Python爬虫入门实战
Python爬虫入门实战
Python的简介:
学python后能够干什么?
运维、web开发、应用开发、大数据、数据挖掘、科学计算、机器学习、人工智能、自然语言处理
python专业分成两个课程
--Python开发:侧重于测试,运维方向,课程涵盖网络编程,数据库操作、网络爬虫、网络监控,自动化测试、自动化运维等Python最主流的技术。
--Python+大数据:即Python企业级开发与大数据运维,作为和大数据运维无缝结合的语言,python+大数据才是真正的大数据
Python特点:
可移植性:由于Python开源本质,它已经被移植在许多平台上了
高层语言:无需考虑如何管理你的程序使用的内存一类的底层细节问题
面向对象:Python既支持面向过程的编程,也支持面向对象的编程
可扩展性:Python编辑的程序中可以直接调用部分c或者C++开发的程序
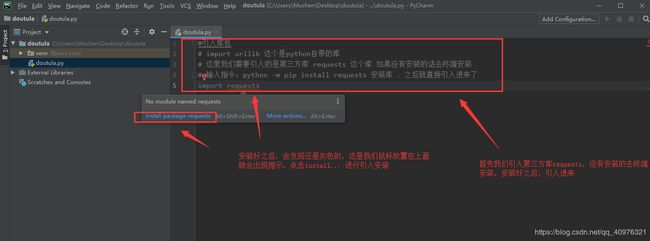
丰富的库:Python庞大的标准库可以帮助处理各种工作,几乎无所不能(urllib库,python自带的库,requests第三方库)
规范的代码:Python不需要编译成二进制代码的强制缩进方式,使得代码具有较好的可读性
实战目标:爬取斗图啦网站上面的图片http://www.doutula.com/

工具python3.7 + Pycharm编辑器 + 谷歌浏览器 没有下载好的先去下载
不会的去看我另一篇博客关于python工具的下载文章
https://blog.csdn.net/qq_40976321/article/details/97838450
步骤一:创建一个新项目File—New Project
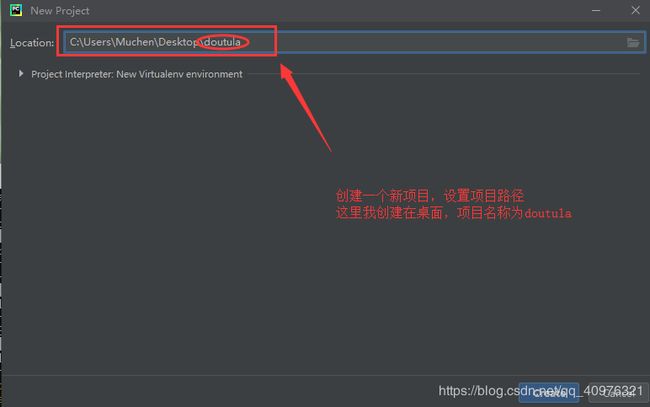
在项目中创建一个python file 文件
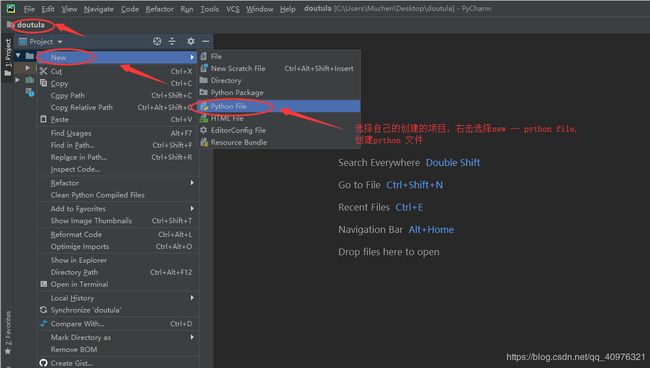
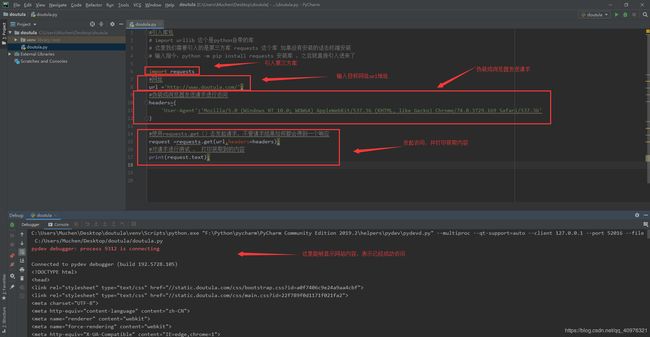
步骤二:引入我们需要的第三方库
创建好之后,我们先安装我们接下来要使用的第三方库 requests库,打开终端,
输入指令:python -m pip install requests
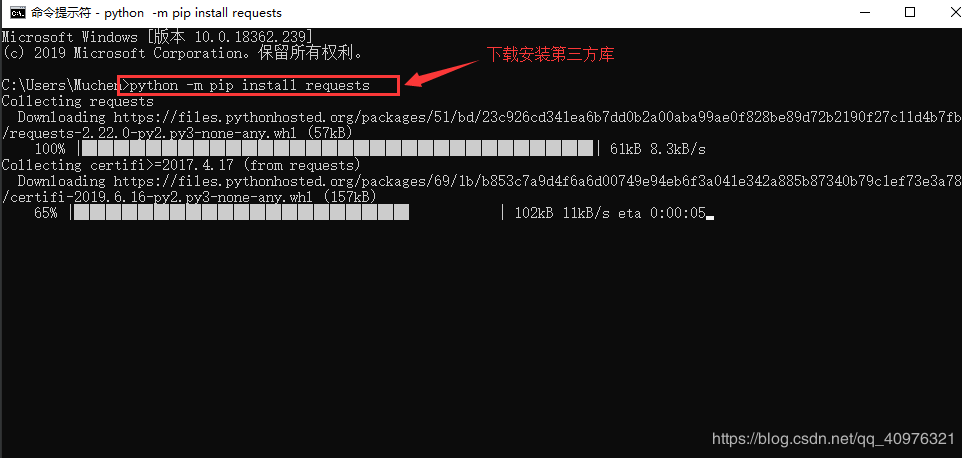
安装后会出现提示,pip版本的更新提示(如果没有提示,就忽略此步骤),之后输入它的指令
python -m pip install --upgrade pip

引入库包,urllib这个库是python自带的库,requests这个是第三方库,需要去下载,上面已经有下载的方法

步骤三:学会伪装,测试能够请求成功,获取信息

User-Agent:表示当前请求是谁发出来的,一般是浏览器发送的,所以user-Agent这个字段会显示,所以在写爬虫是要把这个写上,伪装成浏览器进行请求访问
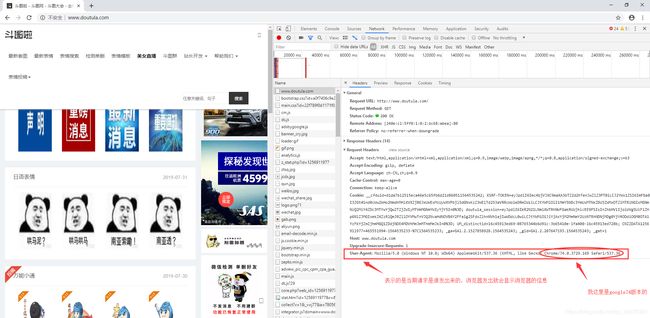
测试是否能够成功获取信息
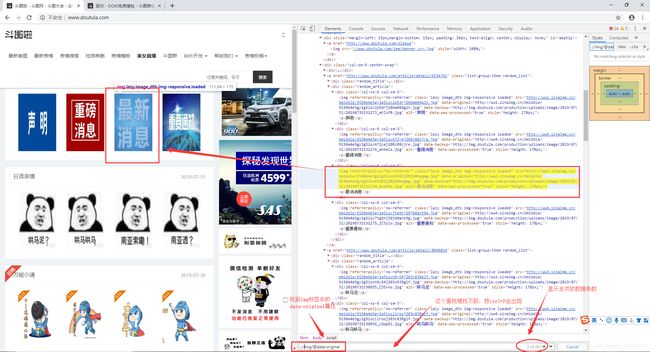
步骤四:发起请求并获取链接 ,找到目标网站上面的图片链接地址
找到图片的地址标签的属性值,这里找到的是data-original

在网站上ctrl+F根据要求查找img标签中的data-original的地址
.//img/@data-original 点表示当前目录 /表示一个子集 //表示html下的所有子集标签
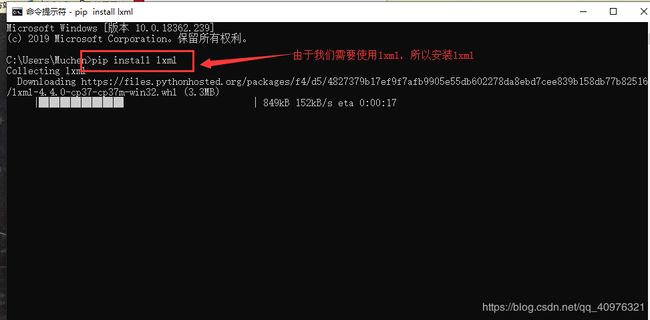
由于我们要使用lxml,所以到终端输入指令:pip install lxml 之后才可以使用它来解析

安装好lxml之后,重新启动项目,就能够成功获取到目标网址

步骤五:提取图片名,下载图片
使用 spilt()方法进行分割,按 / 分割出最后一段内容
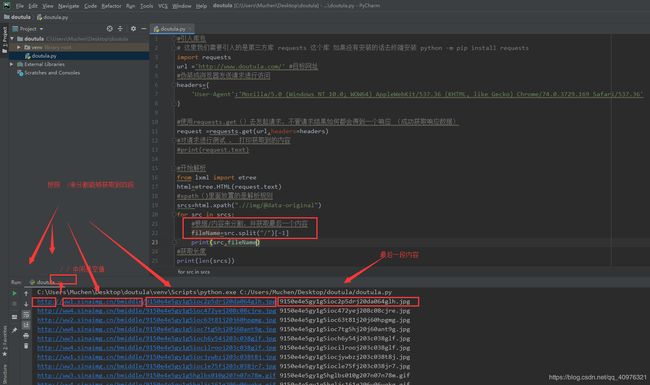
知识扩展
User-Agent : 标识请求是浏览器发出的,显示浏览器的一个具体信息,方便服务器来识别
Referer : url从哪里来,从那个网址发出的,在做图片存储的时候,提供一个图片的存储服务,存储服务中有一个叫防跨域请求的服务,设置了这个,会检查你Referer来源,用来限制别人来盗用图片,一定程度上影响了爬虫的工作,所有在加载图片的时候要把Referer加上。Referer的值= http:// + 网址的域名

# 图片下载的知识点 Referer
# img是图片响应 不能字符串解析
# img.content是图片的字节内容, 使用字节流模式wb img.text是无法解析的
# 有了with 就不用担心没有关闭文件流的问题了 它会实现自动关闭或者打开 文件路劲+名称 打开文件模式 图片是字节 wb 读写二进制
with open("img/"+fileName,'wb') as file:
file.write(img.content) #写入图片的字节内容 img.content

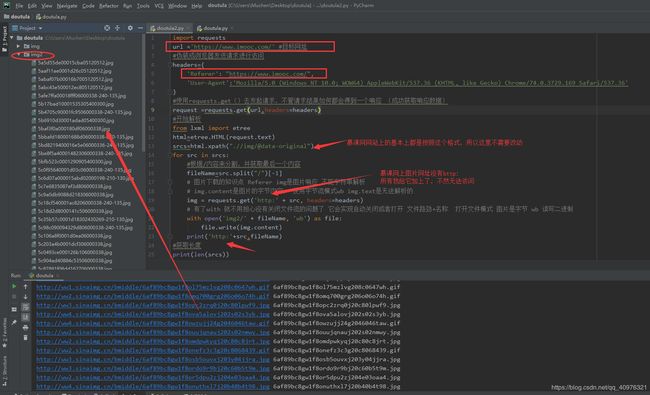
能够正常的下载图片,但是下载的图片无法正常打开,原因不清楚,于是我换了个目标网址
换到把目标地址换成慕课网,发现能够正常的去访问,将图片下载下来
步骤六:实现自动翻页
在网页上找到下一页的所在位置

比较第一页及第二页之间的关系,是否有一定规律

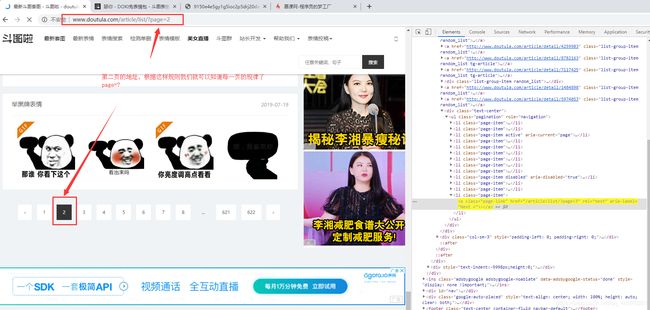
通过循环+函数返回值的方法不断获取到每个界面中的下一页的链接,通过while循环不断去寻找下一页直到最后一页为止
获取的是下一页的链接next_link = html.xpath('.//a[@rel="next"]/@href') # 返回列表

步骤七:按照页面分目录下载图片
我们需要创建一个函数,将解析图片链接下载的方法放置到函数中

成功创建文件夹并下载图片

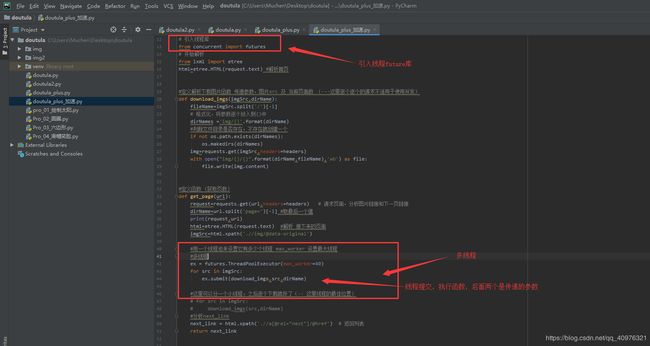
步骤八:进阶部分,加速,最简单好用的并发操作
在python中有线程池和进程池的并发 futures库
Concurrent库是python3.2之后官方集成的一个库,封装了线程和进程这两个库
使用多线程之后,下载和加载速度有着明显的提高
爬虫实例项目源码:
链接:https://pan.baidu.com/s/13gfPndE6bjPJImE3TOk69g
提取码:ek8a

如果对于教程还是有疑问或者还不是很清楚的,建议去看看相关的视频教程:
https://study.163.com/course/courseMain.htm?courseId=1006148015&_trace_c_p_k2_=25fab5aec5ba40f5ad441a4d88cf36f1