Spark Core 子模块 storage分析
一、前言
1. 相关版本:Spark Master branch(2018.10, compiled-version spark-2.5.0, 设置了spark.shuffle.sort.bypassMergeThreshold 1 和 YARN-client 模式) ,HiBench-6.0 and Hadoop-2.7.1
2. 建议先了解Spark 的 RDD、DAG、Memory 和 Shuffle基本概念。
3. 重点介绍Spark 的Storage子模块的组成部分,关键流程及与RDD、Memory和shuffle的相关的部分,目标是为了提高Spark在实际测试应用中的性能和稳定性提供分析依据。
画图工具(dia 0.97+git,http://live.gnome.org/Dia)
二、 Spark Core 子模块 Storage 概要
1. Spark 子模块 Storage 管什么? 当然还是管这俩个小伙伴:Memory and Disk (SSD & HDD)

怎么管?以及有哪些应用场景? 后续。。。
2. Spark core 子模块 Storage 简介
Storage 子模块模块负责 RDD (persist(包括cache))、Shuffle中间结果、Broadcast变量的存储及管理。
Storage模块主要分为两层:
①通信层:storage模块采用的是master-slave结构来实现通信层,master和slave之间传输控制信息、状态信息,这些都是通过通信层来实现的。
②存储层:storage模块需要把数据存储到disk或是memory上面,有可能还需replicate到远端,这都是由存储层来实现和提供相应接口。
而其他Spark子模块(RDD, Shuffle, Broadcast)要和Storage模块进行交互,Storage模块提供了统一的操作类 BlockManager,外部类与Storage模块打交道都需要通过调用 BlockManager 相应接口来实现。Storage模块源代码包含的目录如下:

Spark core 子模块 Storage 的类关系图
Spark 子模块 Storge 管什么?Spark 子模块 Storage 管什么?
三、Spark Core 子模块 Storage 详解
1. Spark Storage框架图(包括2个Slave)
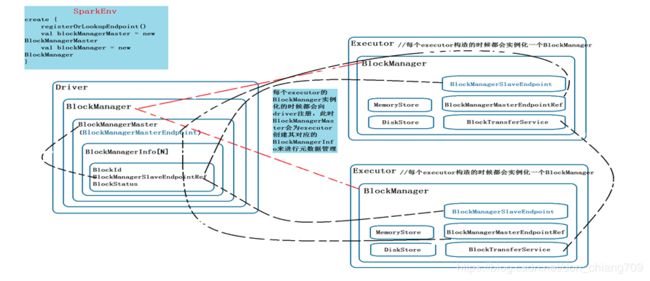
上页的图是Spark Storage整体的架构图.
1) Driver节点上的BlockManagerMaster 拥有 BlockManagerMasterEndpoint 的 actor 和所有 BlockManagerSlaveEndpoint 的ref, 可以通过这些引用对 slave 下达命令。
2) Executor 节点上的BlockManagerMaster 则拥有BlockManagerMasterEndpoint的ref和自身BlockManagerSlaveEndpoint的actor。可以通过 Master的引用注册自己。
3) 在master (driver)和 slave (executor)可以正常的通信之后, 就可以根据BlockManagerMessages定义的消息交互协议进行通信, 整个分布式缓存系统也就运转起来了。
BlockManager对象创建简介:
SparkEnv创建BlockManager对象时,使用了它的入参BlockManagerMaster对象,它发送的信息包装成BlockManagerInfo。Spark在Driver和Executor端都创建各自的BlockManager对象,并通过BlockManagerMasterEndpoint/BlockManagerSlaveEndpoint进行通信,通过BlockManager的接口对Storage子模块进行相关操作。
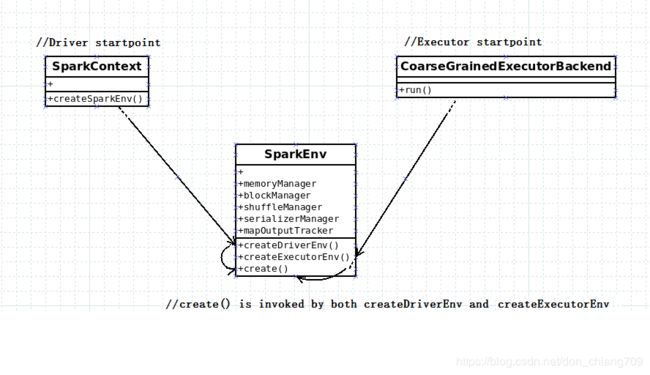
Driver BlockManager:
sparkEnv 在 master上启动的时候, 构造了一个 BlockManagerMasterEndpoint, 然后把这个Endpoint 注册在 rpcEnv中, 同时也会启动自己的 BlockManager。

Executor BlockManager:
sparkEnv 在executor上启动的时候, 通过 setupEndpointRef 方法获取到了 BlockManagerMaster的引用 BlockManagerMasterRef, 同时也会启动自己的 BlockManager。在 BlockManager 初始化自己的时候,会向 BlockManagerMasterEndpoint 注册自己, BlockManagerMasterEndpoint 发送 registerBlockManager消息, BlockManagerMasterEndpoint 接受到消息, 把 BlockManagerSlaveEndpoint 的引用 保存在自己的 blockManagerInfo 数据结构中以待后用。

2. Spark 子模块 Storage 通信层(消息分布式协议)
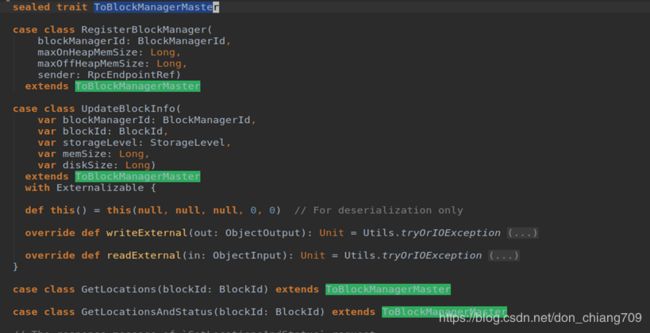
1) BlockManagerMasterEndpoint 接收的消息
BlockManagerMasterEndpoint 从 BlockManagerSlaveEndpoint 接受到各种类型的消息, 以及接受到消息后的处理。
| 消息 |
处理 |
| RegisterBlockManager |
slave 注册自己的消息,会保存在自己的blockManagerInfo中 |
| UpdateBlockInfo |
一个Block的更新消息,BlockId作为一个Block的唯一标识,会保存Block所在的节点和位置关系,以及block 存储级别,大小 占用内存和磁盘大小 |
| GetLocationsMultipleBlockIds |
获取多个Block所在 的位置,位置中会反映Block位于哪个 executor, host 和端口 |
| GetPeers |
一个block有可能在多个节点上存在,返回一个节点列表 |
| GetExecutorEndpointRef |
根据BlockId,获取所在executorEndpointRef 也就是 BlockManagerSlaveEndpoint的引用 |
| GetMemoryStatus |
获取所有节点上的BlockManager的最大内存和剩余内存 |
| GetStorageStatus |
获取所有节点上的BlockManager的最大磁盘空间和剩余磁盘空间 |
| GetBlockStatus |
获取一个Block的状态信息,位置,占用内存和磁盘大小 |
| GetMatchingBlockIds |
获取一个Block的存储级别和所占内存和磁盘大小 |
| RemoveRdd |
删除Rdd对应的Block数据 |
| RemoveBroadcast |
删除Broadcast对应的Block数据 |
| RemoveBlock |
删除一个Block数据,会找到数据所在的slave,然后向slave发送一个删除消息 |
| RemoveExecutor |
从BlockManagerInfo中删除一个BlockManager, 并且删除这个 BlockManager上的所有的Blocks |
| BlockManagerHeartbeat |
slave 发送心跳给 master , 证明自己还活着 |
Bloc
kBlockManagerMasterEndpoint 代码定义
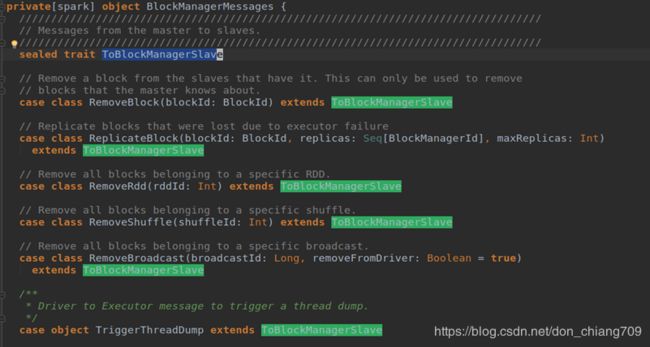
2) BlockManagerSlaveEndpoint 接收的消息.
Slave的 BlockManager 在自己节点上存储一个 Block, 然后把这个 BlockId 汇报到Master的BlockManager , 经过 cache, shuffle 或者 Broadcast后,别的节点需要这个Block的时候,会到 master 获取数据所在位置, 然后去相应节点上去 fetch。
| 消息 |
处理 |
| RemoveBlock |
slave删除自己BlockManager上的一个Block |
| RemoveRdd |
删除Rdd对应的Block数据 |
| RemoveShuffle |
删除 shuffleId对应的BlockId的Block |
| RemoveBroadcast |
删除 BroadcastId对应的BlockId的Block |
| GetBlockStatus |
获取一个Block的存储级别和所占内存和磁盘大小 |
BlockManagerSlaveEndpoint 代码定义
3. Spark 子模块 Storage 存储层
存储层的关键类

存储层的关键类
1) 存储层里的 BlockManager 及关键角色介绍
BlockManager对象被创建的时候会创建出MemoryStore和DiskStore对象用以存取block, 如果StorageLevel包含了内存且内存中拥有足够的内存, 就使用 MemoryStore存储, 如果不够就 spill 到磁盘中, 通过 DiskStore进行存储。通过源码可以看到目前BlockManager 里的Block 类型列表如下:
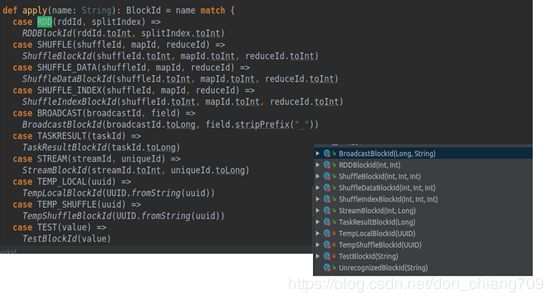
BlockId 是特定的Block 数据的唯一标识,通常关联一个的文件。
MemoryStore 和 MemoryManager:
MemoryStore
相比DiskStore需要根据block id hash计算出文件路径并将block存放到对应的文件里面, MemoryStore管理block就显得非常简单:MemoryStore内部维护了一个hash map来管理所有的block,以block id为key将block存放到hash map中。而从MemoryStore中取得block则非常简单,只需从hash map中取出block id对应的value即可。
memorySore是基于JVM的堆内存来存储数据,可以用于存数据的内存大小为:
(Runtime.getRuntime.maxMemory * memoryFraction * safetyFraction).toLong
其中memoryFraction 是可通过配置的一个比例(spark.storage.memoryFraction,默认0.6),safetyFraction是一个安全比例,可通过spark.storage.safetyFraction设置。
MemoryStore内部维护了一个hash map来管理所有的block,以block id为key将block存放到hash map中。
private val entries = new LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true)
放内存就意味着要有足够的内存来放,不然会导致OOM。
/**
* Stores blocks in memory, either as Arrays of deserialized Java objects or as
* serialized ByteBuffers.
*/
private[spark] class MemoryStore(
conf: SparkConf,
blockInfoManager: BlockInfoManager,
serializerManager: SerializerManager,
memoryManager: MemoryManager,
blockEvictionHandler: BlockEvictionHandler)
extends Logging {
关于LinkedHashMap的使用补充以下两点
LinkedHashMap内存使用双向链表维护数据的顺序(访问顺序或插入顺序),第三个参数为true时维护访问顺序,每次访问的数据被移至双向链表首位。
LinkedHashMap的value为MemoryEntry对象,Key为BlockId,BlockId有三个主要实现类,RDDBlockId、ShuffleBlockId、BroadcastBlockId,分别存储RDD、Shuffle中间结果和Broadcast。
MemoryManager
/**
* An abstract memory manager that enforces how memory is shared between execution and storage.
*
* In this context, execution memory refers to that used for computation in shuffles, joins,
* sorts and aggregations, while storage memory refers to that used for caching and propagating
* internal data across the cluster. There exists one MemoryManager per JVM.
*/
private[spark] abstract class MemoryManager(
conf: SparkConf,
numCores: Int,
onHeapStorageMemory: Long,
onHeapExecutionMemory: Long) extends Logging {
…
}
DiskStore 和 DiskBlockManager:
DiskStore
DiskSore就是基于磁盘介质来存取BlockManager的block数据,它提供了读写磁盘的接口getBytes/putByetes, getBytes对大于2M的block数据提供了MemoryMap。 DiskStore有一个成员DiskBlockManager,其主要作用就是逻辑block和磁盘block的映射,block的blockId对应磁盘文件中的一个文件。接收一个blockId和要写的字节数据,通过blockId获取到要写的具体文件并得到对应的文件输出流,将该bytes直接write这个流里,完成写文件。
/**
* Stores BlockManager blocks on disk.
*/
private[spark] class DiskStore(
conf: SparkConf,
diskManager: DiskBlockManager,
securityManager: SecurityManager) extends Logging {
DiskBlockManager
DiskBlockManager 主要用来创建并持有逻辑 blocks 与磁盘上的 blocks之间的映射,一个逻辑 block 通过 BlockId(准确说是BlockId.name) 映射到一个磁盘上的文件。 在 DiskStore 中会调用 diskManager.getFile 方法, 如果子文件夹不存在,会进行创建, 文件夹的命名方式为(spark-local-yyyyMMddHHmmss-xxxx, xxxx是一个随机数), 所有的block都会存储在所创建的folder里面。
2) Spark 子模块 Storage 的Cache Manager
存储层里隐藏的Cache Manager
①独立的CacheManager.scala 文件已离我们而去。
②Cache Manager 模块的change-set:
CacheManager.scala已经在2.0.0版本中remove,对应的change-set为[SPARK-12817],描述如下:
[SPARK-12817]: Add BlockManager.getOrElseUpdate and remove CacheManager
Description: CacheManager directly calls MemoryStore.unrollSafely() and has its own logic for handling graceful fallback to disk when cached data does not fit in memory. However, this logic also exists inside of the MemoryStore itself, so this appears to be unnecessary duplication. Thanks to the addition of block-level read/write locks in #10705, we can refactor the code to remove the CacheManager and replace it with an atomic `BlockManager.getOrElseUpdate()` method.
所以CacheManager.scala代码已经重构到BlockManager/MemoryStore.scala中了。
Cach Manager 概要:

Cache Manager 总结:

①每当 Task 运行的时候会调用 RDD 的iterator 方法读取RDD数据,而 iterator方法会通过 BlockManager 来能获取数据或者调用RDD子类的 Compute实现方法来计算;
②Cache Manager 管理的是缓存中的数据,缓存可以是基于内存的缓存(Cache()),也可以是基于磁盘的缓存(Persist(DISK_ONLY));
③Cache 在工作的时候会最大化的保留数据,但是数据不一定绝对完整,因为当前的计算如果需要内存空间的话,那么内存中的数据必需让出空间,这是因为执行比缓存重要!此时如何在RDD 持久化的时候同时指定了可以把数据放左Disk 上,那么部份 Cache 的数据可以从内存转入磁盘,否则的话,数据就会丢失!
④Cache Manager通过 BlockManager 来获取数据的时候,优先在本地找数据或者的话就远程抓取数据。
Cache、Persist 和 checkpoint的区别:
| 类型 |
描述 |
| Cache |
•Cache 是 Persist(MEMORY_ONLY)。而Persist的入参可以设置成StorageLevel定义的任意一种,包括磁盘等。 |
| Persist |
•生命周期:rdd.persist(StorageLevel.DISK_ONLY),将 RDD 的 partition 持久化到磁盘,但该 partition 由 blockManager 管理。 一旦 driver program 执行结束,也就是 executor 所在进程 CoarseGrainedExecutorBackend stop,blockManager 也会 stop, 被 cache 到磁盘上的 RDD 也会被清空(整个 blockManager 使用的 local 文件夹被删除)。 •RDD 的lineage未变 |
| CheckPoint |
•生命周期:checkpoint 将 RDD 持久化到本地文件系统(local mode)或者 HDFS (non-local mode) •RDD 的lineage 已变,删除之前的依赖关系,同时把父rdd设置成了CheckpointRDD •需要 checkpoint 的 RDD 会被计算两次, 正常的job 运行结束后(代码在SparkContext.runJob里)会调用 finalRdd.doCheckpoint(),finalRdd 会顺着 computing chain 回溯扫描,碰到要 checkpoint 的 RDD 就将其标记为 CheckpointingInProgress,然后将写磁盘. •
|
Checkpoint的流程
heckp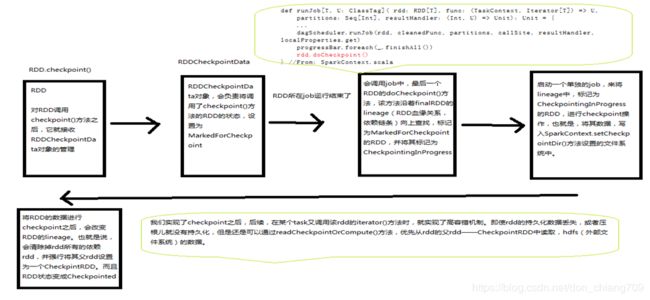 oint的流程
oint的流程
CacheCche、Persist 和 checkpoint的区别、Persist 和 checkpoint的区别
四、Spark 子模块 Storage 里的应用案例分析 (分配 StorageMemory/ExecutionMemory/DiskStore)
1. TaskBinary 使用 StorageMemory 的案例
回顾一下DAG的流程
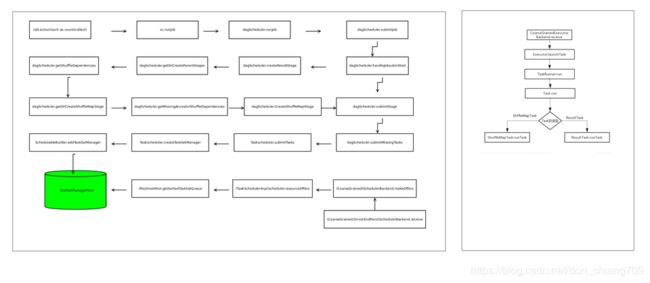
TaskBinary 使用 StorageMemory 的案
DAGSchedule里的Broadcast代码
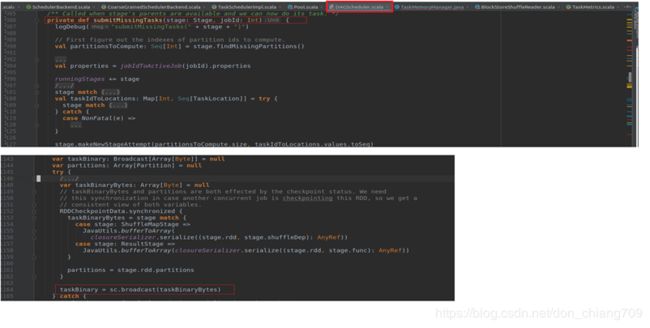
Executor端申请Storage类型的 Memory 流程

Broadcast 总结:
①broadcast 的是只读变量
②Broadcase 只读变量到每个executor,可以被该executor上的所有 task 共享。
③每个 executor 都包含一个 blockManager 用来管理存放在 executor 里的broadcast数据,数据StorageLevel 为内存+磁盘。
④Driver 先建一个本地文件夹用以存放需要 broadcast 的 data,当需要broadcast时,先把 broadcast data 序列化到 byteArray,然后切割成 BLOCK_SIZE(由 spark.broadcast.blockSize = 4MB 设置)大小的 datablock,每个 data block 被 TorrentBlock 对象持有。完成分块切割后,就将分块信息(称为 meta 信息)存放到 driver 自己的 blockManager 里面,StorageLevel 为内存+磁盘,同时会通知 driver 自己的 blockManagerMaster 说 metadata已经存放好。那么 driver submitTask() 的时候会将 bdata 的metadata 和 func 进行序列化得到 serialized task。
⑤Executor 收到 serialized task 后,先反序列化 task,这时候会反序列化 serialized task 中包含的 bdata 类型是
TorrentBroadcast,也就是去调用 TorrentBroadcast.readObject()。这个方法首先得到 bdata 对象,然后发现 bdata 里面没有包含实际的 data。怎么办?先询问所在的 executor 里的 blockManager 是会否包含 data(通过查询 data 的
broadcastId),包含就直接从本地 blockManager 读取 data。否则,就通过本地 blockManager 去连接 driver 的
blockManagerMaster 获取 data 分块的 meta 信息,获取信息后,就开始了 BT 过程。
2。Shuffle Read 应用案例分析(ExecutionMemory)
回顾一下RDD的读操作

回顾 Spark Shuffle 框架

ShuffleRead 申请 Execution Memory流程

3。RDD persist 应用案例分析(DiskStore)
RDD 申请 DiskStore 的代码
①把hadoop目录etc/hadoop下面的*-sit.xml复制到${SPARK_HOME}的conf下面.
②export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
③spark-shell --properties-file /home/yeshang/.local/bin/HiBench/report/terasort/spark/conf/sparkbench/spark.conf --master yarn
sc.setLogLevel("INFO")
////运行代码
import org.apache.spark.storage.StorageLevel
val textFile = spark.read.textFile("hdfs://localhost:9000/HiBench/Terasort/Input/part-m-00000")
textFile.persist(StorageLevel.MEMORY_AND_DISK)
textFile.count()
RDD 申请 DiskStore 的流程:
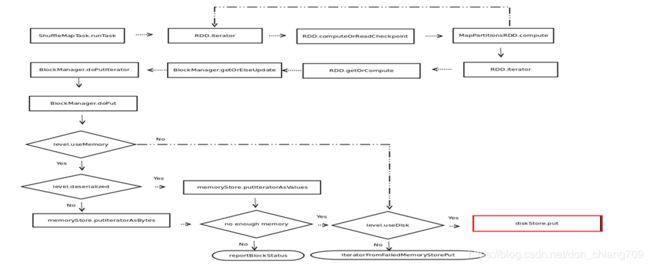
五、总结:
Storage 是 Spark Core 的背后核心子模块,没有RDD、DAG的光环,但是拥有cache manager的功能(包括提供cache(),persist(), checkpoint()),是每次RDD.iterator的必经之路。
也是shuffle writer的写或者排序,shuffle reader的缓存排序和计算完后的写必经之路。由于Storage 关联了DiskStore 和 MemoryStore(其中MemoryStore是构造 MemoryManager 的入参),Storage是 BlockManager 基础上 Disk和 Memory 的管理者。其中MemoryManager可以延展解读UnifiedMemoryManager 和 StaticMemoryManager,MemoryManager关联的MemoryAllocator 又分为 HeapMemoryAllocator(OnHeap调用New array[long] 分配内存,标志 MemoryBlock为 FREED_IN_ALLOCATOR_PAGE_NUMBER 和 赋值MemoryBlock为NULL 释放内存) 和 UnsafeMemoryAllocator(OffHeap调用Platform.allocateMemory和Platform.freeMemory接口分配和释放内存)。详情请见后续的文章“ Spark Core 的子模块 Memory” 分析。
所以说 Storage 子模块是RDD,Shuffle, Memory, Disk 和 DAG背后的合伙人
六、参考:
1.Spark source code https://github.com/apache/spark
2.图解Spark核心技术与案例实战