神经网络中的常用激活函数总结

©PaperWeekly 原创 · 作者|张文翔
单位|京东集团算法工程师
研究方向|推荐算法

激活函数之性质
1. 非线性:即导数不是常数。保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。
2. 可微性:保证了在优化中梯度的可计算性。虽然 ReLU 存在有限个点处不可微,但处处 subgradient,可以替代梯度。
3. 计算简单:激活函数复杂就会降低计算速度,因此 RELU 要比 Exp 等操作的激活函数更受欢迎。
4. 非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是 Sigmoid,它的导数在 x 为比较大的正值和比较小的负值时都会接近于 0。RELU 对于 x<0,其梯度恒为 0,这时候它也会出现饱和的现象。Leaky ReLU 和 PReLU 的提出正是为了解决这一问题。
5. 单调性(monotonic):即导数符号不变。当激活函数是单调的时候,单层网络能够保证是凸函数。但是激活函数如 mish 等并不满足单调的条件,因此单调性并不是硬性条件,因为神经网络本来就是非凸的。
6. 参数少:大部分激活函数都是没有参数的。像 PReLU 带单个参数会略微增加网络的大小。还有一个例外是 Maxout,尽管本身没有参数,但在同样输出通道数下 k 路 Maxout 需要的输入通道数是其它函数的 k 倍,这意味着神经元数目也需要变为 k 倍。
参考:
[1] 如果在前向传播的过程中使用了不可导的函数,是不是就不能进行反向传播了?
https://www.zhihu.com/question/297337220/answer/936415957
[2] 为什么神经网络中的激活函数大部分都是单调的?
https://www.zhihu.com/question/66747114/answer/372830123

激活函数之简介
1. Sigmoid激活函数
sigmoid 函数及其导数如下:
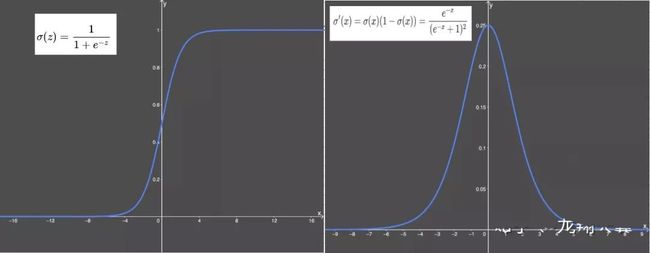
优点:
梯度平滑
输出值在 0-1 之间
缺点:
激活函数计算量大(在正向传播和反向传播中都包含幂运算和除法);
梯度消失:输入值较大或较小(图像两侧)时,sigmoid 函数值接近于零。sigmoid 导数则接近于零,导致最终的梯度接近于零,无法实现更新参数的目的;
Sigmoid 的输出不是 0 为中心(zero-centered)。
1. Sigmoid激活函数
sigmoid 函数及其导数如下:
优点:
梯度平滑
输出值在 0-1 之间
缺点:
激活函数计算量大(在正向传播和反向传播中都包含幂运算和除法);
梯度消失:输入值较大或较小(图像两侧)时,sigmoid 函数值接近于零。sigmoid 导数则接近于零,导致最终的梯度接近于零,无法实现更新参数的目的;
Sigmoid 的输出不是 0 为中心(zero-centered)。
2. tanh激活函数
tanh 函数及其导数:
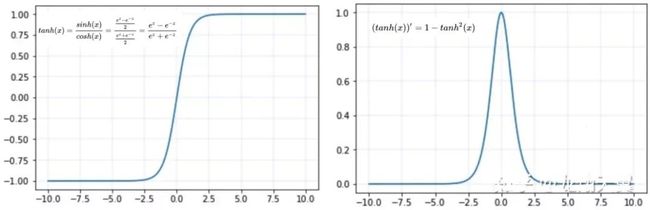
优点:
同 sigmoid
tanh(x) 的梯度消失问题比 sigmoid 要轻,收敛更快
输出是以 0 为中心 zero-centered
缺点:
同 sigmoid
3. 整流线性单元(ReLU)
ReLU 的函数及其导数如下:
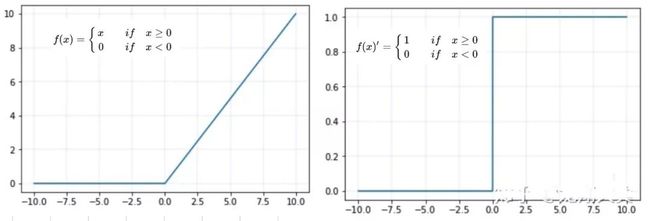
优点:
简单高效:不涉及指数等运算;
一定程度缓解梯度消失问题:因为导数为 1,不会像 sigmoid 那样由于导数较小,而导致连乘得到的梯度逐渐消失。
缺点:
dying Relu:即网络的部分分量都永远不会更新,可以参考:
https://datascience.stackexchange.com/questions/5706/what-is-the-dying-relu-problem-in-neural-networks
4. 指数线性单元(ELU)
ELU 的函数及其导数如下:
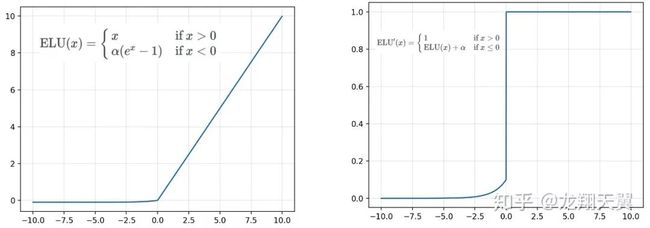
优点:
能避免死亡 ReLU 问题:x 小于 0 时函数值不再是 0,因此可以避免 dying relu 问题;
能得到负值输出,这能帮助网络向正确的方向推动权重和偏置变化。
缺点:
计算耗时:包含指数运算;
α 值是超参数,需要人工设定
5. 扩展型指数线性单元激活函数(SELU)
SELU 源于论文 Self-Normalizing Neural Networks,作者为 Sepp Hochreiter,ELU 同样来自于他们组。
SELU 其实就是 ELU 乘 lambda,关键在于这个 lambda 是大于 1 的,论文中给出了 lambda 和 alpha 的值:
lambda = 1.0507
alpha = 1.67326
SELU 的函数及其导数如下:
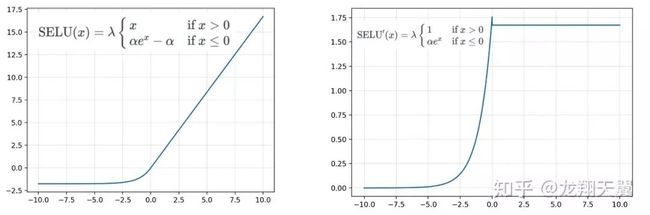
优点:
SELU 激活能够对神经网络进行自归一化(self-normalizing);
不可能出现梯度消失或爆炸问题,论文附录的定理 2 和 3 提供了证明。
缺点:
应用较少,需要更多验证;
lecun_normal 和 Alpha Dropout:需要 lecun_normal 进行权重初始化;如果 dropout,则必须用 Alpha Dropout 的特殊版本。
6. 渗漏型整流线性单元激活函数(Leaky ReLU)
leak_relu 的函数及其导数如下:
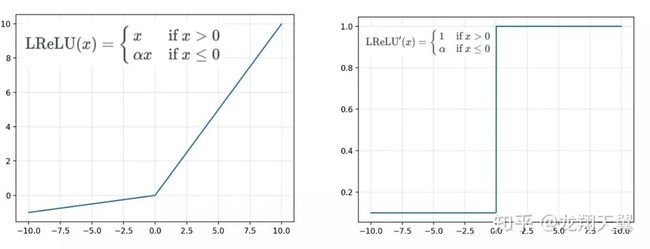
优点:
类似于 ELU,能避免死亡 ReLU 问题:x 小于 0 时候,导数是一个小的数值,而不是 0;
与 ELU 类似,能得到负值输出;
计算快速:不包含指数运算。
缺点:
同 ELU,α 值是超参数,需要人工设定;
在微分时,两部分都是线性的;而 ELU 的一部分是线性的,一部分是非线性的。
7. Parametric ReLU (PRELU)
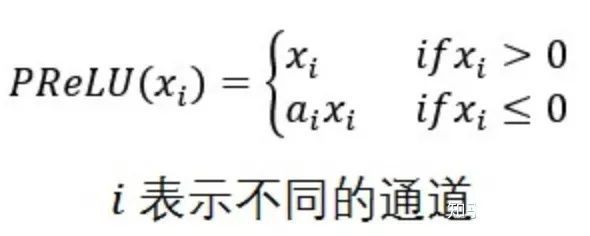
形式上与 Leak_ReLU 在形式上类似,不同之处在于:PReLU 的参数 alpha 是可学习的,需要根据梯度更新。
alpha=0:退化为 ReLU
alpha 固定不更新,退化为 Leak_ReLU
优点:
与 ReLU 相同。
缺点:
在不同问题中,表现不一。
8. 高斯误差线性单元(Gaussian Error Linear Unit,GELU)
Dropout 和 ReLU 都希望将“不重要”的激活信息变为零。以 ReLU 为例,对于每个输入 x 都会乘以一个分布,这个分布在 x>0 时为常数 1,在 x≤0 时为常数0。而 GELU 也是在 x(服从标准正态分布)的基础上乘以一个分布,这个分布就是伯努利分布 Φ(x) = P(X≤x)。
因此,高斯误差线性单元(GELU)为 GELU(x) = x*P(X≤x)。
随着 x 的降低,它被归零的概率会升高。对于 ReLU 来说,这个界限就是 0,输入少于零就会被归零;
与 RELU 类似:对输入的依赖;
与 RELU 不同:软依赖 P(X≤x),而非简单 0-1 依赖;
直观理解:可以按当前输入 x 在其它所有输入中的位置来缩放 x。
但是这个函数无法直接计算,需要通过另外的方法来逼近这样的激活函数,研究者得出来两个逼近函数:

第二个逼近函数,与谷歌 2017 年提出来的 Swish 激活函数类似:f(x) = x · sigmoid(x),后面详细介绍。
以第一个近似函数为例,GELU 的函数及其导数如下:

优点:
在 NLP 领域效果最佳;尤其在 Transformer 模型中表现最好;
类似 RELU 能避免梯度消失问题。
缺点:
2016 年提出较新颖;
计算量大:类似 ELU,涉及到指数运算。
9. Swish by Google 2017
Swish 激活函数形式为:f(x)=x*sigmoid(βx)。
β 是个常数或可训练的参数,通常所说的 Swish 是指 β=1;
β=1.702 时,可以看作是 GELU 激活函数。
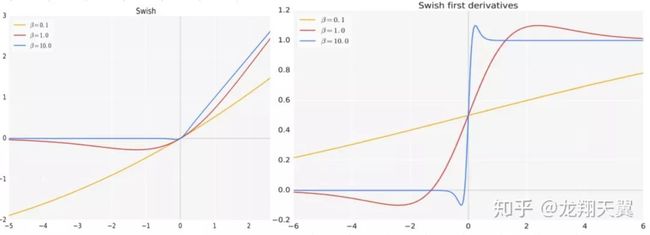
优点:
据论文介绍,Swish 效果优于 ReLU:
https://arxiv.org/abs/1710.05941v2
缺点:
计算量大:sigmoid 涉及到指数运算。
10. Mish by Diganta Misra 2019
Mish=x * tanh(ln(1+e^x))
在函数形式和图像上,都与 GELU 和 Swish(β=1) 类似。
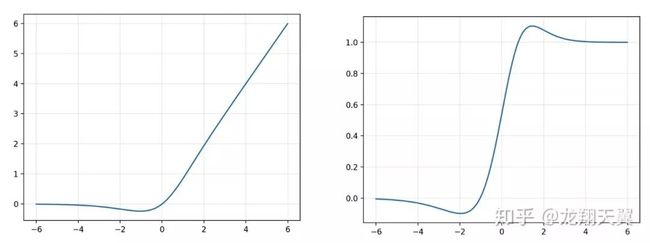
优点:
根据论文介绍:
https://arxiv.org/abs/1908.08681
Mish 函数保证在曲线上几乎所有点上的平滑度;
随着层深的增加,ReLU 精度迅速下降,其次是 Swish。而 Mish 能更好地保持准确性。
缺点:
2019 年提出,需要时间和更多实际应用验证。
11. Maxout
Maxout 的参数量较大,因此实际应用中比较少。
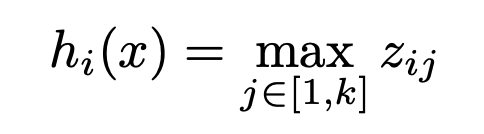
![]()
普通网络每一层只有一个参数矩阵 W,maxout 则有 k 个参数 W,每个隐藏单元只取 k 个 W*x+b 的计算结果中最大的。下图比较形象:
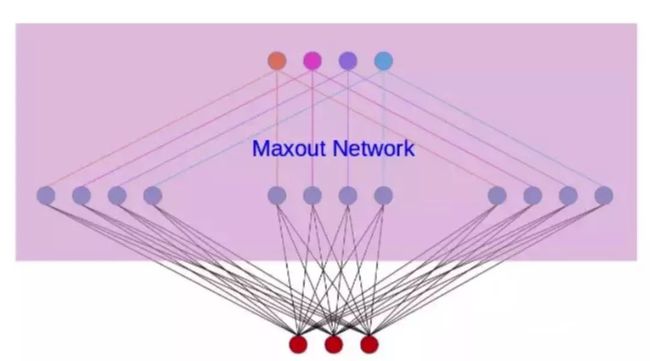
Maxout 可以拟合任意的的凸函数
Maxout 与 Dropout 的结合效果比较好
12. Data Adaptive Activation Function (Dice) by alibaba 2018
这是阿里巴巴的一篇 CTR 论文 Deep Interest Network for Click-Through Rate Prediction 中提出的一个激活函数,根据 Parameter ReLU 改造而来的。
通过下图来看一下 PReLU 和 Dice 的异同:
激活函数的形式相同:f(s) = p(s) * s + (1 − p(s)) · αs
p(s)的计算方式不同:
PReLU:p(s) 是指示函数 I(s>0)
Dice:p(s) 是 sigmoid(BN(s)),BN 代表 Batch Normalization
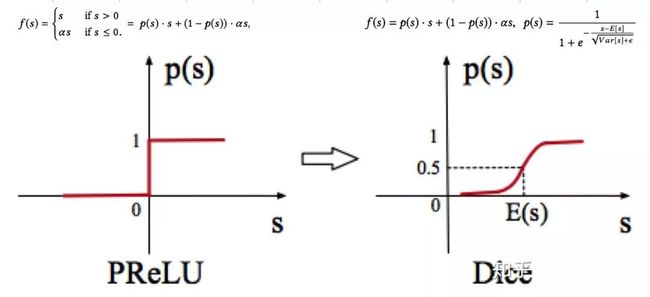
Dice 可以看作是一种广义的 PReLu,当 E(s) = 0 且 Var(s) = 0 时,Dice 退化为 PReLU。
Dice 受到数据影响,E(s) 决定其 rectified point:PReLU 是在 0 的位置,而 Dice 是在 E(s) 位置。
与Batch Normalization 有异曲同工之妙,可以解决 Internal Covariate Shift 问题。论文 Deep Interest Network for Click-Through Rate Prediction 实验表明 :Dice 效果优于 PReLU。
具体实现可以参考 Dice 代码:
https://github.com/mouna99/dien/blob/master/script/Dice.py

点击以下标题查看更多往期内容:
基于预训练自然语言生成的文本摘要方法
浅谈 Knowledge-Injected BERTs
细粒度情感分析任务(ABSA)的最新进展
自然语言处理中的语言模型预训练方法
BERT+知识图谱:知识赋能的K-BERT模型
从三大顶会论文看百变Self-Attention
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 获取最新论文推荐