Android 崩溃优化之Java篇(二)
声明:本篇文章已授权微信公众号 YYGeeker 独家发布。
博主原创文章,转载请注明出处:小嵩的博客
一、前言
由于Android系统的碎片化、版本差异、厂商定制ROM等诸多原因,我们经常会遇到各种奇奇怪怪的崩溃,治理Android App的崩溃可谓是一个大老难题。对于一个大型应用来说,有时候可能一个很小的问题疏忽掉了,往往就可能影响成千上万的用户,最后对公司造成难以挽回的损失;也可能由于一个疏忽,导致整个团队都在加班加点花上数天时间去排查和解决问题。崩溃率是衡量一个应用质量的重要指标,作为一名开发者我们必须重视并尽力降低crash率。
本文从工作实践中总结了一些经验,希望能够为开发者个人或者其他团队提供一些解决方案的灵感和启发。权作抛砖引玉,有其他好的建议或者经验的可以交流讨论。本文讲述的是Java层崩溃,因此这里就再不提及Native相关的内容,Native层的相关知识点及经验分享会在后续文章单独讲述。
二、崩溃类型
Java 层
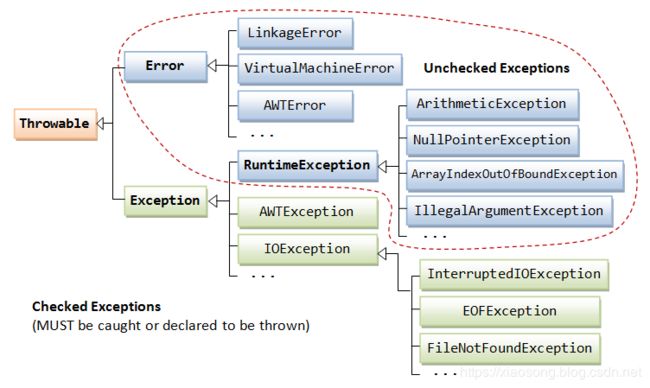
从上图可以看出,它们都是从 Throwable 继承而来,Throwable 下一层分为两个子类:Error 和 Exception。
2.1 关于 Error 和 Exception
其中 Error 类描述了 Java 运行时系统的内部错误或设备资源耗尽的错误。这种错误一般没有别的解决办法,它用于报告给开发者程序无法恢复的异常情况。对于所有 Error 类型以及其子类都不要求程序进行处理,常见如内存溢出 StackOverflowError等。
而 Exception 类则是指程序有可能恢复的异常情况,Exception 包含了运行时异常(Runtime Exception)和受检查的异常(Checked Exception)
2.2 关于 Checked 和 Unchecked异常
上面一小节提到了 Checked 异常 及 Unchecked 异常,那么这两种异常的区别是什么呢? 其中,派生于 Error 或者 RuntimeException 的异常称为 Unchecked 异常,所有其他的 Exception 称为 Checked 异常。在上图所示中,浅蓝色方框所标注的为 Unchecked 异常。
那又为什么需要这样区分它们呢?因为 Java compiler (编译器) 强制要求所有的 Exception 要么被 catch,要么被 throw 对其进行处理,否则编译会不通过,除非这是一个 RuntimeExeption (e instanceof RuntimeException)。也就是说,通常的 Exception 一定要被处理,也即我们所说的 Checked Exception,而 RuntimeException / Error ,编译器是不强制要求处理的,所以被称为Unchecked exception。
2.3 关于 RuntimeException
Oracle 官网解释:
RuntimeException and its subclasses are unchecked exceptions. Unchecked exceptions do not need to be declared in a method or constructor’s throws clause if they can be thrown by the execution of the method or constructor and propagate outside the method or constructor boundary.
RuntimeException (运行时异常),它属于 Unchecked 异常。如果出现RuntimeException,那么一定是程序员的代码问题,编译器并不会检查 Unchecked 异常。在开发过程中,我们遇到的crash 绝大多数都属于 RuntimeException。
2.4 常见 Java Exception & Error
从上面几点的介绍及描述,到这儿我们对Java 的异常类型已经有了一定认知,下面我们再挑几个最常见崩溃异常稍微讲一下:
2.4.1 NullPointerException
空指针异常崩溃(简称NPE)一般是崩溃占比较高、平时开发过程中频繁遇到的一种崩溃类型。总所周知,Java是粹面向对象的编程语言,一切皆为对象;在为空的对象中调用方法就会出现NullPointerException。
2.4.2 IndexOutOfBoundsException
用非法索引访问数组时抛出的异常,如果索引为负,或者大于等于数组大小,则该索引为非法索引。通常情况下,我们操作数组都需要对它的size做安全校验,在单线程操作数据的时候判断index 是否越界。
而在多线程下,IndexOutOfBoundsException 则会变得更加频繁和复杂。此时我们单纯对数组做一层index校验的代码已经变得不可靠,需要考虑多线程同时操作数据导致的问题。因此在多线程操作数据时,我们需要格外注意数据的可见性,可通过加锁/使用同步队列等方式,保持数据的同步以避免出现索引越界。
2.4.3 OutOfMemoryError
由于移动设备的性能有限性,内存溢出异常(简称OOM) 是Android中最常见 Error类型。在Android中导致OutOfMemoryError异常的常见原因主要有以下几种:
- 内存中加载的数据量过于庞大,如大图内存占用过大;
- 集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
- 代码中存在死循环或循环产生过多重复的对象实体;
- 启动参数内存值设定的过小。
三、崩溃分析
作为程序员,排查定位crash比较考验我们的内功和耐心,有时可能因为一个很细节的点造成严重的crash事故,因此我们需要善于抓住各种蛛丝马迹来找出问题的根源。对于Java崩溃,我们可以从以下这些方面去侦察问题:
3.1 崩溃堆栈及异常类型
崩溃堆栈和异常类型是最直接也是最常见的一种方式,通过堆栈我们可以看到具体crash 的业务代码,以及其崩溃原因。这种是属于比较常见的,通常按照堆栈的代码及崩溃类型提示去修复即可。
3.2 设备信息
除了上述比较简单的崩溃分析,在遇到一些业务堆栈不明/系统疑难杂症等情况,我们就需要分析包括设备ID、系统版本、模拟器、厂商、网络环境等特征。
设备ID: 通过分析崩溃的设备id是否相同,可以用于判断是否单设备重复崩溃上报异常;或者使用外挂出现异常自动重启等情况;
后台运行:比如某些vivo 设备限制了后台运行时长5分钟,如果息屏过久导致生命周期被回收,app处理不当也可能导致一些 crash;
网络环境:通过分析网络环境,也可以帮助我们分析该用户是否由于网络状态不良导致某些业务异常。
系统版本:通过分析系统版本/厂商特征,可以帮助我们去定位该问题是否由于系统/厂商定制Rom导致的某些bug。
举个例子,在某个版本中发现了如下崩溃log:
java.lang.RuntimeException: Unable to start activity ComponentInfo{com.xxx.Activity}: java.lang.IllegalStateException: Only fullscreen opaque activities can request orientation
at android.app.ActivityThread.performLaunchActivity(ActivityThread.java:2955)
at android.app.ActivityThread.handleLaunchActivity(ActivityThread.java:3030)
at android.app.ActivityThread.-wrap11(Unknown Source:0)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:1696)
at android.os.Handler.dispatchMessage(Handler.java:105)
at android.os.Looper.loop(Looper.java:164)
at android.app.ActivityThread.main(ActivityThread.java:6938)
at java.lang.reflect.Method.invoke(Native Method)
at com.android.internal.os.Zygote$MethodAndArgsCaller.run(Zygote.java:327)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1374)
Caused by: java.lang.IllegalStateException: Only fullscreen opaque activities can request orientation
...
通过日志我们只知道是Activity启动崩溃了,log显示和横竖屏有关但具体原因有点不太明确,我们通过分析Crash 的版本发现,该问题都是 Android 8.0 版本出现的。那么我们可以结合log和版本信息去推测,通过源码及Google发现,这是由于Android 8.0 版本在透明主题的情况下,AndroidMenifes.xml 配置强制设置 了 Activity 竖屏导致 crash 的系统 bug。
3.3 用户操作路径
对于某些偶现崩溃,我们可能难以去复现问题,那么用户的交互操作路径此时就变得十分必要了。通过记录页面跳转堆栈、点击交互等关键日志信息。可以帮助我们还原崩溃现场,从而找到问题根源。
3.4 崩溃时刻前后
崩溃发生附近的时间段也是我们需要分析的一个点,我们可以从崩溃前业务日志信息、app运行的线程数、是否在后台运行等去分析问题。比如华为、魅族等厂商限制了系统创建的最大线程数,这种属于厂商Rom系统的限制,通过排查日志我们知道在崩溃前创建了太多线程,这种情况我们需要合理使用线程池来避免。另外对于一些内存不足,或者触摸事件未响应的问题,我们可以分析崩溃附近时间点,来分析是否由于代码逻辑异常/用户操作太频繁引起的崩溃。
3.5 主动捞取用户日志
对于某些崩溃,可能由于种种情况导致用户崩溃日志没有上报。这将给我们定位崩溃根源带来很大的困难。对于这种情况,开发一个主动上报日志的功能就变得比较重要了。在这种情形下,通过主动捞取用户日志,可以让我们能够及时获取到宝贵的崩溃信息,提高修复bug的效率并降低时间成本,同时也能尽快帮助用户修复问题,降低事故影响面积。
四、关于预防
说到预防,我们最终的目的肯定是为了降低Crash率,以提高用户留存及使用体验。从技术角度来说,我们可以从以下几个方面来降低我们应用的crash率:
4.1 架构设计
工欲善其事必先利其器,一个架构的优劣对于应用的开发效率及代码质量有着非常大的影响。对于Android项目而言,我们可以通过架构选型及设计,在源头降低crash隐患。为此我们需要考量以下几个方向(图片引自《软件架构设计》):
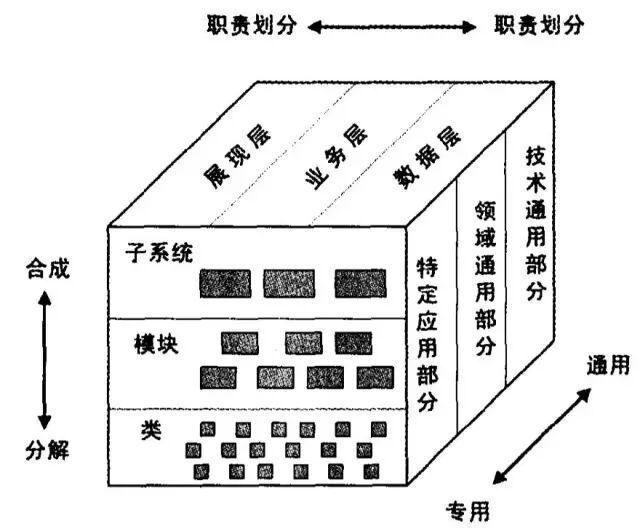
1. 模块划分解耦
由于IT互联网行业的业务迭代,公司内部的调整,员工跳槽等诸多原因,考虑到人事变动的风险比较高,开发团队之间需要交叉熟悉各自之间的业务。因此将模块进行解耦拆分,项目模块化/组件化/插件化是大势所趋,这样可以让业务的职责更加清晰,独立性更强,也更易于维护和交接。
2. 工具统一封装
除了业务模块划分,对于基础库我们也需要格外注意。这里为什么首先要说到工具类呢? 因为在过往开发经验中,我们不止一次遇到过因为工具类本身设计的缺陷/局限性导致的crash, 也有通过统一封装的工具类,大大降低某些业务场景的crash率。基础类库功能健壮性对于应用crash有很大影响。举两个简单的例子:
- MD5 Util
基础库里面提供的MD5校验工具类,由于代码逻辑不够严谨,在多线程并发的情况下messagedigest会有问题,导致会出现crash。
- Drawable Util
由于一些机型兼容问题,我们在获取drawable 资源的时候,可能会出现获取失败或者异常的情况,如果每个业务都自己去处理异常,就会存在两个问题: 一方面会出现很多重复性的代码;另一方面每个人写的代码逻辑不一致,可能会存在某些代码考虑不全,遗漏一些异常情况的处理。
因此,我们有必要统一封装,维护基础类库。同时也需要格外注意工具类库的健壮性。
3. 关于第三方库
除了基础库,对于引入的一些第三方库,我们也需要谨慎对待,充分调研后对风险进行评估把控。因为第三方库可能存在某些bug或者使用场景的局限性,我们比较难发现。另外出现问题后fix bug 也会比较被动,若引入源码自己修改,后期代码维护也是一件困难的事情。这里建议在引入第三方库之前做好充分的调研,阅读Issue区的已知/未解决问题。同时,我们也应该善于建设自己的基础类库,提升代码框架的健壮性和在公司内多部门之间的可复用性,提高开发效率,降低重复造轮子的成本。
4. 尝试使用 Kotlin。
Kotlin的代码比Java更加简洁,实用,安全,扩展性高。特别是对于空指针异常的预防方面,Kotlin是空指针安全的。JetBrains公司做了一件很聪明的事情,它们将运行时才能空指针的检测提前到了编译时,主要方式是增加了Any?这种可为空的类型,使用Kotlin之后,我们程序的空指针会得到明显的改善。使用Kotlin 去开发从一定程度上可以降低 NPE 异常的频率。
4.2 合理 try catch 预防
对于某些异常,我们可能会考虑try catch 来避免crash,特别是对于碎片化的Android市场,机型兼容问题比较严重,有时候难免
案例 :插件化项目中,Android8.0系统 WebView 文本复制粘贴框崩溃。
崩溃日志:
java.lang.IndexOutOfBoundsException
at android.content.res.StringBlock.nativeGetString(Native Method)
at android.content.res.StringBlock.get(StringBlock.java:[num])
at android.content.res.AssetManager.getPooledStringForCookie(AssetManager.java:[num])
at android.content.res.TypedArray.loadStringValueAt(TypedArray.java:[num])
···
在线上发现该 crash 的时候,我们同事通过自定义 Webview 重写了系统方法,对方法加了 Throwable 捕获异常。自测后确实是解决了该场景下的问题,但添加预防发布补丁版本后,却又出现了另一个 native 崩溃,崩溃详情如下:
android.content.res.StringBlock.nativeGetString(Native Method)
at android.content.res.StringBlock.get(StringBlock.java:82)
at android.content.res.AssetManager.getPooledStringForCookie(AssetManager.java:656)
at android.content.res.TypedArray.loadStringValueAt(TypedArray.java:1331)
at android.content.res.TypedArray.getText(TypedArray.java:184)
at android.view.MenuInflater$MenuState.readItem(MenuInflater.java:400)
at android.view.MenuInflater.parseMenu(MenuInflater.java:164)
at android.view.MenuInflater.inflate(MenuInflater.java:114)
···
对于这种系统异常,确实可以通过继承系统类并重写类的方法加 try catch 来预防。但由于同事写的代码 catch 掉了 Throwable,导致原先系统源码内部自己捕获的异常逻辑没有被没有执行,直接 return 掉使得内部源码代码逻辑状态出现了异常,在源码内部调用native的时候出现了崩溃。后面通过分析,将此处的catch Throwable 改成只 catch IndexOutOfBoundsException这个异常,才根治了问题。
因此,对于某些系统的 bug 我们不太建议直接 cry catch 捕获 Throwable/Exception。应尽量改成只捕获造成崩溃的异常,其他异常还是让系统内部自行处理去执行。另外,假若有一些可以通过反射/hook的方式可以修复问题,我们也可以衡量利弊之后去尝试这些方式。
4.3 Lint 扫描检测
Android Studio 提供一个名为 Lint 的代码扫描工具,可以检测到代码是否包含潜在Error,以及在正确性、安全性、性能、易用性、便利性和国际化方面是否需要优化改进。具体使用方式就不过多阐述了,有兴趣可以自行查找资料了解相关知识点。
4.4 开源工具检测
常见的有 LeakCanary、BolckCanary 等工具,通过工具检测可以让我们在开发过程中将问题尽早暴露出来,防患于未然。另外,也可以通过 Crash 上报系统及时检测到开发期间发生的bug。另外,在测试阶段,压测/自动化测试工具等也可以帮助我们发现一些隐藏的问题。
4.5 代码 review
为了提高代码质量,一般来说可以要求做CodeReview。通过CodeReview我们可以尽早发现代码存在的缺陷或局限性,降低线上事故风险。另外,代码Review 不仅是在 Review Code,同时也可以通过它分享和学习知识和经验。总体来说,CodeReview对于降低crash 有一定帮助,但我们需要注重效率和方式,降低时间成本。
4.6 崩溃改动评审
小王是某个互联网公司的Android工程师,经过两周的开发,他们项目的某个重要活动版本终于上线了,但活动入口暂未开放,计划上线三天后才打开。上线第一天统计系统的crash率情况,小王所负责的某个业务有一类 crash 占比Top10之外。分析crash 信息后,小王自认为问题不大,稍微改下代码即可解决。结果改完代码发布补丁之后过了两天,活动入口开放了。两天前小王所改动的代码引起了新的问题,此时由于入口开放出来,导致业务bug场景被触发。Crash 占比瞬间上升到了Top1,影响到了大批线上用户…
作为工作中,类似上述小王这样,有时fix崩溃问题的改动者,可能并未根治掉问题。因此对于一些比较重要的业务,除了开发过程中进行 code review 之外。若发生了线上Crash, 我们有必要加强对代码改动的评审,以降低改动风险。
4.7 统计归类及分享
- 对新版本首报bug一定要引起足够重视。
- 对于历史版本已关闭却在新版本重新打开的Bug,要引起足够重视。
- 对一些常遇见的崩溃进行总结,并输出整理文档并分享给Team/公司成员。
总结
本文介绍了Android应用中的一些常见Java崩溃,以及分析崩溃的方法和解决思路。当然,治理crash 始终都是一个斗智斗勇的艰苦过程,有时候可能是一些细小的疏忽。可能就会酿成严重的事故带来负面影响。因此,我们在分析解决问题时,需要抱着严谨细心的态度。对于一些疑难杂症,我们需要具备敏锐的眼光和刨根问底的耐心。
此外,具体问题我们需要具体分析,有时候不能光用惯性思维去看代码逻辑,需要从实际出发。实践是检验真理的唯一标准,有时候问题往往就是被惯性思维所迷惑和掩盖掉了。遇到问题我们需要善于跟踪日志及程序真正运行的流程,利用好debug。同时,在平时我们也需要尝试从大局观触发,站在架构角度上面去看待和避免问题。量变慢慢会积累质变,治理crash 之路相信也会是我们的成长之路。