SparkStreaming的介绍及处理数据流程
介绍:
流式数据处理(stream processing)
要处理的数据就像流水一样,源源不断的产生数据,需要实时进行处理
对SparkCore的高级API的封装,将流式的数据切分为小的批次batch(按照时间间隔)的数据,然后使用SparkCore进行处理
在大数据技术框架中,对于流式数据的实时数据分析处理方案:
一条一条的处理
来一条数据就处理一条数据
典型框架:Storm
特点:
实时性很高,亚秒级别,延迟性很低
一批次一批次数据的处理
按照时间间隔将数据划分,时间比较短,比如1s
框架:sparkStreaming
近实时流式数据处理框架,延迟性也很低,2.2.0以后开始,1ms以内
sparkStreaming处理数据流程
1)数据源
从哪里读取数据,进程数据的处理
Kafka(多数)
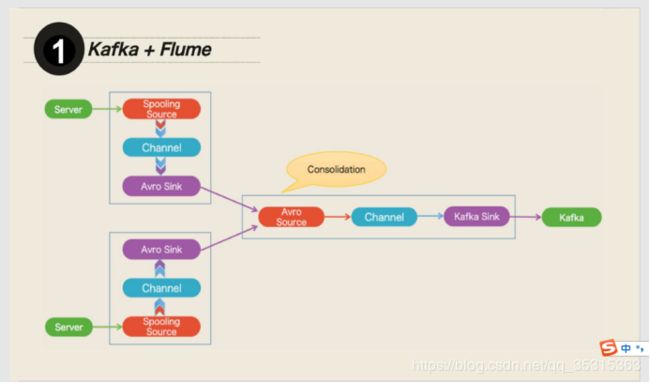
Flume(少数):Flume可以实时采集数据,然后给Spark
TCP socket(开发测试)
(2)数据处理
DStream#transfotmation
调用转换函数,将一个DStream转成另外一个DStream
针对不同的业务使用不同函数
企业使用最多2种统计类型函数
-实时累加统计
比如 双十一,销售订单额,订单数统计
DStream.updateStateByKey
-实时统计某时段内数据
比如:趋势分析,滴滴打车,最近10分钟路况,未来30分钟路况
11:20~11:50 半小时内,订单未送达的量
DStream#window
3)存储数据
就是就是调用RDD中API将数据存储,批次处理(core)
console
开发测试的时候,将实时分析的数据每次批次结果RDD数据打印在控制台
redis
基于内存的分布式Key/value数据库
HBase
存储到HBase表中
RDBMS
关系型数据
需要了解的几个类
StreamingContext
如何读取数据
DStream
处理数据函数
DStream里面存储着很多RDD
PairDStreamFunctions
当处理的数据类型是二元组的时候,
DStream自动隐式转换为PairDStreamFunctions
RDD
输出函数,将结果保存到外部系统
def foreachFunc: (RDD[T], Time) => Unit = {
(rdd: RDD[T], time: Time) => {
….
}}
企业中典型技术架构
flume/SDK ->Kafka ->SparkStreaming/Storm/Flink ->redis/HBase
架构图:
spark运行工作原理
batchInterval:批处理时间间隔
· 通过创建StreamingContext实例对象的时候进行设置
表明每次处理数据时间间隔,RDD
blockInterval:每个Block时间间隔
启动Streaming应用的时候,将启动Receiver用于接收数据
按照blockInterval将数据划分为Block,
默认blockInterval为200ms
计算:如果一个batchInterval是1S,blockInterval为200ms,有几个block块
batchInterva/blockInterval = 5
优化
对于SparkStreaming实时流式数据
每个批次处理的时间 小于等于 batchInterval时间
如果大于,需要考虑优化程序
每批次的数据RDD在执行,可以增加RDD分区数,增加Task数目,在资源充足的情况下,增加并行执行Task数目
优化点
减少blockInterval的值,比如设置为100ms
spark.streaming.blockInterval