tensorflow实战之LeNet-5实现mnist手写字体识别
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data#用mnist数据训练#input代表输入数据
#train代表是否是训练过程
#regulation代表是否加入正则化
def inference(input,train,regulation):
#第一层卷积,卷积核size为[5,5,1,6]
with tf.variable_scope('conv1'):
weight1 = tf.get_variable('weight1',shape=[5,5,1,6],initializer=tf.truncated_normal_initializer(stddev=0.1))
bias1 = tf.get_variable('bias1',shape=[6],initializer=tf.constant_initializer(0.0,dtype=tf.float32))
conv1 = tf.nn.conv2d(input,weight1,strides=[1,1,1,1],padding='VALID')
activation1 = tf.nn.relu(tf.nn.bias_add(conv1,bias1))
#第一层池化
with tf.variable_scope('pool1'):
pool1 = tf.nn.max_pool(activation1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#第二层卷积,卷积核size为[5,5,6,16]
with tf.variable_scope('conv2'):
weight2 = tf.get_variable('weight2',shape=[5,5,6,16],initializer=tf.truncated_normal_initializer(stddev=0.1))
bias2 = tf.get_variable('bias2',shape=[16],initializer=tf.constant_initializer(0.0,dtype=tf.float32))
conv2 = tf.nn.conv2d(pool1,weight2,strides=[1,1,1,1],padding='VALID')
activation2 = tf.nn.relu(tf.nn.bias_add(conv1,bias2))
#第二层池化
with tf.variable_scope('pool2'):
pool2 = tf.nn.max_pool(activation2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#把第二层池化层变为全连接层
pool2_shape = pool2.get_shape().as_list()
nodes = pool2_shape[1] * pool2_shape[2] * pool2_shape[3]
pool2_reshape = tf.reshape(pool2,[-1,nodes])
#第一层全连接层
with tf.variable_scope('pc1'):
weight3 = tf.get_variable('weight3',shape=[nodes,120],initializer=tf.truncated_normal_initializer(stddev=0.1))
#判断是否有正则化
if regulation != None:
tf.add_to_collection('loss_',regulation(weight3))
b1 = tf.get_variable('bais',shape=[120],initializer=tf.constant_initializer(0.1))
pc1 = tf.matmul(pool2_reshape,weight3)+ b1
activation3 = tf.nn.relu(pc1)
#判断是否为训练过程,是的话加入dropout
if train != None:
activation3 = tf.nn.dropout(activation3,0.8)
with tf.variable_scope('pc2'):
weight4 = tf.get_variable('weight4',shape=[120,84],initializer=tf.truncated_normal_initializer(stddev=0.1))
#判断正则化
if regulation != None:
tf.add_to_collection('loss_',regulation(weight4))
b2 = tf.get_variable('bais2',shape=[84],initializer=tf.truncated_normal_initializer(stddev=0.1))
pc2 = tf.matmul(activation3,weight4) + b2
activation4 = tf.nn.relu(pc2)
#判断是否为训练过程,是的话加入dropout
if train != None:
activation4 = tf.nn.dropout(activation4,0.8)
with tf.variable_scope('pc3'):
weight5 = tf.get_variable('weight5',shape=[84,10],initializer=tf.truncated_normal_initializer(stddev=0.1))
#判断正则化
if regulation != None:
tf.add_to_collection('loss_',regulation(weight5))
b3 = tf.get_variable('b3',shape=[10],initializer=tf.truncated_normal_initializer(stddev=0.1))
pc3 = tf.matmul(activation4,weight5)+b3
activation6 = tf.nn.relu(pc3)
return activation6#用mnist数据集训练网络
def train(mnist):
x = tf.placeholder(tf.float32,[None,28,28,1])
y_ = tf.placeholder(tf.float32,[None,10])
#训练过程给到正则化
regulation = tf.contrib.layers.l2_regularizer(0.0001)
#前向传播的值
y = inference(x,train=1,regulation=regulation)
#迭代轮数
global_step = tf.Variable(0,trainable=False)
#滑动平均
average_moving_deacy = tf.train.ExponentialMovingAverage(0.99,global_step)
average_moving_deacy_op = average_moving_deacy.apply(tf.trainable_variables())
#交叉熵损失函数
entory_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.arg_max(y_,1),logits=y)
entory_loss_mean = tf.reduce_mean(entory_loss)
#带正则化的损失函数
loss = entory_loss_mean + tf.add_n(tf.get_collection('loss_'))
#学习率衰减
learning_rate_deacy = tf.train.exponential_decay(0.8,global_step=global_step,decay_steps=mnist.train.num_examples/100,decay_rate=0.99)
#训练
train_step = tf.train.GradientDescentOptimizer(learning_rate_deacy).minimize(loss,global_step=global_step)
#滑动平均和训练过程同时进行
train_op = tf.group(train_step,average_moving_deacy_op)
#初始化
init_op = tf.global_variables_initializer()
#定义模型保存类
saver = tf.train.Saver()
with tf.Session() as sess:
init_op.run()
#总共训练10000次
for i in range(30000):
#训练数据
x_data,y_data = mnist.train.next_batch(batch_size=100)
#把输入数据的格式转化为网络需要的格式
x_data = np.reshape(x_data,[100,28,28,1])
train_feed = {x:x_data,y_:y_data}
#返回损失值
_,loss_values = sess.run([train_op,loss],feed_dict=train_feed)
#没训练1000次返回一次损失值,并保存一次模型
if i % 1000 == 0:
print('训练%d次后当前损失值为%g'%(i+1,loss_values))
saver.save(sess,'model/model.ckpt')
mnist = input_data.read_data_sets('data',one_hot=True)
train(mnist)训练结果:
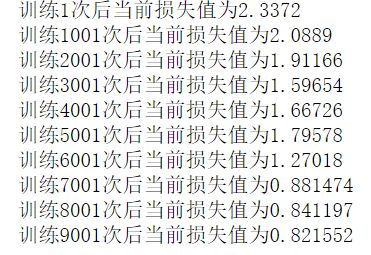
#用mnist数据集来测试
def test(x_data,y_data):
x = tf.placeholder(tf.float32,[None,28,28,1])
y_ = tf.placeholder(tf.float32,[None,10])
#前向传播
y = inference(x,None,None)
#精确度
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.arg_max(y_,1),tf.arg_max(y,1)),tf.float32))
#滑动平均
ema = tf.train.ExponentialMovingAverage(decay=0.99)
variables_restore = ema.variables_to_restore()
#加载模型类
saver = tf.train.Saver(variables_restore)
with tf.Session() as sess:
#查找最新模型
ckpt = tf.train.get_checkpoint_state('model/')
x_data = np.reshape(x_data,[-1,28,28,1])
test_feed = {x:x_data,y_:y_data}
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,'model/model.ckpt')
acc = sess.run(accuracy,feed_dict=test_feed)
print('测试集准确率%g'%(acc))
return acc准确率为:0.9941
欢迎关注公众号“阿甘琐记”,专注机器学习资源分享