73岁Hinton老爷子构思下一代神经网络:属于无监督对比学习

机器之心报道
编辑:魔王、杜伟
在近期举行的第 43 届国际信息检索年会 (ACM SIGIR2020) 上,Geoffrey Hinton 做了主题为《The Next Generation of Neural Networks》的报告。
Geoffrey Hinton 是谷歌副总裁、工程研究员,也是 Vector Institute 的首席科学顾问、多伦多大学 Emeritus 荣誉教授。2018 年,他与 Yoshua Bengio、Yann LeCun 因对深度学习领域做出的巨大贡献而共同获得图灵奖。
自 20 世纪 80 年代开始,Geoffrey Hinton 就开始提倡使用机器学习方法进行人工智能研究,他希望通过人脑运作方式探索机器学习系统。受人脑的启发,他和其他研究者提出了「人工神经网络」(artificial neural network),为机器学习研究奠定了基石。
那么,30 多年过去,神经网络的未来发展方向在哪里呢?
Hinton 在此次报告中回顾了神经网络的发展历程,并表示下一代神经网络将属于无监督对比学习。
Hinton 的报告主要内容如下:
人工神经网络最重要的待解难题是:如何像大脑一样高效执行无监督学习。
目前,无监督学习主要有两类方法。
第一类的典型代表是 BERT 和变分自编码器(VAE),它们使用深度神经网络重建输入。但这类方法无法很好地处理图像问题,因为网络最深层需要编码图像的细节。
另一类方法由 Becker 和 Hinton 于 1992 年提出,即对一个深度神经网络训练两个副本,这样在二者的输入是同一图像的两个不同剪裁版本时,它们可以生成具备高度互信息的输出向量。这类方法的设计初衷是,使表征脱离输入的不相关细节。
Becker 和 Hinton 使用的优化互信息方法存在一定缺陷,因此后来 Pacannaro 和 Hinton 用一个判别式目标替换了它,在该目标中一个向量表征必须在多个向量表征中选择对应的一个。
随着硬件的加速,近期表征对比学习变得流行,并被证明非常高效,但它仍然存在一个主要缺陷:要想学习具备 N bits 互信息的表征向量对,我们需要对比正确的对应向量和 2 N 个不正确的向量。
在演讲中,Hinton 介绍了一种处理该问题的新型高效方式。此外,他还介绍了实现大脑皮层感知学习的简单途径。
接下来,我们来看 Hinton 演讲的具体内容。
为什么我们需要无监督学习?
在预测神经网络的未来发展之前,Hinton 首先回顾了神经网络的发展进程。
演讲一开始,Hinton 先介绍了三种学习任务:监督学习、强化学习和无监督学习,并重点介绍了无监督学习的必要性。

为什么我们需要无监督学习呢?
Hinton 从生物学的角度做出了诠释。他指出,人类大脑有 10^14 个神经元突触,而生命的长度仅有 10^9 秒,因此人类无法完全依赖监督学习方式完成所有神经元训练,因而需要无监督学习的辅助。
受此启发,构建智能模型也需要无监督学习。
无监督学习的发展历程
无监督学习经过怎样的发展呢?Hinton 为我们介绍了无监督学习中的常见目标函数。

紧接着,Hinton 详细介绍了自编码器。
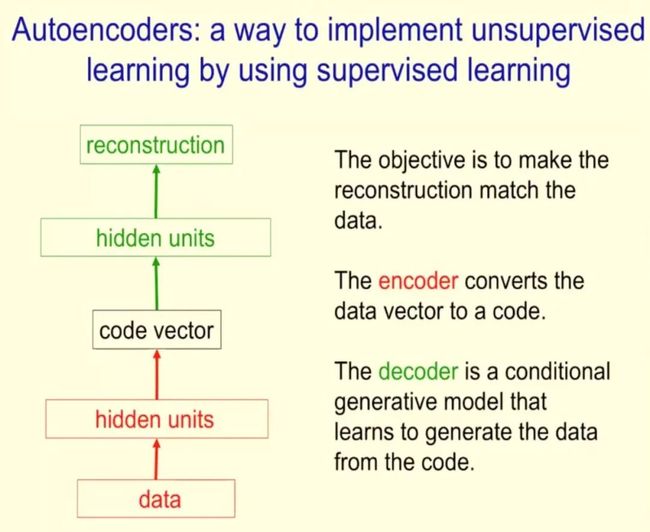
Hinton 表示,自编码器是一种利用监督学习实现无监督学习的方式,其目标是使最后的重建结果与数据相匹配。编码器将数据向量转换为代码,解码器基于代码生成数据。
在高屋建瓴地介绍了自编码器的定义、训练深度自编码器之前的难点和现状之后,Hinton 着重介绍了两种自编码器类型:变分自编码器和 BERT 自编码器。
使用深度神经网络重建输入:VAE 和 BERT
BERT 和变分自编码器(VAE)是无监督学习的一类典型代表,它们使用深度神经网络重建输入。
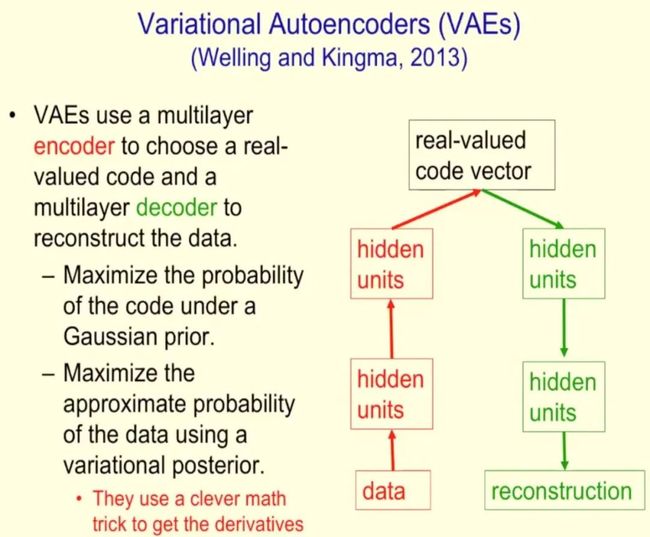
变分自编码器由韦灵思和 Kingma 于 2013 年提出,它使用多层编码器选择实数代码,然后用多层解码器重建数据。VAE 的基本构造如下图所示:
BERT 是 2018 年谷歌提出的语言表征模型,基于所有层的左、右语境来预训练深度双向表征。

语境信息对 BERT 非常重要,它利用遮蔽语言模型(masked language model,MLM)允许表征融合左右两侧的语境,从而预训练深度双向 Transformer。
Hinton 举了一个例子:「She scromed him with the frying pan」。在这个句子中,即使你不知道 scromed 的意思,也可以根据上下文语境进行推断。
视觉领域也是如此。然而,BERT 这类方法无法很好地应用到视觉领域,因为网络最深层需要编码图像的细节。

在探讨了以 VAE 和 BERT 为代表的一类无监督学习方法后,Hinton 为我们介绍了另一类无监督学习方法。
Becker 和 Hinton 提出最大化互信息方法
那么自编码器和生成模型有没有什么替代方案呢?Hinton 表示,我们可以尝试不再解释感官输入(sensory input)的每个细节,而专注于提取空间或时序一致性的特征。与自编码器不同,这种方法的好处在于可以忽略噪声。
然后,Hinton 详细介绍了他与 Suzanna Becker 在 1992 年提出的一种提取空间一致性特征的方法。该方法的核心理念是对输入的两个非重叠块(non-overlapping patch)表示之间的显式互信息进行最大化处理。Hinton 给出了提取空间一致性变量的简单示例,如下图所示:

经过训练,Hinton 指出唯一的空间一致性特征是「不一致性」(The Only Spatially Coherent Property is Disparity),所以这也是必须要提取出来的。
他表示这种最大化互信息的方法存在一个棘手的问题,并做出以下假设,即如果只学习线性映射,并且对线性函数进行优化,则变量将成为分布式的。不过,这种假设并不会导致太多问题。
以往研究方法回顾
在这部分中,Hinton 先后介绍了 LLE、LRE、SNE、t-SNE 等方法。
局部线性嵌入方法(Locally Linear Embedding, LLE)
Hinton 介绍了 Sam T. Roweis 和 Lawrence K. Saul 在 2000 年 Science 论文《Nonlinear Dimensionality Reduction by Locally Linear Embedding》中提到的局部线性嵌入方法,该方法可以在二维图中显示高维数据点,并且使得非常相似的数据点彼此挨得很近。
但需要注意的是,LLE 方法会导致数据点重叠交融(curdling)和维度崩溃(dimension collapse)问题。
下图为 MNIST 数据集中数字的局部线性嵌入图,其中每种颜色代表不同的数字:

此外,这种长字符串大多是一维的,并且彼此之间呈现正交。
从线性关系嵌入(LRE)到随机邻域嵌入(SNE)
在这部分中,Hinton 介绍了从线性关系嵌入(Linear Relational Embedding, LRE)到随机邻域嵌入(Stochastic Neighbor Embedding, SNE)方法的转变。他表示,只有「similar-to」关系存在时,LRE 才转变成 SNE。
同时,Hinton 指出,可以将 LRE 目标函数用于降维(dimensionality reduction)。
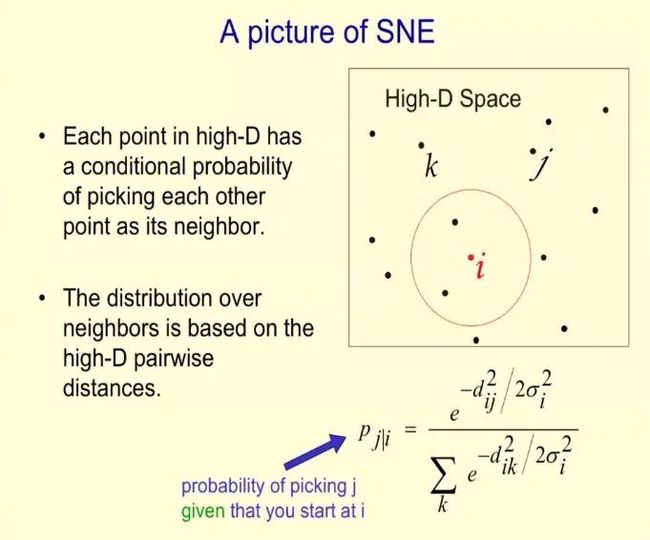
下图为 SNE 的示意图,其中高维空间的每个点都有选择其他点作为其邻域的条件概率,并且邻域分布基于高维成对距离(pairwise distance)。、
从随机邻域嵌入(SNE)到 t 分布随机邻域嵌入(t-SNE)
t 分布随机邻域嵌入(t-distributed stochastic neighbor embedding, t-SNE)是 SNE 的一种变体,原理是利用一个 student-distribution 来表示低维空间的概率分布。
Hinton 在下图中展示了 MNIST 数据集中数字的 t-SNE 嵌入图,每种颜色代表不同的数字:

在介绍完这些方法之后,Hinton 提出了两个问题:1)方差约束在优化非线性或非参数映射时为何表现糟糕?2)典型相关分析或线性判别分析的非线性版本为何不奏效?并做出了解答。
最后,Hinton 提出使用对比损失(contrastive loss)来提取空间或时间一致性的向量表示,并介绍了他与 Ruslan Salakhutdinov 在 2004 年尝试使用对比损失的探索,以及 Oord、Li 和 Vinyals 在 2018 年使用对比损失复现这种想法,并用它发现时间一致性的表示。
Hinton 表示,当前无监督学习中使用对比损失一种非常流行的方法。

无监督对比学习的最新实现 SimCLR
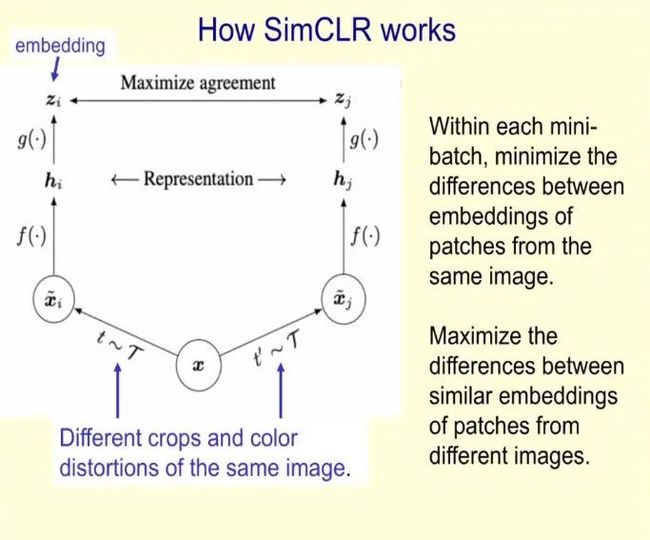
在演讲最后,Hinton 重点介绍了其团队使用对比损失提取一致性表示的最新实现 SimCLR,这是一种用于视觉表示的对比学习简单框架,它不仅优于此前的所有工作,也优于最新的对比自监督学习算法。
下图为 SimCLR 的工作原理图:
那么 SimCLR 在 ImageNet 上的 Top-1 准确率表现如何呢?下图展示了 SimCLR 与此前各类自监督方法在 ImageNet 上的 Top-1 准确率对比(以 ImageNet 进行预训练),以及 ResNet-50 的有监督学习效果。
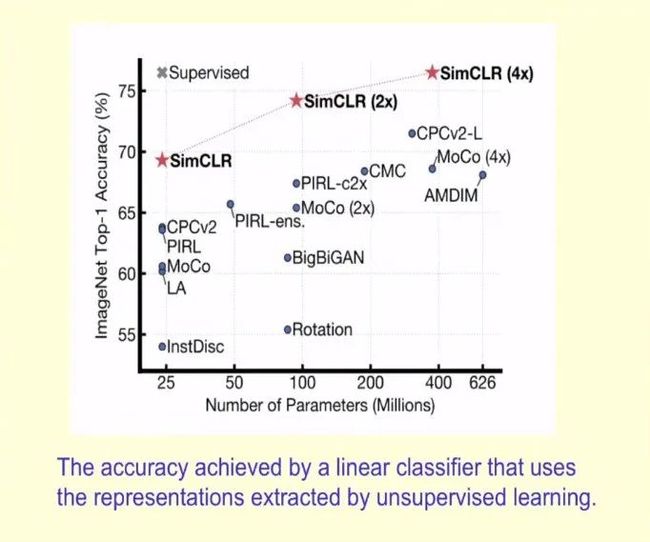
Hinton 表示,经过 ImageNet 上 1% 图片标签的微调,SimCLR 可以达到 85.8%的 Top-5 准确率——在只用 AlexNet 1% 标签的情况下性能超越后者。
Hinton 认为,以 SimCLR 为代表的无监督对比学习将引领下一代神经网络的发展。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

