数据库范式与反范式
1.范式
1.1 1NF-3NF
- 定义
1NF
确保原子性(
Atomicity
)
原子性的粒度、原子性的价值(
1
范式:单值,并且把值当做单值用,建议不要把值拆开
)
2NF
检查对键的完全依赖
价值在在于控制数据冗余和查询性能
3NF
检查属性的独立性
规范化的价值
合理规范化的模型可应对需求变更
规范化数据重复降至最少
- 为什么要有三范式?
不会发生插入(
insert
)、删除(
delete
)和更新(
update
)操作异常。
控制数据冗余和提高查询性能
更好的进行数据有效性检查,提高存储效率。
范式的满足便于数据一致性的控制
- 如何控制冗余?
使用数据库三范式
- 缺点
范式化的表,在查询的时候经常需要很多的关联,因为单独一个表内不存在冗余和重复数据。这导致多次的关联,增加查询代价
可能使一些索引策略无效。因为范式化将列存放在不同的表中,而这些列在一个表中本可以属于同一个索引。
1.2
反范式(逆范式)打破范式
- 定义,为什么要有反范式?
等级越高的范式设计出来的表越多,可能会增加查询所需时间。当我们的业务所涉及的表非常多,经常会有多表连接,并且我们对表的操作要时间上要尽量的快,这时可以考虑我们使用“反范式”。
反范式
用空间来换取时间,引入受控的数据冗余,当查询时可以减少或者是避免表之间的关联
- 优点
可以避免关联,因为所有的数据几乎都可以在一张表上显示;
可以设计有效的索引;
- 缺点
提高了对数据冗余的维护,为了保证数据的一致性(可以用触发器来解决这个问题,某个表被修改后触发另一个表的更新)
- 反范式的7种模式,并举例。
①一对一:合并表
如果双方都是完全参与,那么某个表直接可以作为另一张表的属性直接合并。若有一方是部分参与,把完全参与的并入部分参与的会出现空值,将部分参与并入完全参与的可以。若双方都是部分参与,一定会出现空值,这样就很难确定主键
例子:员工表(员工编号,姓名,住址,薪水,科室编号) 亲属表(员工编号,亲属姓名,亲属电话),其中亲属表中只登记一位亲属,如果要查询张三的亲属的电话,就要连接两张表,所以将两张表合并以减少连接。
②一对多:复制非关键字以减少连接
适用条件:当两张表连接时,最主要的事务都与某个非键值相关
例子:
两个表(用户id,好友id)和(用户id,用户昵称,用户邮箱,联系电话)符合3NF,如果需查询某个用户的好友(昵称)名单,此时需对2个表进行连接查询,可以把第一个表修改成(用户id,好友id,好友昵称)这样只需要查询第一个表就可获取所有好友昵称.
③一对多:复制关键字以减少连接
复制一对多关系中的外键,使需要通过第三张表连接的两张表直接关连在一起
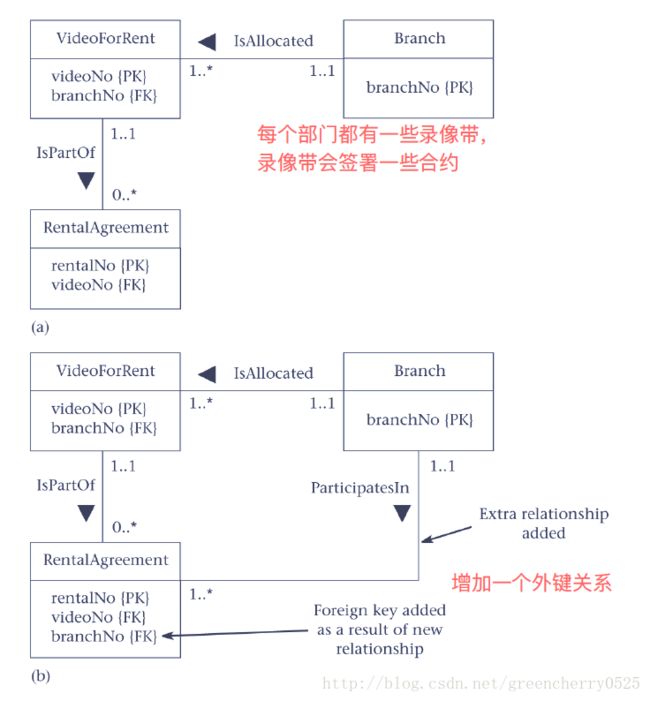
在一对多的关系中,将另一实体表的主键复制到多的实体表当外键,减少join表的数量
例子:每个部门租了一些录像带,每盘录像带是有
租赁协议的。这样
有三张表:部门(部门编号),租的录像(录像带编号,部门编号),租赁协议,见下图关系表
④多对多:关系里面复制值以减少连接
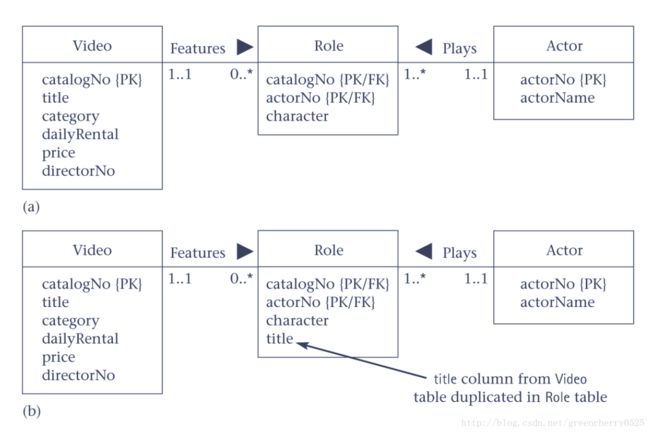
引入一张新表,多对多被拆成两个一对多(满足3NF)。
假设要查询,演员演了哪些电影,为了避免三张表连接,就在role表中复制电影名称以减少连接
⑤引入重复组
引入重复组,重复组一般不超过10个 (对于一个多值属性,如果多值的数量不多小于等于10)
例子:customer 可能有多个address。一般是customer一张表,address一张表,address中存储它对应的customer的ID那么每次付款的时候,需要再查找address表来得到customer的所有地址。可以在customer后面加addr1、addr2字段,但不知道要加多少个,不好。较为常见的做法是,在customer表中引入一条addr字段,放最常用地址,address表中存储所有地址。
⑥提取表
extract table的表中内容和原表可能都相同,只是组织结构不同,有可能一个是为了查询而建的表(将经常被查询的数据提前计算出来存入该表,会有大量冗余,但是提高效率),另一个是为了update的,一定程度上实现了读写分离。
比如有学生表,宿舍表,为了查学生的住宿费,需要连接两表。此时可以提取出一张用于查询的表,其中包含了学生姓名,住宿费用以及其他字段,方便查询。
⑦使用分区表
可以将表分解成更少的分区。
水平分区:跨多个(较小)的表分配记录。
这种形式分区是对表的行进行分区,通过这样的方式不同分组里面的物理列分割的数据集得以组合,从而进行个体分割(单分区)或集体分割(1个或多个分区)。所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。
例子:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录。
垂直分区:跨多个(较小)表分布列。 PK复制,以便重建。
垂直分区(Vertical Partitioning) 这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
例子:
一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。