MySQL · 引擎特性 · InnoDB undo log
一 序
本文根据《MYSQL运维内参》第11章整理。上一篇整理了Innodb redo log, 本篇继续整理undo log,崩溃恢复下一篇整理。
Undo log是InnoDB MVCC事务特性的重要组成部分。当我们对记录做了变更操作时就会产生undo记录,Undo记录默认被记录到系统表空间(ibdata)中,但从5.6开始,也可以使用独立的Undo 表空间。
在Innodb当中,INSERT操作在事务提交前只对当前事务可见,Undo log在事务提交后即会被删除,因为新插入的数据没有历史版本,所以无需维护Undo log。而对于UPDATE、DELETE,责需要维护多版本信息。 在InnoDB当中,UPDATE和DELETE操作产生的Undo log都属于同一类型:update_undo。(update可以视为insert新数据到原位置,delete旧数据,undo log暂时保留旧数据)。
上面提了MVCC,举个UNdolog作用例子:
Session1(以下简称S1)和Session2(以下简称S2)同时访问(不一定同时发起,但S1和S2事务有重叠)同一数据A,S1想要将数据A修改为数据B,S2想要读取数据A的数据。没有MVCC只能依赖加锁了,谁拥有锁谁先执行,另一个等待。但是高并发下效率很低。InnoDB存储引擎通过多版本控制的方式来读取当前执行时间数据库中行的数据,如果读取的行正在执行DELETE或UPDATE操作,这是读取操作不会因此等待行上锁的释放。相反的,InnoDB会去读取行的一个快照数据(Undo log)。在InnoDB当中,要对一条数据进行处理,会先看这条数据的版本号是否大于自身事务版本(非RU隔离级别下当前事务发生之后的事务对当前事务来说是不可见的),如果大于,则从历史快照(undo log链)中获取旧版本数据,来保证数据一致性。而由于历史版本数据存放在undo页当中,对数据修改所加的锁对于undo页没有影响,所以不会影响用户对历史数据的读,从而达到非一致性锁定读,提高并发性能。
另外,如果出现了错误或者用户手动执行了rollback,系统可以利用undo log中的备份将数据恢复到事务开始之前的状态。与redo log不同的是,磁盘上不存在单独的undo log 文件,他存放在数据库内部的特殊段(segment)中。下面我们来看看文件结构。
二 文件结构
回滚段的管理,也有个入口位置专门存储回滚段的管理信息,就是第6个页面(page5).这个页面专门用来存储事务相关信息的。主要包括:
| Macro | bytes | Desc |
|---|---|---|
| TRX_SYS | 38 | 每个数据页都会保留的文件头字段 |
| TRX_SYS_TRX_ID_STORE | 8 | 持久化的最大事务ID,这个值不是实时写入的,而是256次递增写一次 |
| TRX_SYS_FSEG_HEADER | 10 | 指向用来管理事务系统的segment所在的位置 |
| TRX_SYS_RSEGS | 128 * 8 | 用于存储128个回滚段位置,包括space id及page no。每个回滚段包含一个文件segment(trx_rseg_header_create) |
在5.7版本中,回滚段既可以在ibdata中,也可以在独立undo表空间,或者ibtmp临时表空间中,一个可能的分布如下图所示。图片来自taobao.mysql
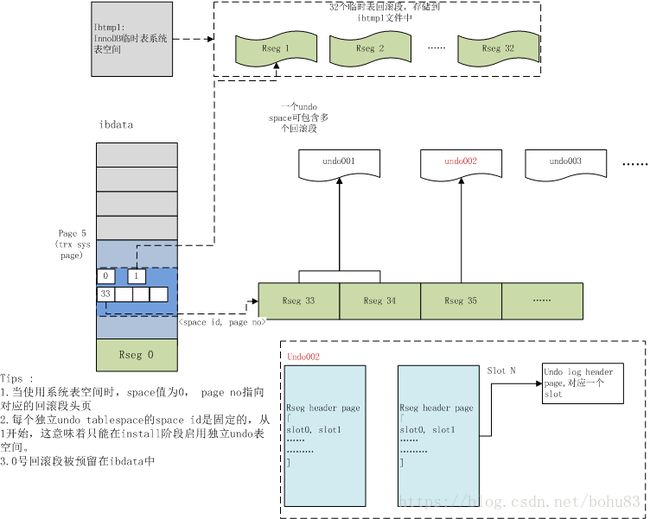
上图展示了基本的Undo回滚段布局结构,其中:
rseg0预留在系统表空间ibdata中;
rseg 1~rseg 32这32个回滚段存放于临时表的系统表空间中;
rseg33~ 则根据配置存放到独立undo表空间中(如果没有打开独立Undo表空间,则存放于ibdata中)
2.1关键结构体
InnoDB最多可以创建128个回滚段,而每个回滚段(也就是上面TRX_SYS_RSEGS数组中元素)需要单独的Page来维护其拥有的undo slot,Page类型为FIL_PAGE_TYPE_SYS。描述如下:
| Macro | bytes | Desc |
|---|---|---|
| TRX_RSEG | 38 | 保留的Page头 |
| TRX_RSEG_MAX_SIZE | 4 | 回滚段允许使用的最大Page数,当前值为ULINT_MAX |
| TRX_RSEG_HISTORY_SIZE | 4 | 在history list上的undo page数,这些page需要由purge线程来进行清理和回收 |
| TRX_RSEG_HISTORY | FLST_BASE_NODE_SIZE(16) | history list的base node |
| TRX_RSEG_FSEG_HEADER | (FSEG_HEADER_SIZE)10 | 指向当前管理当前回滚段的inode entry |
| TRX_RSEG_UNDO_SLOTS | 1024 * 4 | undo slot数组,共1024个slot,值为FIL_NULL表示未被占用,否则记录占用该slot的第一个undo page |
回滚段头页的创建参阅函数 trx_rseg_header_create 源码在innobase/trx/trx0rseg.cc
根据上面的信息,可以整理出所有回滚段组织架构。如下所示
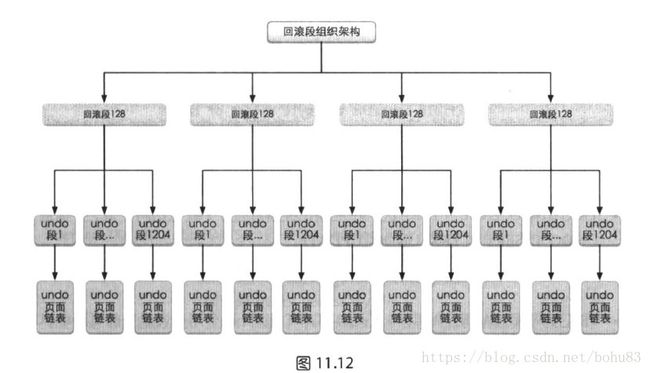
INNODB支持的回滚段总共有128*1024=131072个,TRX_RSEG_UNDO_SLOTS数组的元素每一个元素对应一个页面,这个页面对应一个段,页面号就段首页的页面号。在每一个事务开始的时候,都会分配一个rseg,就是从长度128的数组中,根据最近使用情况,找一个邻近位置的rseg,再这个事务的生命周期内,被分配的rseg就会被这个事务所使用。
在事务要存储回滚记录的时候,就会从1024个slot中,根据类型(插入还是更新)找到空闲的槽作为自己的undo段。如果已经申请过同类型的槽,则直接使用。否则就需要新创建一个段。并将段首号写入到这个rseg对应的空闲槽中。这样结构就与事务具体结合起来了。当然找不到空闲位置,就报异常了。
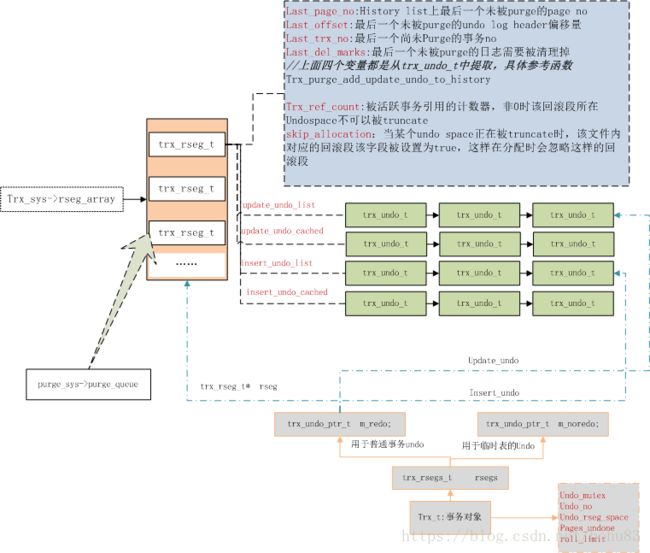
所有回滚段都记录在trx_sys->rseg_array,数组大小为128,分别对应不同的回滚段;
rseg_array数组类型为trx_rseg_t,用于维护回滚段相关信息;
每个回滚段对象trx_rseg_t还要管理undo log信息,对应结构体为trx_undo_t,使用多个链表来维护trx_undo_t信息;
事务开启时,会专门给他指定一个回滚段,以后该事务用到的undo log页,就从该回滚段上分配;
事务提交后,需要purge的回滚段会被放到purge队列上(purge_sys->purge_queue)。
trx_rseg_t 源码在innobase/include/trx0rseg.h
/** The rollback segment memory object */
struct trx_rseg_t {
/*--------------------------------------------------------*/
/** rollback segment id == the index of its slot in the trx
system file copy */
ulint id;
/** mutex protecting the fields in this struct except id,space,page_no
which are constant */
RsegMutex mutex;
/** space where the rollback segment header is placed */
ulint space;
/** page number of the rollback segment header */
ulint page_no;
/** page size of the relevant tablespace */
page_size_t page_size;
/** maximum allowed size in pages */
ulint max_size;
/** current size in pages */
ulint curr_size;
/*--------------------------------------------------------*/
/* Fields for update undo logs */
/** List of update undo logs */
UT_LIST_BASE_NODE_T(trx_undo_t) update_undo_list;
/** List of update undo log segments cached for fast reuse */
UT_LIST_BASE_NODE_T(trx_undo_t) update_undo_cached;
/*--------------------------------------------------------*/
/* Fields for insert undo logs */
/** List of insert undo logs */
UT_LIST_BASE_NODE_T(trx_undo_t) insert_undo_list;
/** List of insert undo log segments cached for fast reuse */
UT_LIST_BASE_NODE_T(trx_undo_t) insert_undo_cached;
/*--------------------------------------------------------*/
/** Page number of the last not yet purged log header in the history
list; FIL_NULL if all list purged */
ulint last_page_no;
/** Byte offset of the last not yet purged log header */
ulint last_offset;
/** Transaction number of the last not yet purged log */
trx_id_t last_trx_no;
/** TRUE if the last not yet purged log needs purging */
ibool last_del_marks;
/** Reference counter to track rseg allocated transactions. */
ulint trx_ref_count;
/** If true, then skip allocating this rseg as it reside in
UNDO-tablespace marked for truncate. */
bool skip_allocation;
};
图片来自taobao.mysql
三 分配回滚段
当开启一个读写事务时(或者从只读事务转换为读写事务),我们需要预先为事务分配一个回滚段:对于只读事务,如果产生对临时表的写入,则需要为其分配回滚段,使用临时表回滚段(第1~32号回滚段),函数入口:trx_assign_rseg(源码在/innobase/trx/trx0trx.cc) -->trx_assign_rseg_low(/innobase/trx/trx0trx.cc)-->get_next_noredo_rseg(/innobase/trx/trx0trx.cc)。
在MySQL5.7中事务默认以只读事务开启,当随后判定为读写事务时,则转换成读写模式,并为其分配事务ID和回滚段,调用函数:trx_set_rw_mode(innobase/trx/trx0trx.cc) -->trx_assign_rseg_low --> get_next_redo_rseg
源码如下:
/******************************************************************//**
Get next redo rollback segment. (Segment are assigned in round-robin fashion).
@return assigned rollback segment instance */
static
trx_rseg_t*
get_next_redo_rseg(
/*===============*/
ulong max_undo_logs, /*!< in: maximum number of UNDO logs to use */
ulint n_tablespaces) /*!< in: number of rollback tablespaces */
{
trx_rseg_t* rseg;
static ulint redo_rseg_slot = 0;
ulint slot = 0;
slot = redo_rseg_slot++;
slot = slot % max_undo_logs;
/* Skip slots alloted to non-redo also ensure even distribution
in selecting next redo slots.
For example: If we don't do even distribution then for any value of
slot between 1 - 32 ... 33rd slots will be alloted creating
skewed distribution. */
if (trx_sys_is_noredo_rseg_slot(slot)) {
if (max_undo_logs > srv_tmp_undo_logs) {
slot %= (max_undo_logs - srv_tmp_undo_logs);
if (trx_sys_is_noredo_rseg_slot(slot)) {
slot += srv_tmp_undo_logs;
}
} else {
slot = 0;
}
}
#ifdef UNIV_DEBUG
ulint start_scan_slot = slot;
bool look_for_rollover = false;
#endif /* UNIV_DEBUG */
bool allocated = false;
while (!allocated) {
for (;;) {
rseg = trx_sys->rseg_array[slot];
#ifdef UNIV_DEBUG
/* Ensure that we are not revisiting the same
slot that we have already inspected. */
if (look_for_rollover) {
ut_ad(start_scan_slot != slot);
}
look_for_rollover = true;
#endif /* UNIV_DEBUG */
slot = (slot + 1) % max_undo_logs;
/* Skip slots allocated for noredo rsegs */
while (trx_sys_is_noredo_rseg_slot(slot)) {
slot = (slot + 1) % max_undo_logs;
}
if (rseg == NULL) {
continue;
} else if (rseg->space == srv_sys_space.space_id()
&& n_tablespaces > 0
&& trx_sys->rseg_array[slot] != NULL
&& trx_sys->rseg_array[slot]->space
!= srv_sys_space.space_id()) {
/** If undo-tablespace is configured, skip
rseg from system-tablespace and try to use
undo-tablespace rseg unless it is not possible
due to lower limit of undo-logs. */
continue;
} else if (rseg->skip_allocation) {
/** This rseg resides in the tablespace that
has been marked for truncate so avoid using this
rseg. Also, this is possible only if there are
at-least 2 UNDO tablespaces active and 2 redo
rsegs active (other than default system bound
rseg-0). */
ut_ad(n_tablespaces > 1);
ut_ad(max_undo_logs
>= (1 + srv_tmp_undo_logs + 2));
continue;
}
break;
}
/* By now we have only selected the rseg but not marked it
allocated. By marking it allocated we are ensuring that it will
never be selected for UNDO truncate purge. */
mutex_enter(&rseg->mutex);
if (!rseg->skip_allocation) {
rseg->trx_ref_count++;
allocated = true;
}
mutex_exit(&rseg->mutex);
}
ut_ad(rseg->trx_ref_count > 0);
ut_ad(!trx_sys_is_noredo_rseg_slot(rseg->id));
return(rseg);
}- 采用round-robin的轮询方式来赋予回滚段给事务,如果回滚段被标记为skip_allocation(这个undo tablespace太大了,purge线程需要对其进行truncate操作),则跳到下一个;
- 选择一个回滚段给事务后,会将该回滚段的rseg->trx_ref_count递增,这样该回滚段所在的undo tablespace文件就不可以被truncate掉;
- 临时表回滚段被赋予trx->rsegs->m_noredo,普通读写操作的回滚段被赋予trx->rsegs->m_redo;如果事务在只读阶段使用到临时表,随后转换成读写事务,那么会为该事务分配两个回滚段。
只读事务与读写事务的区别在于他们随后会不会记录redo log(undo也是需要redo来保护的)。
undo生命周期
在进行分配的时候,MySQL会从第一个回滚段开始轮询所有的回滚段,寻找当前不会被purge线程truncate掉的回滚段,以后该事务用到的undo page都会从这个undo段来分配。
然后在undo slot当中记录自己的事务ID,将该回滚段的count增加,来标识该回滚段中仍记录着未提交数据,防止被purge线程truncate掉。
最后,如果是临时表回滚段,则不记录redo,如果是普通读写操作,则会记录redo。
另外,如果一个事物,在只读阶段使用了临时表回滚段,之后又转变成了读写事物,那么两个回滚段都会被使用。
事物提交之后,需要purge的undo段都会放到purge队列上。
四 使用undo段
当产生数据变更时,我们需要使用Undo log记录下变更前的数据以维护多版本信息。insert 和 delete/update 分开记录undo,因此需要从回滚段单独分配Undo slot。函数入口:trx_undo_report_row_operation 源码在innobase/trx/trx0rec.cc
源码很长,不贴了。主要流程如下:
- 判断当前变更的是否是临时表,如果是临时表,则采用临时表回滚段来分配,否则采用普通的回滚段;
- 临时表操作记录undo时不写redo log;
- 操作类型为TRX_UNDO_INSERT_OP,且未分配insert undo slot时,调用函数trx_undo_assign_undo进行分配;
- 操作类型为TRX_UNDO_MODIFY_OP,且未分配Update undo slot时,调用函数trx_undo_assign_undo进行分配。
我们来看看函数trx_undo_assign_undo的流程,源码在innobase/trx/trx0undo.cc:
- 首先总是从cahced list上分配trx_undo_t (函数
trx_undo_reuse_cached(innobase/trx/trx0undo.cc 这个函数是用来给事务分配slot的),当满足某些条件时,事务提交时会将其拥有的trx_undo_t放到cached list上,这样新的事务可以重用这些undo 对象,而无需去扫描回滚段,寻找可用的slot,在后面的事务提交一节会介绍到);- 对于INSERT,从
trx_rseg_t::insert_undo_cached上获取,并修改头部重用信息(trx_undo_insert_header_reuse)及预留XID空间(trx_undo_header_add_space_for_xid) - 对于DELETE/UPDATE,从
trx_rseg_t::update_undo_cached上获取, 并在undo log hdr page上创建新的Undo log header(trx_undo_header_create),及预留XID存储空间(trx_undo_header_add_space_for_xid) - 获取到trx_undo_t对象后,会从cached list上移除掉。并初始化trx_undo_t相关信息(trx_undo_mem_init_for_reuse),将
trx_undo_t::state设置为TRX_UNDO_ACTIVE
- 对于INSERT,从
-
如果没有cache的trx_undo_t,则需要从回滚段上分配一个空闲的undo slot(trx_undo_create),并创建对应的undo页,进行初始化;
一个回滚段可以支持1024个事务并发,如果不幸回滚段都用完了(通常这几乎不会发生),会返回错误DB_TOO_MANY_CONCURRENT_TRXS
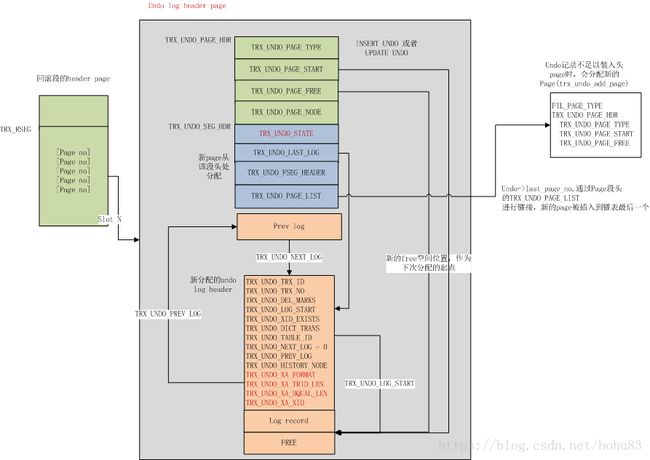
每一个Undo log segment实际上对应一个独立的段,段头的起始位置在UNDO 头page的TRX_UNDO_SEG_HDR+TRX_UNDO_FSEG_HEADER偏移位置(见下图)
-
已分配给事务的trx_undo_t会加入到链表
trx_rseg_t::insert_undo_list或者trx_rseg_t::update_undo_list上; - 如果是数据词典操作(DDL)产生的undo,主要是表级别操作,例如创建或删除表,还需要记录操作的table id到undo log header中(TRX_UNDO_TABLE_ID),同时将TRX_UNDO_DICT_TRANS设置为TRUE。(trx_undo_mark_as_dict_operation)。
总的来说,undo header page主要包括如下信息(图片来自taobao.mysql这个图我还没看懂):
五 如何写入undo日志
入口函数:trx_undo_report_row_operation 源码:/innobase/trx/trx0rec.cc
当分配了一个undo slot,同时初始化完可用的空闲区域后,就可以向其中写入undo记录了。写入的page no取自undo->last_page_no,初始情况下和hdr_page_no相同。
对于INSERT_UNDO,调用函数trx_undo_page_report_insert进行插入,记录格式大致如下图所示:
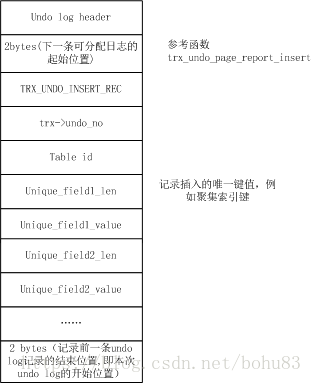
对于UPDATE_UNDO,调用函数 trx_undo_page_report_modify(源码innobase/trx/trx0rec.cc) 进行插入,UPDATE UNDO的记录格式大概如下图
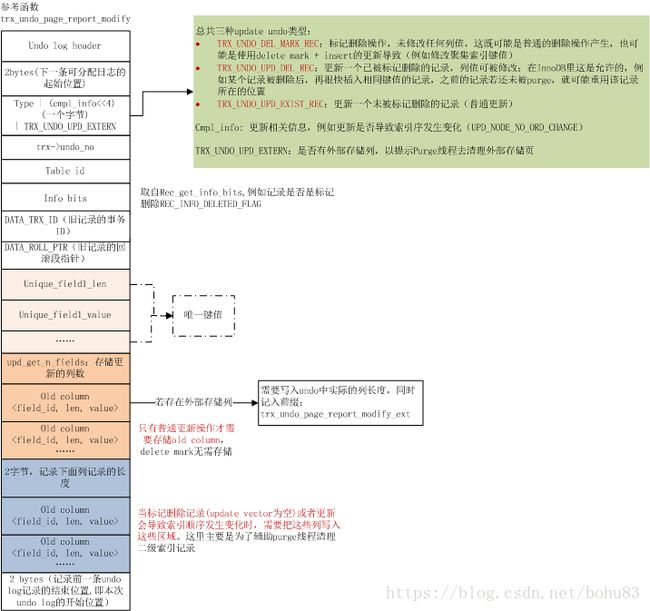
在写入的过程中,可能出现单页面空间不足的情况,导致写入失败,我们需要将刚刚写入的区域清空重置(trx_undo_erase_page_end),同时申请一个新的page(trx_undo_add_page) 加入到undo log段上,同时将undo->last_page_no指向新分配的page,然后重试。
完成Undo log写入后,构建新的回滚段指针并返回(trx_undo_build_roll_ptr),回滚段指针包括undo log所在的回滚段id、日志所在的page no、以及page内的偏移量,需要记录到聚集索引记录中。
事务Prepare阶段
入口函数:trx_prepare_low 源码:/innobase/trx/trx0trx.cc
当事务完成需要提交时,为了和BINLOG做XA,InnoDB的commit被划分成了两个阶段:prepare阶段和commit阶段,本小节主要讨论下prepare阶段undo相关的逻辑。
为了在崩溃重启时知道事务状态,需要将事务设置为Prepare,MySQL 5.7对临时表undo和普通表undo分别做了处理,前者在写undo日志时总是不需要记录redo,后者则需要记录。
分别设置insert undo 和 update undo的状态为prepare,调用函数trx_undo_set_state_at_prepare,过程也比较简单,找到undo log slot对应的头页面(trx_undo_t::hdr_page_no),将页面段头的TRX_UNDO_STATE设置为TRX_UNDO_PREPARED,同时修改其他对应字段,如下图所示(对于外部显式XA所产生的XID,这里不做讨论):
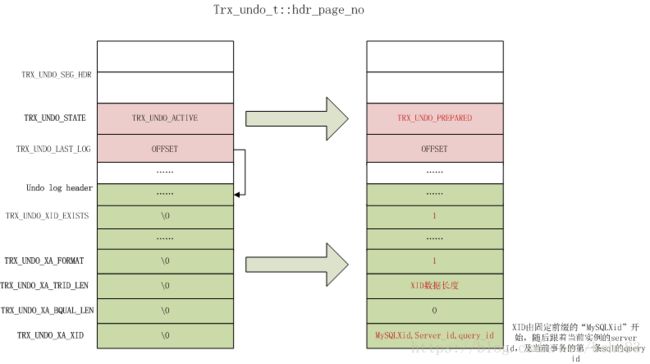
Tips:InnoDB层的XID是如何获取的呢? 当Innodb的参数innodb_support_xa打开时,在执行事务的第一条SQL时,就会去注册XA,根据第一条SQL的query id拼凑XID数据,然后存储在事务对象中。参考函数trans_register_ha
事务Commit
当事务commit时,需要将事务状态设置为COMMIT状态,这里同样通过Undo来实现的。
入口函数:trx_commit_low(/innobase/trx/trx0trx.cc)-->trx_write_serialisation_history(innobase/trx/trx0trx.cc)
在该函数中,需要将该事务包含的Undo都设置为完成状态,先设置insert undo,再设置update undo(trx_undo_set_state_at_finish),完成状态包含三种:
- 如果当前的undo log只占一个page,且占用的header page大小使用不足其3/4时(TRX_UNDO_PAGE_REUSE_LIMIT),则状态设置为TRX_UNDO_CACHED,该undo对象会随后加入到undo cache list上;
- 如果是Insert_undo(undo类型为TRX_UNDO_INSERT),则状态设置为TRX_UNDO_TO_FREE;
- 如果不满足a和b,则表明该undo可能需要Purge线程去执行清理操作,状态设置为TRX_UNDO_TO_PURGE。
在确认状态信息后,写入undo header page的TRX_UNDO_STATE中。
如果当前事务包含update undo,并且undo所在回滚段不在purge队列时,还需要将当前undo所在的回滚段(及当前最大的事务号)加入Purge线程的Purge队列(purge_sys->purge_queue)中(参考函数trx_serialisation_number_get)。
对于undate undo需要调用trx_undo_update_cleanup进行清理操作,清理的过程包括:
-
将undo log加入到history list上,调用
trx_purge_add_update_undo_to_history:-
如果该undo log不满足cache的条件(状态为TRX_UNDO_CACHED,如上述),则将其占用的slot设置为FIL_NULL,意为slot空闲,同时更新回滚段头的TRX_RSEG_HISTORY_SIZE值,将当前undo占用的page数累加上去;
-
将当前undo加入到回滚段的TRX_RSEG_HISTORY链表上,作为链表头节点,节点指针为UNDO头的TRX_UNDO_HISTORY_NODE;
-
更新
trx_sys->rseg_history_len(也就是show engine innodb status看到的history list),如果只有普通的update_undo,则加1,如果还有临时表的update_undo,则加2,然后唤醒purge线程; -
将当前事务的
trx_t::no写入undo头的TRX_UNDO_TRX_NO段; -
如果不是delete-mark操作,将undo头的TRX_UNDO_DEL_MARKS更新为false;
-
如果undo所在回滚段的
rseg->last_page_no为FIL_NULL,表示该回滚段的旧的清理已经完成,进行如下赋值,记录这个回滚段上第一个需要purge的undo记录信息:rseg->last_page_no = undo->hdr_page_no; rseg->last_offset = undo->hdr_offset; rseg->last_trx_no = trx->no; rseg->last_del_marks = undo->del_marks;
-
-
如果undo需要cache,将undo对象放到回滚段的update_undo_cached链表上;否则释放undo对象(trx_undo_mem_free)。
注意上面只清理了update_undo,insert_undo直到事务释放记录锁、从读写事务链表清除、以及关闭read view后才进行,调用函数trx_undo_insert_cleanup:
-
如果Undo状态为TRX_UNDO_CACHED,则加入到回滚段的insert_undo_cached链表上;
-
否则,将该undo所占的segment及其所占用的回滚段的slot全部释放掉(trx_undo_seg_free),修改当前回滚段的大小(rseg->curr_size),并释放undo对象所占的内存(trx_undo_mem_free),和Update_undo不同,insert_undo并未放到History list上。
事务完成提交后,需要将其使用的回滚段引用计数rseg->trx_ref_count减1;
事务回滚
如果事务因为异常或者被显式的回滚了,那么所有数据变更都要改回去。这里就要借助回滚日志中的数据来进行恢复了。
入口函数为:row_undo_step(源码/innobase/row/row0undo.cc) --> row_undo(/innobase/row/row0undo.cc)
操作也比较简单,析取老版本记录,做逆向操作即可:对于标记删除的记录清理标记删除标记;对于in-place更新,将数据回滚到最老版本;对于插入操作,直接删除聚集索引和二级索引记录(row_undo_ins)。
具体的操作中,先回滚二级索引记录(row_undo_mod_del_mark_sec、row_undo_mod_upd_exist_sec、row_undo_mod_upd_del_sec),再回滚聚集索引记录(row_undo_mod_clust)。这里不展开描述,可以参阅对应的函数。
多版本控制
InnoDB的多版本使用undo来构建,这很好理解,undo记录中包含了记录更改前的镜像,如果更改数据的事务未提交,对于隔离级别大于等于read commit的事务而言,它不应该看到已修改的数据,而是应该给它返回老版本的数据。
入口函数: row_vers_build_for_consistent_read(源码在/innobase/row/row0vers.cc)
由于在修改聚集索引记录时,总是存储了回滚段指针和事务id,可以通过该指针找到对应的undo 记录,通过事务Id来判断记录的可见性。当旧版本记录中的事务id对当前事务而言是不可见时,则继续向前构建,直到找到一个可见的记录或者到达版本链尾部。(关于事务可见性及read view,可以参阅我们之前的月报)
Tips 1:构建老版本记录(trx_undo_prev_version_build)需要持有page latch,因此如果Undo链太长的话,其他请求该page的线程可能等待时间过长导致crash,最典型的就是备库备份场景:
当备库使用innodb表存储复制位点信息时(relay_log_info_repository=TABLE),逻辑备份显式开启一个read view并且执行了长时间的备份时,这中间都无法对slave_relay_log_info表做purge操作,导致版本链极其长;当开始备份slave_relay_log_info表时,就需要去花很长的时间构建老版本;复制线程由于需要更新slave_relay_log_info表,因此会陷入等待Page latch的场景,最终有可能导致信号量等待超时,实例自杀。 (bug#74003)
Tips 2:在构建老版本的过程中,总是需要创建heap来存储旧版本记录,实际上这个heap是可以重用的,无需总是重复构建(bug#69812)
Tips 3:如果回滚段类型是INSERT,就完全没有必要去看Undo日志了,因为一个未提交事务的新插入记录,对其他事务而言总是不可见的。
Tips 4: 对于聚集索引我们知道其记录中存有修改该记录的事务id,我们可以直接判断是否需要构建老版本(lock_clust_rec_cons_read_sees),但对于二级索引记录,并未存储事务id,而是每次更新记录时,同时更新记录所在的page上的事务id(PAGE_MAX_TRX_ID),如果该事务id对当前事务是可见的,那么就无需去构建老版本了,否则就需要去回表查询对应的聚集索引记录,然后判断可见性(lock_sec_rec_cons_read_sees)。
Purge清理操作
从上面的分析我们可以知道:update_undo产生的日志会放到history list中,当这些旧版本无人访问时,需要进行清理操作;另外页内标记删除的操作也需要从物理上清理掉。后台Purge线程负责这些工作。
入口函数:srv_do_purge(/innobase/srv/srv0srv.cc) --> trx_purge (/innobase/trx/trx0purge.cc)
太复杂,不展开。需要单独整理。
*************************************
参考:
http://mysql.taobao.org/monthly/2015/04/01/