最终结构图:

RabbitMQ镜像集群简介
RabbitMQ镜像集群是通过在RabbitMQ服务器配置相应的规则,把交换器、队列的数据进行Node之间Copy,对内网流量要求较高。在生产者扔消息时,会在所有Node之间同步完毕之后才会响应扔消息成功。
RabbitMQ镜像集群的安装
- 环境声明
三台CentOS 7.4
/etc/hosts配置分别为:192.168.1.219 rabbit1
192.168.1.220 rabbit2
192.168.1.221 rabbit3
- 三台机器全部安装Erlang,RabbitMQ是基于
饿了开发
使用Erlang 19.0.4
// 下载Erlang
[root@rabbit1 tmp] wget http://www.rabbitmq.com/releases/erlang/erlang-19.0.4-1.el6.x86_64.rpm
// 安装
[root@rabbit1 tmp] rpm -ivh erlang-19.0.4-1.el6.x86_64.rpm
- 三台机器全部安装RabbitMQ
使用RabbitMQ 3.6.12
[root@rabbit1 tmp] wget https://dl.bintray.com/rabbitmq/rabbitmq-server-rpm/rabbitmq-server-3.6.12-1.el6.noarch.rpm
[root@rabbit1 tmp] rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
[root@rabbit1 tmp] rpm -ivh rabbitmq-server-3.6.12-1.el6.noarch.rpm
提示错误:
错误:依赖检测失败:
socat 被 rabbitmq-server-3.6.12-1.el6.noarch 需要
解决错误:
// 建议更换为阿里云 yum 源
// 同步服务器的缓存
[root@rabbit1 tmp] yum -y makecache
// 安装所需组件
[root@rabbit1 tmp] yum -y install socat
// 继续安装
[root@rabbit1 tmp] rpm -ivh rabbitmq-server-3.6.12-1.el6.noarch.rpm
准备中... ################################# [100%]
正在升级/安装...
1:rabbitmq-server-3.6.12-1.el6 ################################# [100%]
- 启动服务查看状态
[root@rabbit1 tmp] systemctl start rabbitmq-server.service
[root@rabbit1 tmp] systemctl status rabbitmq-server.service
- 安装Web管理插件
// 查看插件列表
[root@rabbit1 tmp] rabbitmq-plugins list
// 开启Web管理插件
[root@rabbit1 tmp] rabbitmq-plugins enable rabbitmq_management
- 单台安装完成
以上步骤,在三台机器上操作相同
普通集群配置
1.说明
Rabbitmq的集群是依附于Erlang的集群来工作的,所以必须先构建起Erlang的集群镜像。Erlang的集群中各节点是经由过程一个magic cookie来实现的,这个cookie存放在 $home/.erlang.cookie 中,我的是用rpm安装的,所以.erlang.cookie就放在/var/lib/rabbitmq中
2.复制Cookie
.erlang.cookie是Erlang实现分布式的必要文件,Erlang分布式的每个节点上要保持相同的.erlang.cookie文件,同时保证文件的权限是400,不然节点之间就无法通信。打开文件然后需要先把其中的一台服务器的.erlang.cookie中的内容复制到别的机器上,最好是复制内容,因为文件权限不对的话会出现问题,在最后退出保存的时候使用wq!,用!来进行强制保存即可。也可是直接使用scp传过去,记得文件权限和用户属主属组,如:scp .erlang.cookie [email protected]:/usr/local/tmp
3..erlang.cookie复制完成后,逐个重启节点服务:
[root@rabbit1 tmp] systemctl restart rabbitmq-server.service
[root@rabbit1 tmp] systemctl status rabbitmq-server.service
4.添加到集群
将rabbit@rabbit1作为集群主节点,在节点rabbit2和节点rabbit3上面分别执行如下命令,以加入集群中
[root@rabbit1 tmp] rabbitmqctl stop_app
[root@rabbit1 tmp] rabbitmqctl reset
[root@rabbit1 tmp] rabbitmqctl join_cluster rabbit@rabbit1
提示错误:
......
rabbit@rabbit2:
* connected to epmd (port 4369) on bbbbdddd
* epmd reports node 'rabbit' running on port 25672
* TCP connection succeeded but Erlang distribution failed
* Hostname mismatch: node "rabbit@rabbit2" believes its host is different. Please ensure that hostnames resolve the same way locally and on "rabbit@rabbit2"
......
解决错误:
[root@rabbit1 tmp] vim /etc/rabbitmq/rabbitmq-env.conf
// rabbit1内容:
NODENAME=rabbit@rabbit1
// rabbit2内容:
NODENAME=rabbit@rabbit2
// rabbit3内容:
NODENAME=rabbit@rabbit3
kill掉RabbitMQ所有进程
[root@rabbit1 tmp] ps -aux | grep mq
root 7972 0.0 0.0 112660 976 pts/1 S+ 16:19 0:00 grep --color=auto mq
rabbitmq 29798 0.0 0.0 11576 336 ? S 15:28 0:00 /usr/lib64/erlang/erts-8.0.3/bin/epmd -daemon
root 29834 0.0 0.0 115520 1220 ? S 15:28 0:00 /bin/sh /etc/rc.d/init.d/rabbitmq-server start
root 29841 0.0 0.0 115252 1468 ? S 15:28 0:00 /bin/bash -c ulimit -S -c 0 >/dev/null 2>&1 ; /usr/sbin/rabbitmq-server
root 29843 0.0 0.0 115252 1536 ? S 15:28 0:00 /bin/sh /usr/sbin/rabbitmq-server
root 29862 0.0 0.0 189740 2432 ? S 15:28 0:00 su rabbitmq -s /bin/sh -c /usr/lib/rabbitmq/bin/rabbitmq-server
rabbitmq 29864 0.0 0.0 113132 1568 ? Ss 15:28 0:00 /bin/sh /usr/lib/rabbitmq/bin/rabbitmq-server
rabbitmq 30111 0.2 0.5 10355084 86156 ? Sl 15:28 0:06 /usr/lib64/erlang/erts-8.0.3/bin/beam.smp -W w -A 256 -P 1048576 -t 5000000 -stbt db -zdbbl 128000 -K true -B i -- -root /usr/lib64/erlang -progname erl -- -home /var/lib/rabbitmq -- -pa /usr/lib/rabbitmq/lib/rabbitmq_server-3.6.12/ebin -noshell -noinput -s rabbit boot -sname rabbit@host9 -boot start_sasl -kernel inet_default_connect_options [{nodelay,true}] -sasl errlog_type error -sasl sasl_error_logger false -rabbit error_logger {file,"/var/log/rabbitmq/[email protected]"} -rabbit sasl_error_logger {file,"/var/log/rabbitmq/[email protected]"} -rabbit enabled_plugins_file "/etc/rabbitmq/enabled_plugins" -rabbit plugins_dir "/usr/lib/rabbitmq/plugins:/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.12/plugins" -rabbit plugins_expand_dir "/var/lib/rabbitmq/mnesia/rabbit@host9-plugins-expand" -os_mon start_cpu_sup false -os_mon start_disksup false -os_mon start_memsup false -mnesia dir "/var/lib/rabbitmq/mnesia/rabbit@host9" -kernel inet_dist_listen_min 25672 -kernel inet_dist_listen_max 25672
rabbitmq 30413 0.0 0.0 4300 528 ? Ss 15:28 0:00 erl_child_setup 1024
rabbitmq 30499 0.0 0.0 11540 444 ? Ss 15:28 0:00 inet_gethost 4
rabbitmq 30500 0.0 0.0 13664 688 ? S 15:28 0:00 inet_gethost 4
[root@rabbit1 tmp] kill 对应的进程号
重新启动RabbitMQ服务加入集群
[root@rabbit1 tmp] systemctl restart rabbitmq-server.service
[root@rabbit1 tmp] systemctl status rabbitmq-server.service
// 在rabbit2和rabbit3加入集群
[root@rabbit1 tmp] rabbitmqctl stop_app
[root@rabbit1 tmp] rabbitmqctl reset
[root@rabbit1 tmp] rabbitmqctl join_cluster rabbit@rabbit1
[root@rabbit1 tmp] rabbitmqctl start_app
5.查看集群状态
[root@rabbit1 tmp] rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit1,rabbit@rabbit3,rabbit@rabbit2]},
{cluster_name,<<"rabbit@host9">>},
{partitions,[]},
{alarms,[{rabbit@rabbit1,[]},{rabbit@rabbit3,[]},{rabbit@rabbit2,[]}]}]
6.添加账号
默认使用
guest账号只能在localhost下登录,所以我们新建一个admin账号并授权
// 新增用户
[root@rabbit1 tmp] rabbitmqctl add_user 用户名 密码
// 授予所有权限
[root@rabbit1 tmp] rabbitmqctl set_permissions -p "/" 用户名 ".*" ".*" ".*"
// 设置用户为管理员
[root@rabbit1 tmp] rabbitmqctl set_user_tags 用户名 administrator
// 查看当前用户列表
[root@rabbit1 tmp] rabbitmqctl list_users
7.普通节点完成,基本操作
访问Web管理页面
http://192.168.1.219:15672
从集群中移除节点
[root@rabbit1 tmp] rabbitmqctl stop_app
Stopping rabbit application on node 'rabbit@rabbit2'
[root@rabbit1 tmp] rabbitmqctl reset
Resetting node 'rabbit@rabbit2'
[root@rabbit1 tmp] rabbitmqctl start_app
Starting node 'rabbit@rabbit2'
改变节点类型
[root@rabbit1 tmp] rabbitmqctl stop_app
[root@rabbit1 tmp] rabbitmqctl join_cluster --ram rabbit@rabbit1
[root@rabbit1 tmp] rabbitmqctl start_app
--ram 指定内存节点类型,--disc指定磁盘节点类型
修改节点类型
[root@rabbit1 tmp] rabbitmqctl stop_app
[root@rabbit1 tmp] rabbitmqctl change_cluster_node_type disc
[root@rabbit1 tmp] rabbitmqctl start_app
集群镜像模式配置
上面配置RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换器、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制,虽然该模式解决一部分节点压力,但队列节点宕机直接导致该队列无法使用,只能等待重启,所以要想在队列节点宕机或故障也能正常使用,就要复制队列内容到集群里的每个节点,需要创建镜像队列。
使用Rabbit镜像功能,需要基于RabbitMQ策略来实现,策略是用来控制和修改群集范围的某个vhost队列行为和Exchange行为。
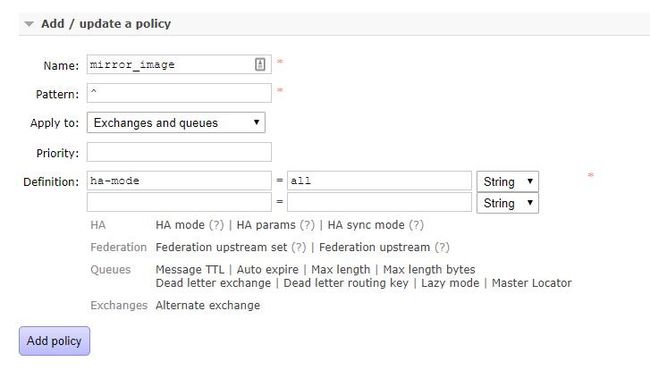
下面我们使用Web端创建一个完整的镜像队列:
- 登录Web管理页面——>Admin——>Policies——>Add / update a policy
此策略会同步所在同一VHost中的交换器和队列数据
- 新增队列查看策略已生效
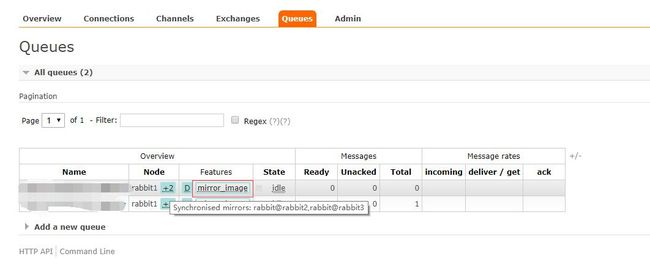
- 镜像集群到此结束
HAproxy负载
在
192.168.1.219和192.168.1.220做负载
- 安装HAproxy
[root@rabbit1 tmp] yum install haproxy
// 编辑配置文件
[root@rabbit1 tmp] vim /etc/haproxy/haproxy.cfg
在最后新增配置信息:
#######################HAproxy监控页面#########################
listen http_front
bind 0.0.0.0:1080 #监听端口
stats refresh 30s #统计页面自动刷新时间
stats uri /haproxy?stats #统计页面url
stats realm Haproxy Manager #统计页面密码框上提示文本
stats auth admin:Guo*0820 #统计页面用户名和密码设置
#stats hide-version #隐藏统计页面上HAProxy的版本信息
#####################我把RabbitMQ的管理界面也放在HAProxy后面了###############################
listen rabbitmq_admin
bind 0.0.0.0:15673
server node1 192.168.1.219:15672
server node2 192.168.1.220:15672
server node3 192.168.1.221:15672
#####################RabbitMQ服务代理###########################################
listen rabbitmq_cluster 0.0.0.0:5673
mode tcp
stats enable
balance roundrobin
option tcpka
option tcplog
timeout client 3h
timeout server 3h
timeout connect 3h
#balance url_param userid
#balance url_param session_id check_post 64
#balance hdr(User-Agent)
#balance hdr(host)
#balance hdr(Host) use_domain_only
#balance rdp-cookie
#balance leastconn
#balance source //ip
server node1 192.168.1.219:5672 check inter 5s rise 2 fall 3 #check inter 2000 是检测心跳频率,rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用
server node2 192.168.1.220:5672 check inter 5s rise 2 fall 3
server node3 192.168.1.221:5672 check inter 5s rise 2 fall 3
- 启动HAproxy负载
[root@rabbit1 tmp] haproxy -f /etc/haproxy/haproxy.cfg
- HAproxy负载完毕
Keepalived安装
利用keepalived做主备,避免单点问题,实现高可用
在192.168.1.219和192.168.1.220做主备,前者主,后者备
- 安装Keepalived
[root@rabbit1 tmp] yum -y install keepalived
- 配置Keepalived生成VIP
[root@rabbit1 tmp] vim /etc/keepalived/keepalived.conf
部分配置信息(只显示使用到的):
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
# vrrp_strict # 注释掉,不然访问不到VIP
vrrp_garp_interval 0
vrrp_gna_interval 0
}
# 检测任务
vrrp_script check_haproxy {
# 检测HAProxy监本
script "/etc/keepalived/script/check_haproxy.sh"
# 每隔两秒检测
interval 2
# 权重
weight 2
}
# 虚拟组
vrrp_instance haproxy {
state MASTER # 此处为`主`,备机是 `BACKUP`
interface enp4s0f0 # 物理网卡,根据情况而定
mcast_src_ip 192.168.1.219 # 当前主机ip
virtual_router_id 51 # 虚拟路由id,同一个组内需要相同
priority 100 # 主机的优先权要比备机高
advert_int 1 # 心跳检查频率,单位:秒
authentication { # 认证,组内的要相同
auth_type PASS
auth_pass 1111
}
# 调用脚本
track_script {
check_haproxy
}
# 虚拟ip,多个换行
virtual_ipaddress {
192.168.1.222
}
}
-
/etc/keepalived/script/check_haproxy.sh内容
#!/bin/bash
LOGFILE="/var/log/keepalived-haproxy-status.log"
date >> $LOGFILE
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
echo "warning: restart haproxy" >> $LOGFILE
haproxy -f /etc/haproxy/haproxy.cfg
sleep 2
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
echo "fail: check_haproxy status" >> $LOGFILE
systemctl stop keepalived
fi
else
echo "success: check_haproxy status" >> $LOGFILE
fi
解释说明:
Keepalived组之间的心跳检查并不能察觉到HAproxy负载是否正常,所以需要使用此脚本。
在Keepalived主机上,开启此脚本检测HAproxy是否正常工作,如正常工作,记录日志。
如进程不存在,则尝试重启HAproxy,两秒后检测,如果还没有则关掉主Keepalived,此时备Keepalived检测到主Keepalive挂掉,接管VIP,继续服务
- 完毕
参考资料:
https://www.cnblogs.com/saneri/p/7798251.html
不对之处,请指出