jieba中文叫做结巴,是一款中文分词工具,官方文档链接:https://github.com/fxsjy/jieba
gensim.word2vec中文叫做词向量模型,是是用来文章内容向量化的工具。
gensim.word2vec官方文档链接:https://radimrehurek.com/gensim/models/word2vec.html
LogisticRegression中文叫做逻辑回归模型,是一种基础、常用的分类方法。
完整项目压缩文件基于word2vec的文本分类.zip上传到百度云盘。
下载链接: https://pan.baidu.com/s/15qcM9rh2AzFyUNkeA61WPA 提取码: awpk
0.环境配置
建议读者安装anaconda,这个集成开发环境自带了很多包。
Anaconda5.2百度网盘下载链接: https://pan.baidu.com/s/1pbzVbr1ZJ-iQqJzy1wKs0A 密码: g6ex
官网下载地址:https://repo.anaconda.com/archive/Anaconda3-5.2.0-Windows-x86_64.exe
下面代码的开发环境为jupyter notebook,使用在jupyter notebook中的截图表示运行结果。
各种软件版本:
操作系统:Windows10
Anaconda :5.2
python : 3.6
jieba : 0.39
gensim : 3.7.2
scikit_learn : 0.19
1.加载数据
1.1 下载数据
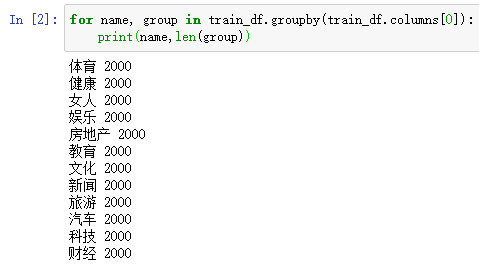
训练集共有24000条样本,12个分类,每个分类2000条样本。
测试集共有12000条样本,12个分类,每个分类1000条样本。
在桌面新建文件夹命名为基于word2vec的文本分类
数据集压缩文件data.zip,下载链接: https://pan.baidu.com/s/1PY3u-WtfBdZQ8FsKgWo_KA 密码: hq5v
下载完成后,将压缩文件data.zip放到桌面的文件夹基于word2vec的文本分类中,并将其解压到当前文件夹,如下图所示:

1.2 打开jupyter
在文件夹基于word2vec的文本分类中运行cmd,即在Windows资源管理器的路径处输入cmd,按Enter键运行,如下图所示:
在cmd运行命令
jupyter notebook,如下图所示:
cmd运行命令
jupyter notebook后,会自动打开网页,点击如下图所示网页中的按钮:

代码文件重命名为
word2vec_test,重命名按钮位置如下图所示:

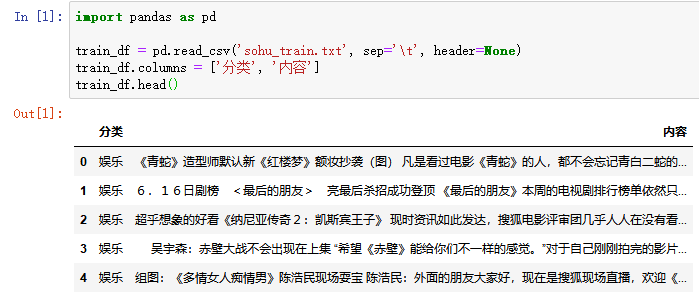
1.3 使用pandas库的read_csv方法加载文本文件
加载训练集到变量train_df中,并打印训练集前5行,代码如下。
read_csv方法中有3个参数,第1个参数是加载文本文件的路径,第2个关键字参数sep是分隔符,第3个关键字参数header是文本文件的第1行是否为字段名。
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.columns = ['分类', '内容']
train_df.head()
上面一段代码的运行结果如下图所示:
查看训练集每个分类的名字以及样本数量,代码如下:
for name, group in train_df.groupby(train_df.columns[0]):
print(name,len(group))
上面一段代码的运行结果如下图所示:
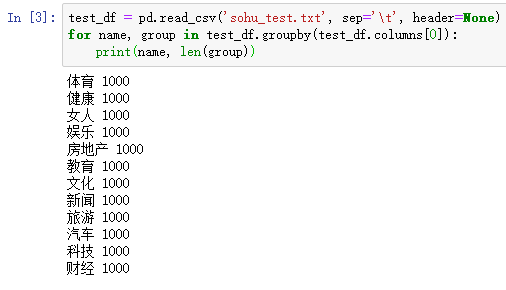
加载测试集并查看每个分类的名字以及样本数量,代码如下:
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
for name, group in test_df.groupby(test_df.columns[0]):
print(name, len(group))
上面一段代码的运行结果如下图所示:
2.分词
2.1 加载停顿词
with open('./stopwords.txt', encoding='utf8') as file:
line_list = file.readlines()
stopword_list = [k.strip() for k in line_list]
stopword_set = set(stopword_list)
print('停顿词列表,即变量stopword_list中共有%d个元素' %len(stopword_list))
print('停顿词集合,即变量stopword_set中共有%d个元素' %len(stopword_set))
上面一段代码的运行结果如下图所示:

2.2 使用jieba库制作分词结果列表cutWords_list
需要安装jieba库,cmd中安装命令:pip install jieba
对训练集的24000条样本循环遍历,使用jieba库的cut方法获得分词列表赋值给变量cutWords。
判断分词是否为停顿词,如果不为停顿词,则添加进变量cutWords中。
代码如下:
import jieba
import time
cutWords_list = []
startTime = time.time()
content_series = train_df['内容']
for i in range(len(content_series)):
content = content_series.iloc[i]
cutWords = [k for k in jieba.cut(content, True) if k not in stopword_set]
if (i+1) % 3000 == 0:
usedTime = time.time() - startTime
print('前%d篇文章分词共花费%.2f秒' %(i+1, usedTime))
cutWords_list.append(cutWords)
上面一段代码的运行结果如下:
前3000篇文章分词共花费12.34秒
前6000篇文章分词共花费29.44秒
前9000篇文章分词共花费35.39秒
前12000篇文章分词共花费43.45秒
前15000篇文章分词共花费49.67秒
前18000篇文章分词共花费56.70秒
前21000篇文章分词共花费69.91秒
前24000篇文章分词共花费75.45秒
2.3 保存分词结果列表cutWords_list到文本文件
从上面的运行结果可以看出,对24000篇文章进行分词共使用75秒,即1分15秒。
上面的运行结果为i7-8700k的cpu环境,一般cpu应该速度只有其一半。
在文件夹基于word2vec的文本分类中新建文件夹saved_variable
将分词结果保存为文本文件cutWords_list.txt,代码如下:
txtFilePath = 'saved_variable/cutWords_list.txt'
with open(txtFilePath, 'w', encoding='utf8') as file:
for cutWords in cutWords_list:
file.write(' '.join(cutWords))
file.write('\n')
2.4 从文本文件加载分词结果列表cutWords_list
这种保存中间结果的做法,可以使下次运行时跳过2.2节。
直接加载文本文件并赋值给变量cutWords_list,能够减少运行2.2节时花费的时间。
载入分词文本文件cutWords_list.txt的代码如下:
txtFilePath = 'saved_variable/cutWords_list.txt'
with open(txtFilePath, 'r', encoding='utf8') as file:
cutWords_list = [k.split(' ') for k in file.readlines()]
3.word2vec模型
3.1 word2vec模型实例化对象
完成此步骤需要先安装gensim库,安装命令:pip install gensim
调用gensim.models库中的Word2Vec类实例化模型对象,代码如下:
from gensim.models import Word2Vec
startTime = time.time()
word2vec_model = Word2Vec(cutWords_list, size=200, iter=10, min_count=20)
usedTime = time.time() - startTime
print('形成word2vec模型共花费%.2f秒' %usedTime)
上面一段代码的运行结果如下:
形成word2vec模型共花费176.25秒
3.2 通过word2vec对象的most_similar方法获取词义相近的词
调用模型对象的方法时,一直提示警告信息,避免出现烦人的警告信息,代码如下:
import warnings
warnings.filterwarnings('ignore')
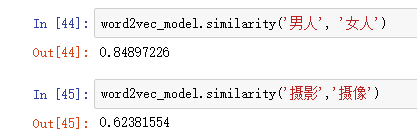
调用Word2Vec模型对象的wv.most_similar方法查看与摄影含义最相近的词。
wv.most_similar方法有2个参数,第1个参数是要搜索的词,第2个关键字参数topn数据类型为正整数,是指需要列出多少个最相关的词汇,默认为10,即列出10个最相关的词汇。
wv.most_similar方法返回值的数据类型为列表,列表中的每个元素的数据类型为元组,元组有2个元素,第1个元素为相关词汇,第2个元素为相关程度,数据类型为浮点型。
word2vec_model.wv.most_similar('摄影')
上面一段代码的运行结果,如下图所示:

wv.most_similar方法使用positive和negative这2个关键字参数的简单示例。
查看女人+先生-男人的结果,代码如下:
word2vec_model.most_similar(positive=['女人', '先生'], negative=['男人'], topn=1)
上面一段代码的运行结果,如下图所示:

查看两个词的相关性,如下图所示:
3.3 使用pickle库保存 word2vec模型
import pickle
pickleFilePath = 'saved_variable/word2vec_model.pickle'
with open(pickleFilePath, 'wb') as file:
pickle.dump(word2vec_model, file)
3.4 使用pickle库加载word2vec模型
import pickle
pickleFilePath = 'saved_variable/word2vec_model.pickle'
with open(pickleFilePath, 'rb') as file:
word2vec_model = pickle.load(file)
4.特征工程
4.1 每篇文章的内容表示成向量
对于每一篇文章,获取文章的每一个分词在word2vec模型的相关性向量。
然后把一篇文章的所有分词在word2vec模型中的相关性向量求和取平均数,即此篇文章在word2vec模型中的相关性向量。
实例化Word2Vec对象时,关键字参数size定义为200,则相关性矩阵都为200维。
定义getVector函数获取每个文章的词向量,传入2个参数,第1个参数是文章分词的结果,第2个参数是word2vec模型对象。
import numpy as np
def get_contentVector(cutWords, word2vec_model):
vector_list = [word2vec_model.wv[k] for k in cutWords if k in word2vec_model]
contentVector = np.array(vector_list).mean(axis=0)
return contentVector
变量vector_list是通过列表推导式得出单篇文章所有分词的词向量,通过np.array方法转成ndarray对象再对每一列求平均值。
代码经过作者实验,使用numpy库计算速度最快,读者如果发现运行更快的代码写法可以留言。
每当完成3000篇文章词向量转换的时候,打印花费时间。
最终将24000篇文章的词向量赋值给变量X,即X为特征矩阵。
import time
startTime = time.time()
contentVector_list = []
for i in range(len(cutWords_list)):
cutWords = cutWords_list[i]
if (i+1) % 3000 == 0:
usedTime = time.time() - startTime
print('前%d篇文章内容表示成向量共花费%.2f秒' %(i+1, usedTime))
contentVector_list.append(get_contentVector(cutWords, word2vec_model))
X = np.array(contentVector_list)
上面一段代码的运行结果如下:
前3000篇文章内容表示成向量共花费21.11秒
前6000篇文章内容表示成向量共花费53.62秒
前9000篇文章内容表示成向量共花费64.50秒
前12000篇文章内容表示成向量共花费79.25秒
前15000篇文章内容表示成向量共花费90.29秒
前18000篇文章内容表示成向量共花费102.94秒
前21000篇文章内容表示成向量共花费127.81秒
前24000篇文章内容表示成向量共花费136.92秒
4.2 使用ndarray对象的dump方法保存文章向量化结果X
因为形成特征矩阵的花费时间较长,为了避免以后重复花费时间,把特征矩阵保存为文件。
使用ndarray对象的dump方法,需要1个参数,数据类型为字符串,为保存文件的文件名,代码如下:
txtFilePath = 'saved_variable/X.txt'
X.dump(txtFilePath)
4.3 使用numpy库的load方法加载文章向量化结果
加载此文件中的内容赋值给变量X,代码如下:
import numpy as np
txtFilePath = 'saved_variable/X.txt'
X = np.load(txtFilePath)
5.模型训练
5.1 标签编码
调用sklearn.preprocessing库的LabelEncoder类实例化对象赋值给变量labelEncoder。
调用变量labelEncoder的fit_transform方法对新闻分类做标签编码。
from sklearn.preprocessing import LabelEncoder
labelEncoder = LabelEncoder()
y = labelEncoder.fit_transform(train_df['分类'])
5.2 检查特征矩阵和预测目标值
print(X.shape, y.shape)
上面一段代码的运行结果如下:
(24000, 100), (24000, )
5.3 逻辑回归模型
调用sklearn.linear_model库的LogisticRegression方法实例化模型对象。
调用sklearn.model_selection库的train_test_split方法划分训练集和测试集。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)
logisticRegression_model = LogisticRegression()
logisticRegression_model.fit(train_X, train_y)
logisticRegression_model.score(test_X, test_y)
上面一段代码的运行结果如下:
0.8033333333333333
5.4 使用pickle库保存逻辑回归模型
调用pickle库中的dump方法保存模型为pickle文件。
import pickle
pickleFilePath = 'saved_variable/logisticRegression_model.pickle'
with open(pickleFilePath, 'wb') as file:
pickle.dump(logisticRegression_model, file)
5.5 使用pickle库加载逻辑回归模型
调用pickle库中的dump方法加载模型。
import pickle
pickleFilePath = 'saved_variable/logisticRegression_model.pickle'
with open(pickleFilePath, 'rb') as file:
logisticRegression_model = pickle.load(file)
6.模型评估
6.1 交叉验证
交叉验证的结果更具有说服力。
调用sklearn.model_selection库的ShuffleSplit方法实例化交叉验证对象。
调用sklearn.model_selection库的cross_val_score方法获得交叉验证每一次的得分。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
cv_split = ShuffleSplit(n_splits=5, train_size=0.7, test_size=0.2)
score_ndarray = cross_val_score(LogisticRegression(), X, y, cv=cv_split)
print(score_ndarray)
print(score_ndarray.mean())
上面一段代码的运行结果如下:
[0.80041667 0.79833333 0.79645833 0.79041667 0.7975 ]
0.796625
6.2 混淆矩阵
6.2.1 获取训练集文本内容向量化后的特征矩阵
import pickle
import numpy as np
import pandas as pd
import jieba
import time
pickleFilePath = 'saved_variable/word2vec_model.pickle'
with open(pickleFilePath, 'rb') as file:
word2vec_model = pickle.load(file)
def get_featureMatrix(content_series):
vector_list = []
for content in content_series:
vector = get_contentVector(jieba.cut(content, True), word2vec_model)
vector_list.append(vector)
featureMatrix = np.array(vector_list)
return featureMatrix
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_df.columns = ['分类', '内容']
startTime = time.time()
featureMatrix = getVectorMatrix(test_df['内容'])
usedTime = time.time() - startTime
print('测试集文本内容向量化花费时间%.2f秒' %usedTime)
上面一段代码的运行结果如下:
测试集文本内容向量化花费时间119.32秒
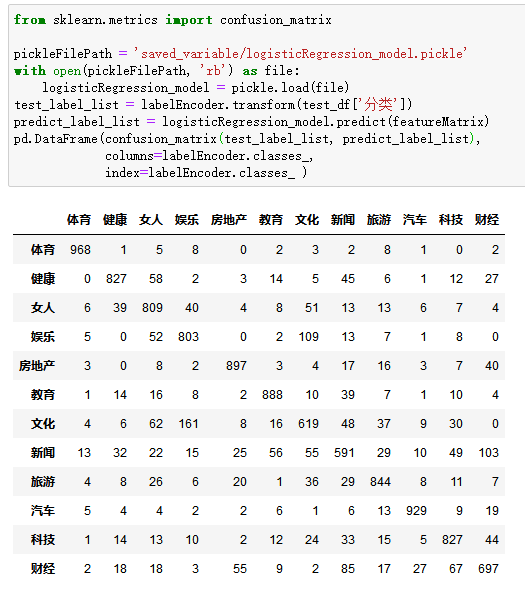
6.2.2 绘制混淆矩阵
from sklearn.metrics import confusion_matrix
pickleFilePath = 'saved_variable/logisticRegression_model.pickle'
with open(pickleFilePath, 'rb') as file:
logisticRegression_model = pickle.load(file)
test_label_list = labelEncoder.transform(test_df['分类'])
predict_label_list = logisticRegression_model.predict(featureMatrix)
pd.DataFrame(confusion_matrix(test_label_list, predict_label_list),
columns=labelEncoder.classes_,
index=labelEncoder.classes_ )
上面一段代码的运行结果如下:
6.3 报告表
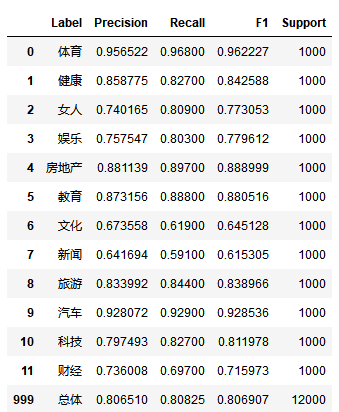
from sklearn.metrics import precision_recall_fscore_support
def eval_model(test_label_list, predict_label_list, className_list):
# 计算每个分类的Precision, Recall, f1, support
p, r, f1, s = precision_recall_fscore_support(test_label_list, predict_label_list)
# 计算总体的平均Precision, Recall, f1, support
total_p = np.average(p, weights=s)
total_r = np.average(r, weights=s)
total_f1 = np.average(f1, weights=s)
total_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': className_list,
u'Precision': p,
u'Recall': r,
u'F1': f1,
u'Support': s
})
res2 = pd.DataFrame({
u'Label': ['总体'],
u'Precision': [total_p],
u'Recall': [total_r],
u'F1': [total_f1],
u'Support': [total_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[['Label', 'Precision', 'Recall', 'F1', 'Support']]
eval_model(test_label_list, predict_label_list, labelEncoder.classes_)\
上面一段代码的运行结果如下:
7.结论
1.word2vec模型应用的第1个小型项目,训练集数据共有24000条,测试集数据共有12000条。
经过交叉验证,模型平均得分为0.80左右。
2.测试集的验证效果中,体育、教育、健康、文化、旅游、汽车、娱乐这7个分类得分较高,即容易被正确分类。
女人、娱乐、新闻、科技、财经这5个分类得分较低,即难以被正确分类。
3.学习如何提高文本分类的准确率,请查看我的另外一篇文章
《基于jieba、TfidfVectorizer、LogisticRegression的搜狐新闻文本分类》。
文章链接:https://www.jianshu.com/p/ec053e920a3b
4.本文作者在2018年8月30日写作此文,2019年4月18日花费4个小时完善文章,文章内容保证完全正确。