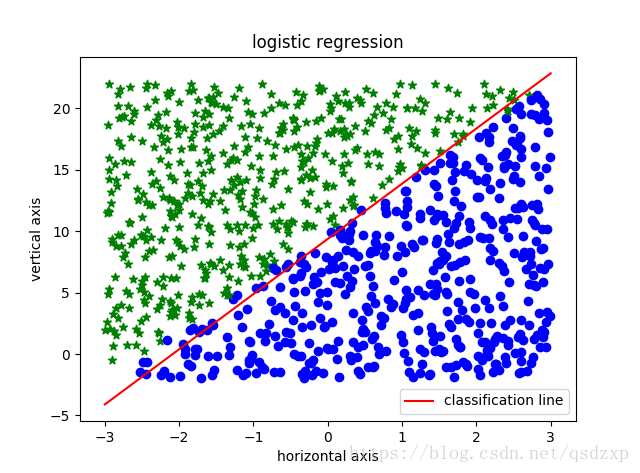
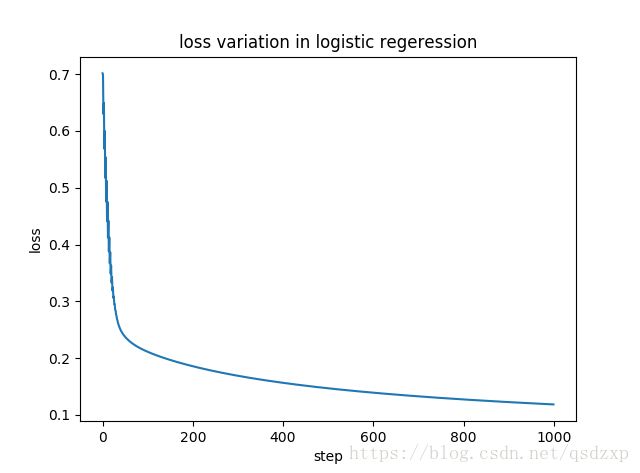
吴恩达机器学习 笔记三 logistic回归
1. 二元分类
1.1 logistic模型
首先,我们需要搞清楚二元分类模型与之前的线性回归模型的区别。之前的线性回归模型是预测连续输出,对应的典型问题就是预测房价。而现在的二元分类问题是预测一个离散的输出,只关心有无,对应的典型问题就是预测有无癌症。二元分类问题只需要选取一个阈值,超过这个阈值就是 y=1 y = 1 ,低于这个阈值就是 y=0 y = 0 。并且预测分析的输出最好是在 [0,1] [ 0 , 1 ] 这个范围之内的,因为毕竟训练数据集中的输出也只有 0 0 和 1 1 。
根据上面分析,二元分类问题对于 hθ⃗ (x⃗ ) h θ → ( x → ) 有一个要求:
hθ⃗ (x⃗ )∈[0,1] h θ → ( x → ) ∈ [ 0 , 1 ]
而logistic函数就有这样优秀的性质。我们令
hθ⃗ (x⃗ )=g(θ⃗ Tx⃗ ) h θ → ( x → ) = g ( θ → T x → )
其中
g(z)=11+e−z g ( z ) = 1 1 + e − z 。
其实,logistic函数就是把一个连续的输出映射到 [0,1] [ 0 , 1 ] 这个范围内。此外,logistic函数还有一个优秀的性质就是,处处可导,这第一点对于学习过程是非常重要的。
1.2 决策边界
由上面的表达式可以看出,logistic回归模型中logistic函数的输入相当带有线性回归的意味。但是这里的不同点在于,线性回归要做的是预测一个具体的输出。由于在二元分类中,我们只关心是大于还是小于某个阈值,因此logistic模型中logistic函数的输入对应的是阈值、边界的意思。这里,同样的道理,当用直线明显难以区分开两个分类式,需要曲线的时候就要引入高次项。
1.3 代价函数
由于logistic函数的存在,继续使用训练数据集误差的平方和做代价函数会带来非凸的问题。因此我们需要重新定义代价函数
J(θ)=1m∑i=1mCost(hθ⃗ (x⃗ (i)),y(i)) J ( θ ) = 1 m ∑ i = 1 m C o s t ( h θ → ( x → ( i ) ) , y ( i ) )
Cost(hθ⃗ (x⃗ (i)),y(i))=−y(i)log(hθ⃗ (x⃗ (i)))−(1−y(i))log(1−hθ⃗ (x⃗ (i))) C o s t ( h θ → ( x → ( i ) ) , y ( i ) ) = − y ( i ) l o g ( h θ → ( x → ( i ) ) ) − ( 1 − y ( i ) ) l o g ( 1 − h θ → ( x → ( i ) ) )
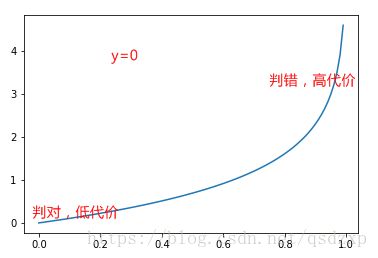
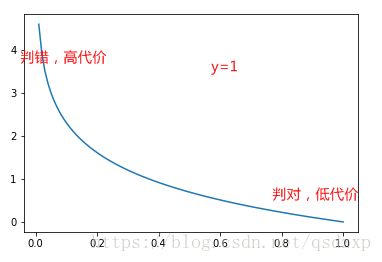
从图上可以看到,当判断出现错误时,在代价函数中给予了非常高的惩罚。
求解的过程依然是梯度下降,具体的公式就不敲了(可以手动推导一些)。
∂∂θjJ(θ)=1m∑i=1m[hθ⃗ (x⃗ (i))−y(i)]x(i)j ∂ ∂ θ j J ( θ ) = 1 m ∑ i = 1 m [ h θ → ( x → ( i ) ) − y ( i ) ] x j ( i )
这里需要
注意的是
1.由于logistic函数的存在,这里的梯度下降跟之前的梯度下降实际上式不一样的
2.特征缩放依旧是必要的
1.4 二元分类代码
可以独立完成这种简单的tensorflow程序了,欧耶。
'''
Author : vivalazxp
Date : 8/30/2018
Description : logistic regression
'''
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
'''
Description : create data for logistic regression
Param : @numData number of data
@weight (border line)category_from_data = weight * axis_from_data + bias
@bias (border line)category_from_data = weight * axis_from_data + bias
@horizon_limit horizontal limit
Return : @axis_data shape=(2,numData)
axis_data[0,:] horizontal axis of training data
axis_data[1,:] vertical axis of training data
@category_data catrgory of training data shape=(numData,)
'''
def data_create_logstic_reg(numData, weight, bias, horizon_limit ):
axis_data = np.zeros([2,numData])
# horizontal and vertical axis
axis_data[0,:] = horizon_limit * 2*(np.random.rand(numData)-0.5)
sigma = weight * horizon_limit
axis_data[1,:] = sigma * 2*(np.random.rand(numData)-0.5) + bias
# category
category_data = np.zeros(numData)
plt.figure(1)
for index in range(numData):
if weight * axis_data[0, index] + bias - axis_data[1,index] >= 0:
category_data[index] = 1
plt.scatter(axis_data[0, index], axis_data[1, index], c='b', marker='o')
else:
category_data[index] = 0
plt.scatter(axis_data[0, index], axis_data[1, index], c='g', marker='*')
print('---------- create data sucessfully ----------')
return axis_data,category_data
'''
Description : logistic regression
Param : @axis_data horizontal and vertical axis of training data shape=(2,numData)
@category_data category of training data shape=(numData,)
@alpha learning rate
@steps sum learning steps
Return : @theta weight (not the same as "weight" in data_create_logstic_reg) shape=(1,2)
@theta0 bias (not the same as "bias" in data_create_logstic_reg)
'''
def logistic_reg(axis_data, category_data, alpha, steps):
#placeholder for training data
axis_from_data = tf.placeholder(tf.float32)
category_from_data = tf.placeholder(tf.float32)
#initialize randomly theta and theta0
theta = tf.Variable(tf.random_normal([1,2]))
theta0 = tf.Variable(tf.random_normal([1]))
category_pred = tf.sigmoid( tf.matmul(theta,axis_from_data)+theta0 )
#cost
cost = tf.reduce_mean(- category_from_data * tf.log(category_pred) \
- (1 - category_from_data) * tf.log(1 - category_pred))
optimizer = tf.train.GradientDescentOptimizer(alpha).minimize(cost)
#session
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
print('-------- train started --------')
loss = np.zeros(steps)
for step in range(steps):
sess.run(optimizer,feed_dict={axis_from_data:axis_data,category_from_data:category_data})
loss[step] = sess.run(cost,feed_dict={axis_from_data:axis_data,category_from_data:category_data})
print('-------- train finished --------')
theta = sess.run(theta)
theta0 = sess.run(theta0)
return theta,theta0,loss
if __name__ == "__main__":
numData = 1000
weight = 4
bias = 10
horizon_limit = 3
alpha = 0.1
steps = 1000
axis_data,category_data = data_create_logstic_reg(numData, weight, bias, horizon_limit)
theta, theta0, loss = logistic_reg(axis_data, category_data, alpha, steps)
# classification line
weight_train = -theta[0,0]/theta[0,1]
bias_train = -theta0/theta[0,1]
horizon_plot = np.linspace(-horizon_limit,horizon_limit,100)
vertical_plot = weight_train * horizon_plot + bias_train
plt.plot(horizon_plot, vertical_plot, 'r', label='classification line')
plt.legend()
plt.xlabel('horizontal axis')
plt.ylabel('vertical axis')
plt.title('logistic regression')
# loss
plt.figure(2)
plt.plot(range(steps), loss)
plt.xlabel('step')
plt.ylabel('loss')
plt.title('loss variation in logistic regeression')
plt.show()