JDK8 - lambda表达式、函数接口、级联表达式和柯里化、方法引用、Stream流编程、JDK9 - Reactive Stream
Lambda表达式
- 常规写法
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("测试");
}
};
new Thread(runnable).start();
- lambda写法
/**
* 箭头左侧的括号为方法的参数,无参只写一个括号
* 有参写法(int a,int b) -> {//方法体},简写,(a,b) -> {//方法体}
* 箭头右侧为方法的执行体
*/
Runnable runnable1 = () -> System.out.println("测试");
new Thread(runnable).start();
/**
* lambda表达式就是返回了一个实现了指定接口的对象实例,需要告诉他返回的类型
* () -> System.out.println("测试")其实是函数调用的方式,
* 需要告诉他返回的对象的要实现的接口类型,
* 所以下面写了强转的方式也是可以的
*/
Object runnable2 = (Runnable)() -> System.out.println("测试");
new Thread((Runnable)runnable2).start();
接口新特性
- @FunctionalInterface注解
上面的lambda表达式,对接口是有限制的,就是这个接口里面只有一个要实现的方法。
比如Runnable里只有一个run方法需要实现,Callable里只有一个call方法需要实现,不然如果有多个方法,那表达式的写法不知道作用于哪个方法,也就是函数式接口。
新增的注解:@FunctionalInterface,该注解用于标识接口为函数式接口,它不是必须的,可加可不加,养成良好编码习惯建议是要加上的,如果里面存在多个要实现的方法,会有报错提示,如下:
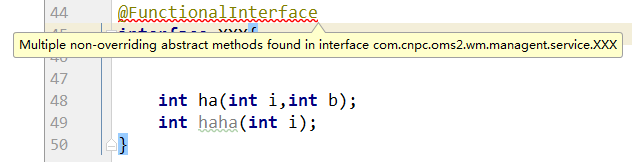
- 接口默认方法
jdk8里面新增了一个默认的方法是用default修饰的方法叫默认方法,接口里面这个方法有默认的实现。
@FunctionalInterface
interface XXX{
int ha(int i,int b);
default int haha(int i,int b,int c){
return i+b+c;
}
}
public class Testt {
public static void main(String[] args) {
XXX xxx = (i,b) -> i*b;
System.out.println(xxx.ha(7,5));//调用需要实现的方法
System.out.println(xxx.haha(1,2,3));//调用默认方法
}
}
接口默认方法理解:假设有一个接口,里面有很多方法,也有很多个类已经实现了里面的方法,程序正常运行,如果此时需要在该接口里新加一个方法,那么所有实现了的地方都要重改。
比如List接口,在1.2版本到1.7版本都没任何改变,在1.8版本,新增了一个默认方法,他之前如果修改List接口,那么会导致什么就不用说了吧。
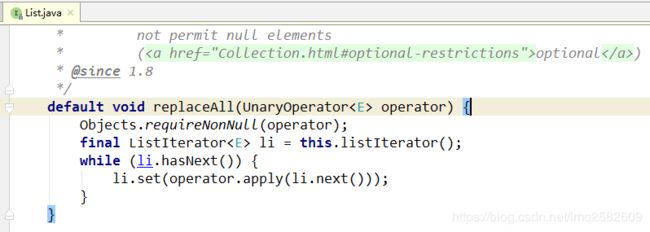
不过lambda表达式写的话不冲突,default只是默认方法,而且有默认实现,lambda表达式还是会去寻找那么未实现的方法的。可以把默认方法当做是类里面的方法理解就行了。
如果接口有多继承的情况,比如接口1里有默认方法,接口2里有默认方法,接口3实现了接口1和接口2,软件会有报错提示,会让你指明要用哪个默认方法。
函数接口
- Function
@FunctionalInterface
interface XXX{
int ha(int i);
}
class TTT{
private final int age = 30;
public void ride(XXX xxx){
System.out.println("多大岁数了:"+xxx.ha(age) + "了都");
}
}
public class Testt {
public static void main(String[] args) {
TTT ttt = new TTT();
ttt.ride(i -> i);
}
}
输出:多大岁数了:30了都
理解:
代码中的ttt.ride(i -> i);,其中i -> i,箭头左侧为输入的类型,箭头右侧为输出的类型,那么只需要关注输入和输出类型即可,将代码修改如下:
class TTT{
private final int age = 30;
public void ride(Function xxx){
System.out.println("多大岁数了:"+xxx.apply(age) + "了都");
}
}
public class Testt {
public static void main(String[] args) {
TTT ttt = new TTT();
Function function = i -> i;
ttt.ride(function);
}
}
多大岁数了:30了都
直接省略了一个接口,ride方法的参数类型变成了Function,泛型第一个是输入的类型,第二个是输出的类型,然后调用Function接口的apply方法。使用函数接口的好处就是不用定义那么多的接口了,另一个好处是支持链式操作,就是Function接口的andThen方法。
class TTT{
private final int age = 30;
public void ride(Function xxx){
System.out.println("多大岁数了:"+xxx.apply(age) + "了都");
}
}
public class Testt {
public static void main(String[] args) {
TTT ttt = new TTT();
Function function = i -> i;
//函数接口链式操作
ttt.ride(function.andThen(s -> 5 + s));
}
}
输出:多大岁数了:35了都
- 自带的函数接口
函数接口都是通用的,会了一个,其他的也就会了。
| 接口 | 输入参数类型 | 返回类型 | 说明 |
|---|---|---|---|
| Predicate | T | boolean | 断言 |
| Consumer | T | / | 消费一个数据 |
| Function |
T | R | 输入T输出R的函数 |
| Supplier | / | T | 提供一个数据 |
| UnaryOperator | T | T | 一元函数(输入输出类型相同) |
| BiFunction |
(T,U) | R | 2个输入的函数 |
| BinaryOperator | (T,T) | T | 二元函数(输入输出类型相同) |
测试代码:
public class Testt {
public static void main(String[] args) {
//断言 测试传入的5是否小于0
Predicate predicate = (i) -> i < 0;
boolean test = predicate.test(5);//返回false
//Consumer消费 有入参 调用accept方法返回类型是void
Consumer consumer = (s) -> System.out.println(s);
consumer.accept("what?");
//Supplier供应 无入参 返回类型就是泛型里规定的
Supplier supplier = () -> "what?";
String s = supplier.get();//返回what?
//UnaryOperator 输入参数类型和返回类型一致
UnaryOperator unaryOperator = (a) -> a + " are you doing?";
String what = unaryOperator.apply("what");//返回what are you doing?
//BiFunction 两个入参,一个返回参数
BiFunction biFunction = (b,c) -> Integer.valueOf(b) + Integer.valueOf(c);
Integer apply = biFunction.apply("58", "2");//返回60
//BinaryOperator 两个入参和一个返回类型一致
BinaryOperator binaryOperator = (d,f) -> d+f;
Integer apply1 = binaryOperator.apply(58, 2);//返回60
}
}
方法引用
- 静态方法的方法引用
class TTT{
public static void ride(String str){
System.out.println("你是谁:"+str);
}
}
public class Testt {
public static void main(String[] args) {
Consumer consumer = TTT::ride;//使用类名+两个冒号
consumer.accept("我叫赵山河");//传入参数
}
}
- 非静态方法的方法引用
class TTT{
public String ride(String str){
System.out.println("你是谁:");
return str;
}
}
public class Testt {
public static void main(String[] args) {
TTT ttt = new TTT();
Function function = ttt::ride;//使用实例+两个冒号
System.out.println(function.apply("我叫赵山河"));//传入参数
}
}
这里面输入是String类型,输出是String类型,可将Function改为:
UnaryOperator function = ttt::ride;
另一种写法
class TTT{
public String ride(String str){
System.out.println("你是谁:");
return str;
}
}
public class Testt {
public static void main(String[] args) {
TTT ttt = new TTT();
BiFunction function = TTT::ride;//使用类名+两个冒号+方法名
System.out.println(function.apply(ttt,"我叫赵山河"));
}
}
这里也是使用了类名+两个冒号+方法名访问,和之前的访问静态方法类似,区别是ride方法,虽然定义的参数是一个String类型,但实际默认还会传入一个this参数,如下:
public String ride(TTT this,String str){
System.out.println("你是谁:");
return str;
}
所以使用BiFunction函数接口,第一个参数是TTT类,第二个参数是String,第三个参数是String。
- 构造函数方法引用
无参构造函数
class TTT{
public TTT(){}//这里为了演示清楚,显示的写了一个无参构造,默认是隐式的自动会有
}
public class Testt {
public static void main(String[] args) {
Supplier supplier = TTT::new;//使用类名+两个冒号+new关键字
System.out.println("创建了对象:" + supplier.get());
}
}
有参构造函数
class TTT{
private String s;
public TTT(String str){
this.s = str;
}
}
public class Testt {
public static void main(String[] args) {
Function function = TTT::new;
System.out.println("创建了对象:"+ function.apply("我叫赵山河"));
}
}
变量引用
内部类引用外部变量,这个变量必须声明为final类型。lambda表达式如下:
public class Testt {
public static void main(String[] args) {
String str = "哈哈";
Consumer consumer = s -> System.out.println(s+str);//引用外部变量
consumer.accept("what?");
}
}
这里用lambda表达式引用了外部的str变量是没有加final的,不过它是会默认加了的,这个str已经是不可修改的了,修改会报错:

那么为什么内部类引用外部的变量要是final?因为java里传参的形式是传值,而不是传引用
,比如:
public class Testt {
public static void main(String[] args) {
List list = new ArrayList<>();
Consumer consumer = s -> System.out.println(s+list);
consumer.accept("what?");
}
}
内部类里访问了list,传入的list此时已经不可修改了,因为传入list的时候实际上传的是new ArrayList<>()对象,也就是说在外部有一个list变量,在内部类里面也有一个list变量,这是两个变量,然后两个变量都指向了new ArrayList<>()对象,这就是传值。假设list创建的时候是List list = new ArrayList<>();指向了new ArrayList<>()对象,在后面如果把list改变了,指向了另外一个list,那内部类里的System.out.println(s+list);就可能导致list指向的还是原来初始化指向的new ArrayList<>()对象,而改变了list就会导致结果是不正确的,这就是为什么要用final修饰。
级联表达式和柯里化
级联表达式就是有多个箭头的lambda表达式。
比如:a -> b -> a * b;
public class Testt {
public static void main(String[] args) {
Function> function = a -> b -> a * b;
System.out.println("乘法运算:"+function.apply(3).apply(4));
}
}
理解:分析输入输出参数类型,如下我画了个图:

柯里化:如上Function里嵌套了Function,传参的时候,每次就只传1个参数,所以柯里化就是把多个参数的函数转换为只有一个参数的函数。也就是这段代码:
function.apply(3).apply(4)
柯里化的目的:函数标准化。
public class Testt {
public static void main(String[] args) {
Function>> function = a -> b -> c -> a * b * c;
System.out.println("乘法运算:"+function.apply(3).apply(4).apply(5));
}
}
理解了以后,还可将上面的代码改下为:
public class Testt {
public static void main(String[] args) {
Function>> function = a -> b -> c -> a * b * c;
int [] nums = {3,4,5};
for (int i = 0;i < nums.length; i++){
if(function instanceof Function){
Object obj = function.apply(nums[i]);
if(obj instanceof Function){
function = (Function) obj;
}else{
System.out.println("结束,乘法运算:"+obj);
}
}
}
}
}
柯里化以后的好处是所有的函数都是一个样子,可以批量来处理。
Stream流编程
- 概念:
它是一个高级的迭代器,它不是一个数据结构,它不是一个集合,它不会存放数据。stream关注的是如何把数据高效的处理。
- 外部迭代和内部迭代
public class Testt {
public static void main(String[] args) {
//外部迭代
int [] nums = {3,4,5};
int sum = 0;
for (int i : nums){
sum += i;
}
System.out.println("求和:"+sum);
//stream内部迭代
int sum2 = IntStream.of(nums).sum();
System.out.println("求和:"+sum2);
}
}
- 中间操作/终止操作和惰性求值
public class Testt {
public static void main(String[] args) {
int [] nums = {3,4,5};
//map就是中间操作(返回stream的操作)
//sum就是终止操作
int sum2 = IntStream.of(nums).map(i -> i * 2).sum();
System.out.println("求和:"+sum2);
}
}
map操作是将流中的元素映射成另外一种元素,接受一个Function类型的参数,是一个中间操作,中间操作返回类型是流。
代码里的map为中间操作,让每个数都乘以2,sum是终止操作为求和。
惰性求值就是终止操作没有调用的情况下,中间操作不会执行。感觉类似懒汉模式。也就是在没有调用sum的时候,中间操作不会执行。
区分中间操作和终止操作只需要关注它的返回类型,返回的是流那它就是中间操作,否则就是终止操作。
- Stream流的创建
| 常见 | 相关方法 |
|---|---|
| 集合 | Collection.stream/parallelStream |
| 数组 | Arrays.stream |
| 数字Stream | IntStream/ LongStream.range/rengeClosed 和 Random.ints/longs/doubles |
| 自己创建 | Stream.generate/iterate |
public class Testt {
public static void main(String[] args) {
List list = new ArrayList<>();
//从集合创建
list.stream();
list.parallelStream();//并行流
//从数组创建
Arrays.stream(new int [] {3,4,5});
//数字流
IntStream.of(1,2,3);
IntStream.range(1,3);
//使用random创建一个无限流
new Random().ints().limit(10);
//自己创建
Random random = new Random();
Stream.generate(() -> random.nextInt()).limit(10);
}
}
- Stream流的中间操作
无状态操作:map/maptoXxx,flatMap、flatMapToXxx,filter,peek,unordered
有状态操作:distinct,sorted,limit/skip
理解:无状态标识当前的操作跟其他元素的前后没有依赖关系,有状态标识我现在的结果要依赖于其他的一些元素。比如排序操作,它就依赖所有的元素都计算完毕,它才有一个最终的排序结果,这就是有状态操作。
这些中间操作他们都返回的是一个stream流,可以继续链式调用下去。
map:
String str = "123-456-789-1234-5678-9012";
//切分字符串为数组,并输出每个的长度
Stream.of(str.split("-")).map(i -> i.length()).forEach(System.out::println);
String str = "123-456-789-1234-5678-9012";
//切分字符串为数组,加filter过滤条件,长度大于3的输出
Stream.of(str.split("-")).filter(i -> i.length() > 3).map(i -> i.length()).forEach(System.out::println);
flatMap:
String str = "123-456-789-1234-5678-9012";
//flatMap A->B属性(是个集合),最终得到A元素里面的所有B属性的集合
//IntStream/longStream 并不是Stream的子类,所以要进行装箱 boxed
Stream.of(str.split("-")).flatMap(i -> i.chars().boxed()).forEach(i -> System.out.println((char)i.intValue()));
针对str变量来说,A属性就是123、456、789......9012,它下面的B属性就是单个字符1、2、3,4、5、6......9、0、1、2。
在比如下面代码可能更容易理解:
//流创建了3个list,返回了 Stream>
Stream> inputStream = Stream.of(Arrays.asList(1),Arrays.asList(2, 3), Arrays.asList(4, 5, 6));
//使用flatMap,返回了 Stream
Stream outputStream = inputStream.flatMap((childList) -> childList.stream());
outputStream.forEach(s -> System.out.print(s));//输出123456,将之前的3个集合打平,返回其下面的子元素
peek:
String str = "123-456-789-1234-5678-9012";
//peek 用于debug,是个中间操作,forEach是终止操作
Stream.of(str.split("-")).peek(System.out::println).forEach(System.out::println);
limit:
//limit用于无限流
//随意生成10个随机数
new Random().ints().limit(10).forEach(System.out::println);
//对随机数加限制条件
new Random().ints().filter(i -> i > 100 && i <1000).limit(10).forEach(System.out::println);
- Stream流的终止操作
非短路操作:forEach/forEachOrdered、collect/toArray、reduce、min/max/count
短路操作:findFirst/findAny、allMatch/anyMatch/noneMatch
理解:短路操作就是不需要等待计算结果就可以结束流,比如findFirst/findAny,得到一个数据或者得到任何一个数据,这个流就可以结束了, 非短路操作相反。
forEachOrdered:
String str = "123-456-789-1234-5678-9012";
//使用并行流,无序 输出->--7-6523-145890163412798-2
str.chars().parallel().forEach(i -> System.out.print((char) i));
//使用forEachOrdered保证有序 输出->123-456-789-1234-5678-9012
str.chars().parallel().forEachOrdered(i -> System.out.print((char) i));
collect:
String str = "123-456-789-1234-5678-9012";
//collect收集器,收集到list,有点像string转list
List list = Stream.of(str.split("-")).collect(Collectors.toList());
//输出:[123, 456, 789, 1234, 5678, 9012]
//collect收集器,收集到set
Set set = Stream.of(str.split("-")).collect(Collectors.toSet());
//输出:[123, 9012, 456, 1234, 789, 5678]
// 字符串拼接
String collect = Stream.of("a", "b", "c", "d").collect(Collectors.joining());
String str = "123-456-789-1234-5678-9012";
//使用reduce拼接字符串,Optional选项的意思,避免你做一些非空判断
Optional reduce = Stream.of(str.split("-")).reduce((a, b) -> a + "|" + b);
System.out.println(reduce.orElse(""));//reduce.orElse("")相当于if == null else 返回空串
//为reduce加一个默认值为空串,那么返回的就直接是个String了
String reduce1 = Stream.of(str.split("-")).reduce("", (a, b) -> a + "|" + b);
System.out.println(reduce1);
//使用map和reduce求和
Integer reduce2 = Stream.of(str.split("-")).map(s -> s.length()).reduce(0, (a, b) -> a + b);
System.out.println(reduce2);
reduce这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。
- 并行流
//非并行流
IntStream.range(1,10).peek(TTT::stream).count();
//调用parallel()产生一个并行流
IntStream.range(1,10).parallel().peek(TTT::stream).count();
//TTT::stream方法
class TTT{
public static void stream(int a){
System.out.println(Thread.currentThread().getName() + ":" +a);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
并行流使用的线程池:ForkJoinPool.commonPool,该线程池数量为当前机器的cpu个数。修改线程数:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","20");
IntStream.range(1,100).parallel().peek(TTT::stream).count();
如果程序内所有的并行流都使用同一个线程池,那么就会出现阻塞。所以在某些场景,可以使用我们自己的线程池,这样就不会阻塞了。
//使用自己的线程池,不使用默认的线程池,放置任务阻塞
ForkJoinPool pool = new ForkJoinPool(20);
pool.submit(() -> IntStream.range(1, 100).parallel().peek(TTT::stream).count());
pool.shutdown();
//测试代码,防止主线程先退出
synchronized (pool){
try{
pool.wait();
}
catch (InterruptedException e){
e.printStackTrace();
}
}
- 收集器
收集器就是把流处理后的数据收集起来。
以List>格式的数据为例:
public class Testt {
public static final DateTimeFormatter DATETIME_FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args) {
List> list = new ArrayList<>();
//构造了List Collectors为java8提供的工具类,使用方式查看api就可以了。

以下是在网上粘过来的常用方法和使用示例:
| 工厂方法 | 返回类型 | 用于 |
| toList | List |
把流中所有元素收集到List中 |
| 示例:List | ||
| toSet | Set |
把流中所有元素收集到Set中,删除重复项 |
| 示例:Set | ||
| toCollection | Collection |
把流中所有元素收集到给定的供应源创建的集合中 |
| 示例:ArrayList | ||
| Counting | Long | 计算流中元素个数 |
| 示例:Long count=Menu.getMenus.stream().collect(counting); | ||
| SummingInt | Integer | 对流中元素的一个整数属性求和 |
| 示例:Integer count=Menu.getMenus.stream().collect(summingInt(Menu::getCalories)) | ||
| averagingInt | Double | 计算流中元素integer属性的平均值 |
| 示例:Double averaging=Menu.getMenus.stream().collect(averagingInt(Menu::getCalories)) | ||
| Joining | String | 连接流中每个元素的toString方法生成的字符串 |
| 示例:String name=Menu.getMenus.stream().map(Menu::getName).collect(joining(“, ”)) | ||
| maxBy | Optional |
一个包裹了流中按照给定比较器选出的最大元素的optional 如果为空返回的是Optional.empty() |
| 示例:Optional | ||
| minBy | Optional |
一个包裹了流中按照给定比较器选出的最大元素的optional 如果为空返回的是Optional.empty() |
| 示例: Optional | ||
| Reducing | 归约操作产生的类型 | 从一个作为累加器的初始值开始,利用binaryOperator与流中的元素逐个结合,从而将流归约为单个值 |
| 示例:int count=Menu.getMenus.stream().collect(reducing(0,Menu::getCalories,Integer::sum)); | ||
| collectingAndThen | 转换函数返回的类型 | 包裹另一个转换器,对其结果应用转换函数 |
| 示例:Int count=Menu.getMenus.stream().collect(collectingAndThen(toList(),List::size)) | ||
| groupingBy | Map |
根据流中元素的某个值对流中的元素进行分组,并将属性值做为结果map的键 |
| 示例:Map |
||
| partitioningBy | Map |
根据流中每个元素应用谓语的结果来对项目进行分区 |
| 示例:Map |
||
- Stream运行机制
1、所有操作都是链式,一个元素只迭代一次。比如.map(......).filter(......),会先执行map,在执行filter,依次的,不会等所有的map都执行完在执行filter,所以一个元素只迭代一次。
2、每一个中间操作都返回一个新的流,流里面有一个属性sourcesStage,指向同一个地方,就是链表的头,Head。
3、Head指向nextStage在指向nextStage知道nextStage为null
4、有状态操作会把无状态操作截断单独处理。
5、并行环境下有状态的中间操作不一定能并行操作。
6、parallel/sequetial 这2个操作也是中间操作(也是返回stream),但是他们跟其他的有区别,他们不创建流,他们只修改Head的并行标志。
JDK9 - Reactive Stream
概念: 它是JDK9引入的一套标准,是一套基于发布/订阅者模式的数据处理的机制。它和stream流编程并没有特别大的关系。
背压: 发布者跟订阅者之间的一个交互。就是发布者和订阅者之间可以交流。订阅者可以告诉发布者我这里需要多少数据,比如我现在数据处理完了,就可以多拿一些数据过来。我现在没处理完,那就先不要给我数据。可以起到调节数据流量的作用。也不会导致发布者那边过多的产生数据,导致数据浪费。或者说发布者创建了太多数据,全部发给订阅者,把订阅者这边压垮。
背压举例: 比如我们每天都是用的自来水。自来水公司就是一个发布者,我们每家每户就是订阅者。水就是数据,在以前老的模式下,我们的订阅者(每家每户)它是一个被动接收的概念,那么自来水公司只要有水就会源源不断的发过来,那么我们只能被动接受,不管你需不需要水你都没法控制,只能接收。有了背压以后,我们相当于有了一个水龙头,对水(数据)的需求是可控的,需要就打开水龙头,不需要就关闭水龙头。
- Reactive Stream主要接口
Java 9 通过java.util.concurrent.Flow 和java.util.concurrent.SubmissionPublisher 类来实现响应式流。
Flow 类中定义了四个嵌套的静态接口,用于建立流量控制的组件,发布者在其中生成一个或多个供订阅者使用的数据项:
- Publisher:数据项发布者、生产者
- Subscriber:数据项订阅者、消费者
- Subscription:发布者与订阅者之间的关系纽带,订阅令牌
- Processor:数据处理器
发布/订阅Demo
package xxx;
import java.util.concurrent.Flow.Subscriber;
import java.util.concurrent.Flow.Subscription;
import java.util.concurrent.SubmissionPublisher;
public class Reactive {
public static void main(String[] args) throws Exception{
//1.定义发布者,发布的数据类型是Integer
//使用JDK自带的SubmissionPublisher,它实现了Publisher接口
SubmissionPublisher publisher = new SubmissionPublisher();
//2.定义订阅者
Subscriber subscriber = new Subscriber(){
private Subscription subscription;
@Override
public void onSubscribe(Subscription subscription) {
//保存订阅关系,需要用它来给发布者响应
this.subscription = subscription;
//请求一个数据
this.subscription.request(1);
}
@Override
public void onNext(Object item) {
//当有数据到了的时候出发该方法
//接收到一个数据,处理
System.out.println("接收到数据:"+item);
//处理完在调用request再请求一个数据
this.subscription.request(1);
//或者 已经达到目标,调用cancel告诉发布者不再接收数据了
//this.subscription.cancel();
}
@Override
public void onError(Throwable throwable) {
//出错时,触发该方法
//出现了异常(例如处理数据(onNext中)的时候产生了异常)
throwable.printStackTrace();
//异常后还可以告诉发布者,不再接收数据了
this.subscription.cancel();
}
@Override
public void onComplete() {
//数据全部处理完了(发布者关闭了)
//publisher.close()方法后触发该方法
System.out.println("处理完毕!");
}
};
//3.发布者和订阅者 建立订阅关系
publisher.subscribe(subscriber);
//4.生产数据,并发布
//这里忽略数据生产过程
publisher.submit(111);//发送1条
publisher.submit(222);//发送1条
publisher.submit(333);//发送1条
//5.结束后,关闭发布者
//正式环境 应该放finally或者使用try-resouce确保关闭
publisher.close();
//主线程延时停止,否则数据没有消费就退出
Thread.currentThread().join(1000);
}
}
发布/订阅 - 带发布者过滤器Demo
package xxx;
import java.util.concurrent.Flow.Subscriber;
import java.util.concurrent.Flow.Processor;
import java.util.concurrent.Flow.Subscription;
import java.util.concurrent.SubmissionPublisher;
/**
* 发布者过滤器
* Processor,需要继承SubmissionPublisher并实现Processor接口
* 输入源数据integer,过滤掉小于0的,然后转成字符串发布出去
*/
class ImplProcessor extends SubmissionPublisher implements Processor {
private Subscription subscription;
@Override
public void onSubscribe(Subscription subscription) {
//保存订阅关系,需要用它来给发布者响应
this.subscription = subscription;
//请求一个数据
this.subscription.request(1);
}
@Override
public void onNext(Integer item) {
//接收到一个数据,处理
System.out.println("准备发送的数据:"+item);
//过滤掉小于0的数据,然后发布出去
if(item > 0){
this.submit("处理后待发送的数据:"+item);
}
//处理完在调用request再请求一个数据
this.subscription.request(1);
//或者 已经达到目标,调用cancel告诉发布者不再接收数据了
//this.subscription.cancel();
}
@Override
public void onError(Throwable throwable) {
//出错时,触发该方法
throwable.printStackTrace();
//异常后还可以告诉发布者,不再接收数据了
this.subscription.cancel();
}
@Override
public void onComplete() {
//处理器处理完毕
System.out.println("处理器处理完毕!");
//关闭发布者
this.close();
}
}
public class MyProcessor{
public static void main(String[] args)throws Exception {
//1.定义发布者,发布的数据类型是Integer
SubmissionPublisher publisher = new SubmissionPublisher();
//2.定义处理器,对数据进行过滤,并转换String类型
ImplProcessor processor = new ImplProcessor();
//3发布者 和 处理器建立订阅关系
publisher.subscribe(processor);
//4.定义最终订阅者,消费String数据
Subscriber subscriber = new Subscriber(){
private Subscription subscription;
@Override
public void onSubscribe(Subscription subscription) {
//保存订阅关系,需要用它来给发布者响应
this.subscription = subscription;
//请求一个数据
this.subscription.request(1);
}
@Override
public void onNext(Object item) {
//当有数据到了的时候出发该方法
//接收到一个数据,处理
System.out.println("接收到数据:"+item);
//处理完在调用request再请求一个数据
this.subscription.request(1);
//或者 已经达到目标,调用cancel告诉发布者不再接收数据了
//this.subscription.cancel();
}
@Override
public void onError(Throwable throwable) {
//出错时,触发该方法
//出现了异常(例如处理数据(onNext中)的时候产生了异常)
throwable.printStackTrace();
//异常后还可以告诉发布者,不再接收数据了
this.subscription.cancel();
}
@Override
public void onComplete() {
//数据全部处理完了(发布者关闭了)
//publisher.close()方法后触发该方法
System.out.println("订阅者数据处理完毕!");
}
};
//5.处理器 和 最终订阅者建立关系
processor.subscribe(subscriber);
//6.生产数据,并发布
//这里忽略数据生产过程
publisher.submit(-111);//发送1条 - 此条数据会被过滤掉
publisher.submit(222);//发送1条
publisher.submit(333);//发送1条
//7.结束后,关闭发布者
//正式环境 应该放finally或者使用try-resouce确保关闭
publisher.close();
//主线程延时停止,否则数据没有消费就退出
Thread.currentThread().join(1000);
}
}
完~如有错误请指出,欢迎一起加群交流43827511。