多个集群查询。不同于老版本的tribe node参与到远程集群的方式,CCS使用轻量级方式连接到远程集群来执行联邦查询。
具体来说,CCS通过在cluster state中配置远程集群,且仅连接到远程集群中有限数量的几个节点。 每个远程集群由一个别名和一个种子节点列表索引。当注册远程集群后,将从一个种子节点中检索其集群状态,以便最多选择3个网关节点进行连接,以作为将来的跨集群搜索请求的一部分。
跨集群搜索请求仅包含从协调节点到先前选择的远程节点的单向连接。 可以通过节点的属性来标记应选择哪些节点进行连接。集群中配置了远程集群的每个节点都会连接到一个或多个网关节点(种子节点只能配置为网关节点的子集),并使用它们联合搜索请求访问远程集群。
2 配置
2.1 概述
配置时,可使用cluster settings来动态增改(这种方式可通过集群中所有节点访问远程集群),或通过本地elasticsearch.yml配置(这种方式只能使得改了本地配置文件的那些节点来做federated查询)。
2.2 elasticsearch.yml方式
使用本地化方式时,在CCS节点的elasticsearch.yml中配置:
search:
remote:
cluster_one:
seeds: 127.0.0.1:9300
cluster_two:
seeds: 127.0.0.1:9301
2.3 cluster settings
使用cluster settings时,命令如下:
PUT _cluster/settings
{
"persistent": {
"search": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}
删除cluster_three命令如下:
PUT _cluster/settings
{
"persistent": {
"search": {
"remote": {
"cluster_three": {
"seeds": null
}
}
}
}
}
2.4 CCS配置详解
- search.remote. c l u s t e r a l i a s . s k i p u n a v a i l a b l e 默 认 值 f a l s e 。 设 置 跳 过 失 联 节 点 {cluster_alias}.skip_unavailable 默认值false。设置跳过失联节点 clusteralias.skipunavailable默认值false。设置跳过失联节点{cluster_alias},具体可见这里
- search.remote.connections_per_cluster
默认值3。可以连接每个远程集群最大节点数。 - search.remote.initial_connect_timeout
默认值30s。当CCS节点启动时等待建立远程连接的超时时间。 - search.remote.node.attr
如果设为gateway,则只会连接那些设置了node.attr.gateway: true属性的网关节点。可将协调节点设为网关节点。 - search.remote.connect
默认true,集群中每个节点都可以作为CCS客户端来连接远程集群。可通过设某个节点该属性为false来禁止作为CCS客户端。
3 执行跨集群搜索
3.1 普通CCS
在使用CCS时,注意需要在indexName前加前面配置的clusterName别名,例子如下:
GET /twitter,cluster_one:twitter,cluster_two:twitter/_search
{
"query": {
"match": {
"user": "kimchy"
}
}
}
注意,这里的第一个twitter是指该节点所在的集群,而cluster_one:twitter和cluster_two:twitter是其中两个我们配置的远程集群的别名。
查询返回结果如下:
{
"took": 150,
"timed_out": false,
"num_reduce_phases": 4,
"_shards": {
"total": 3,
"successful": 3,
"failed": 0,
"skipped": 0
},
"_clusters": {
"total": 3,
"successful": 3,
"skipped": 0
},
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "twitter",
"_id": "0",
"_score": 2,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
},
{
"_index": "cluster_one:twitter",
"_id": "0",
"_score": 1,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
},
{
"_index": "cluster_two:twitter",
"_id": "0",
"_score": 1,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
}
]
}
}
注意看查询结果的"_index"字段,本地集群的不带前缀,而远程集群的依然带了远程集群的别名及冒号作为index的前缀。
3.2 跳过不可用节点
默认情况,CCS目标节点必须全部可用,否则会导致整个搜索失败,返回空。
以下例子展示了忽略失联的集群cluster_two不影响其他正常集群搜索结果的例子:
先设置cluster_two可以在失联时被跳过
``java
PUT _cluster/settings
{
“persistent”: {
“search.remote.cluster_two.skip_unavailable”: true
}
}
执行CCS:
```java
GET /cluster_one:twitter,cluster_two:twitter,twitter/_search
{
"query": {
"match": {
"user": "kimchy"
}
}
}
结果如下,可以看到在设置skip后2个集群本地、cluster_one搜索成功并返回结果,而cluster_two被记录到失败但不影响整个查询:
{
"took": 150,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"failed": 0,
"skipped": 0
},
"_clusters": {
"total": 3,
"successful": 2,
"skipped": 1
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "cluster_one:twitter",
"_type": "_doc",
"_id": "0",
"_score": 1,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
},
{
"_index": "twitter",
"_type": "_doc",
"_id": "0",
"_score": 2,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
}
]
}
}
4 CCS网络调优
4.1 概述
从ES7.x开始,可以通过在搜索时在Request body配置ccs_minimize_roundtrips,默认为true。
4.2 ccs_minimize_roundtrips为true
4.2.1 概述
此时,ES会在执行CCS时将最小化协调节点和远程集群之间的网络往返开销。这样做可以减少网络延迟对搜索速度的影响。但在包括scroll-分页查询和inner hits-嵌套查询的大查询请求时,ES无法降低网络往返。
4.2.2 原理
- 发送一个CCS请求查询本地集群(
europe)以及远程usa、amea集群的posts index。该请求会先到达本地集群(europe),该集群的一个协调节点接收并解析该请求:
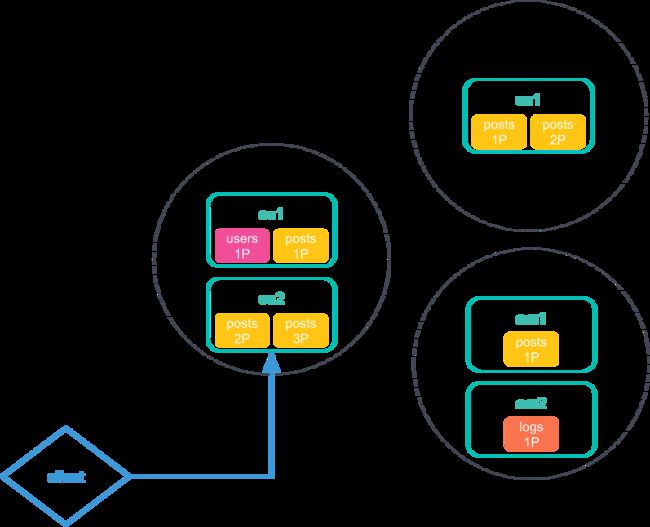
- 该协调节点发送一个搜索请求到其他所有集群,包括本地集群和远程集群,然后所有集群开始独立执行该次搜索请求:
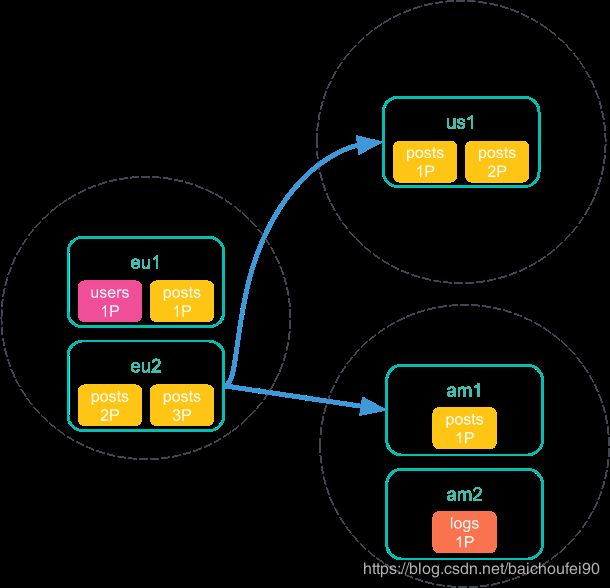
- 每个远程集群在搜索完成后发送结果给
europe集群的协调节点:
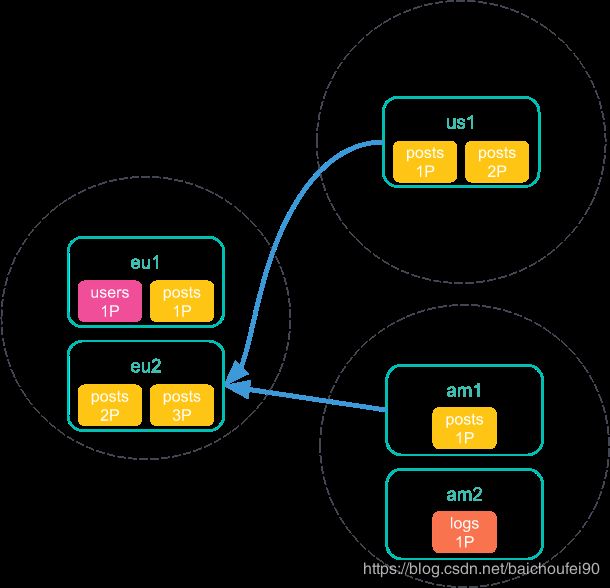
- 在协调节点收集完所有集群的搜索结果后,返回聚合后的最终结果给CCS发起客户端:

显然,该次CCS请求中,客户端只和本地集群的协调节点交互,而由本地集群的协调节点负责本地、远程集群交互。
4.3 ccs_minimize_roundtrips为false
4.3.1 概述
在包括scroll-分页查询和inner hits-嵌套查询的大查询请求时,ES将多个传出和传入请求发送到每个远程集群。 尽管通常速度较慢,但此方法可能适用于低延迟的网络。
4.3.2 原理
- 发送一个CCS请求查询本地集群(
europe)以及远程usa、amea集群的posts index。该请求会先到达本地集群(europe),该集群的一个协调节点接收并解析该请求:

- 该协调节点发送一个search shards API(会返回搜索index需要涉及到的节点和分片信息)到其他所有远程集群:

- 远程集群将search shards API结果返回给该协调节点,响应信息包含了该次CCS请求会执行相关的索引和分片信息:
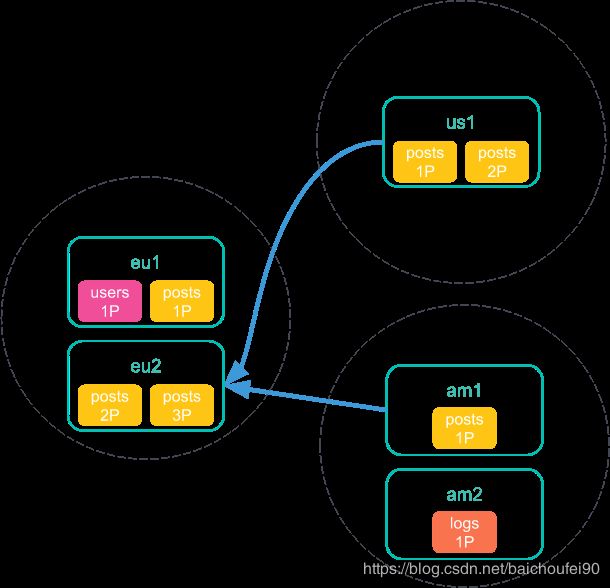
- 本协调节点收到search shards API的响应信息后,将搜索请求发给所有这些分片,然后每个分片独立执行搜索请求(注意这一步和
ccs_minimize_roundtrips为true时不同,那个是发送搜索请求到所有集群而不是精确到分片):
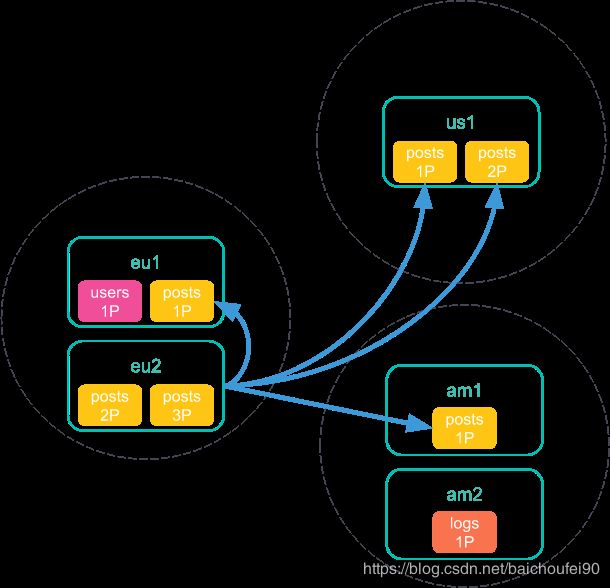
- 每个分片搜索完毕后将结果返回给该协调节点:
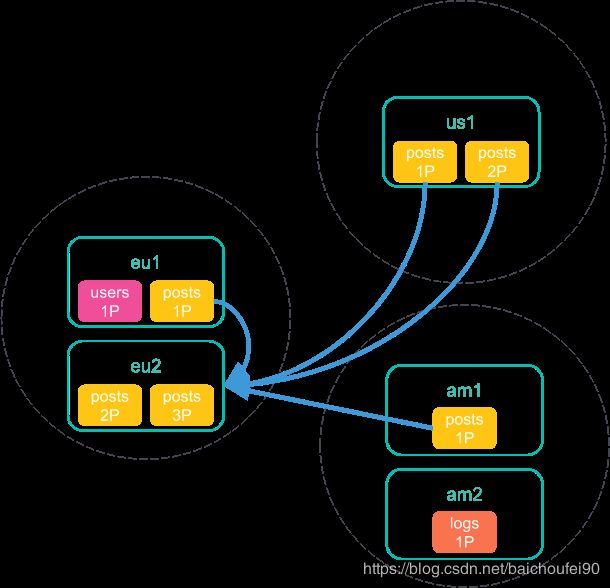
- 在协调节点收集完所有集群的搜索结果后,返回聚合后的最终结果给CCS发起客户端:
对比ccs_minimize_roundtrips为true时,本CCS多了协调节点给所有远程集群发送一个search shards API(会返回搜索index需要涉及到的节点和分片信息)到其他所有远程集群的步骤,并利用此信息精确发送搜索请求给相关分片。
5 检索远程集群Minimize network roundtrips信息
参考Remote Cluster Info API
5 CCS RestAPI
参考文档
- cross-cluster search
- cross-cluster configuring