关键词:神经网络、激活函数 Activiation Function、设置层数和神经元数
两层的神经网络

对于输入x,进行矩阵计算 w1 * x
输入隐藏层:使用激活函数(Activation Function) h = max ( 0, s)
输出层:s = w2 * h 矩阵计算得到最终得分

第9行和第10行是Score Function,第11行是Loss Funciton,
14-17行,则是使用链式法则求解梯度,17行就用到了sigmoid函数的导数 h * (1 - h)
生物神经网络简介
输入:树突:接受信号
计算:轴突释放的化学物质使该神经产生电位差形成电流传递信息
输出:神经末梢传递计算后的信号给其他神经元
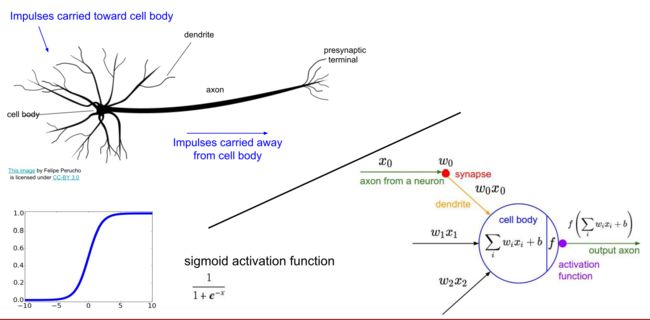
生物神经元的特别之处
有很多不同的类型的神经元
树突可以执行复杂的非线性计算(我们目前算法中的单个神经元执行的都是线性运算)
突触所处理的不是单一的权重,它是一个复杂的非线性动力学系统
我们并不确定大脑是否使用 比率/ 概率 进行编码的

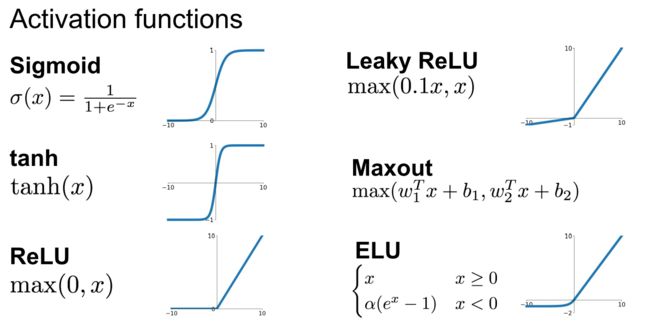
激活函数
具体的每一个函数的简介可参照该文>>
神经网络
神经网络是神经元互相连接构成的一个非循环的图(graph,有方向的),也就是说一些神经元的输出会作为其他神经元的输入。
环路是不允许的因为这会使得神经网络的前向传播陷入无止尽的循环中

全连接层(fully-connected layer)
表示的是相邻两层之间的神经元两两连接,同层的神经元则互不连接。如上图
命名习惯:平时说N层神经网络,是不把输入层计算在内的。一个单层神经网络表示的是输入层接输出层,没有隐含层的网络结构。
输出层:和神经网络其他的层不同,最后的输出层通常情况下没有activation function,这是因为最后一层的输出通常用来表示类别的score(特别是分类),score通常是实值的数。
神经网络的大小:衡量某个神经网络有多大,通常有两种方法,1是神经元的数目,2是参数的数目,相比之下第二种更常用。比如说以上图为例:
- 上图左的网络共包含(4+2=6)个神经元(不包括输入层),参数则有[3*4]+[4*2]=20个weights还有[4+2=6]个bias,也就是总共26个可学习的参数。
- 上图右的网络共包含(4+4+1=9)个神经元,参数则有[3*4]+[4*4]+[4*1]=12+16+4=32个weights还有[4+4+1=9]个bias,也就是总共41个可学习的参数。
实际上,现在所有的卷积网络通常都包含亿级的参数,并且由10-20层网络组成(因此说是deep learning)。
前馈神经网络

如何设置神经网络的层数和神经元数?
如果是为了最终的准确性,那么越多越好。无论是增加层数、还是增加神经元数目,神经网络的性能都会有所提升。因为神经元可以协同作用表达出不同的函数来对数据进行表示。
比如:假设在二维空间中有一个二值的分类问题,我们可以训练3个不同的神经网络,每个神经网络都包含一个隐含层,但是隐含层中包含的神经元数目不一样(3个、6个、20个),分类器的分类效果如下图:

上图结论:同样层数的情况下,神经元越多的神经网络对现有的数据拟合越好,因为它们更能够表达更加复杂的函数。
优点:可以对更复杂的数据进行分类
缺点:容易对训练数据过拟合(overfitting)。比如,
隐层包含20个神经元的图,它虽然把所有的数据都分对了,但把整个平面分成了红绿相间、相互脱节的小区域,看上去很不平滑。而3个神经元的图,它能够从大方向上去分类数据,而把一些被绿色点包围的红色点看成是异常值、噪声(outliers)。实际中这能够使得模型在测试数据上有更好的泛化能力。
基于上述讨论,貌似当数据不太复杂的时候,可以选用小一点的神经网络来预防overfitting?
No!我们可以选择其他更好的方法来避免过拟合(比如L2正则化,dropout,增加噪声等)。实际中用这些方法避免过拟合,比减少神经元的个数要更好。
比如:可以观察不同的正则强度是如何控制20个隐含神经元的过拟合的,见下图
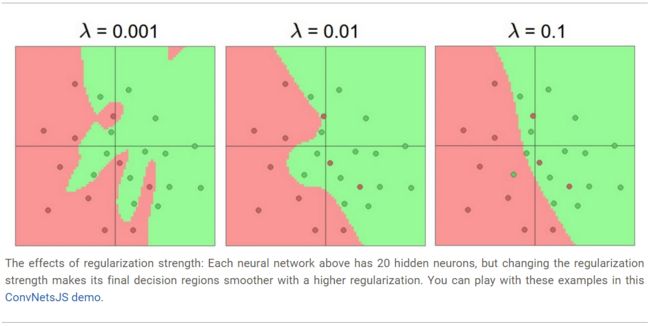
当λ(lambda) = 0.001 时(较小),生成的曲线弯曲程度很高,有过拟合的嫌疑。
λ = 0.01时,生成的分类曲线已经相对圆滑,已经基本可以划分红绿点,认为在绿色区域的是哪个红点属于噪音数据。
λ = 0.1时,生成的分类曲线已经相对很接近直线,相较于λ = 0.01时,认为红色区域中1个绿色点也是异常值了。
关于正则化,可以点击链接,进行简单回顾下,核心的表现形式如下:

用λ(lambda)来约束权重系数w,让它尽可能简单。如果 λ 比较大,则说明我们更看重正则化损失,如果比较 小 ,就说明更看重数据损失。λ 过大了会造成欠拟合问题,过小会造成过拟合问题。
总结:不能因为担心过拟合就使用小一点的神经网络,相反如果你的计算机性能允许,你应该用大的神经网络,并通过一些正则化的方法来控制过拟合(over-fitting).
总结
向量(vector)运算会更加高效