【从线性回归到BP神经网络】第一部分:协方差与相关系数
文章目录
- 1、样本均值
- 2、样本方差
- 3、协方差
- 4、相关系数
- 5、 示例:数据集的相关系数计算
本文主要参考文献如下:
1、吴恩达CS229课程讲义。
2、(美)S.Chatterjee等,《例解回归分析》(第2章),机械工业出版社。
3、周志华. 《机器学习》3.2.清华大学出版社。
4、(美)P.Harrington,《机器学习实战》人民邮电出版社。
由于数据处理经常需要计算样本的统计特性,这里我们首先对此进行讨论。
1、样本均值
对于随机变量 X X X,其均值 m X = E ( x ) m_X={\rm E}(x) mX=E(x),方差为 σ X 2 = E [ ( x − m X ) 2 ] \sigma_X^2={\rm E}[(x-m_X)^2] σX2=E[(x−mX)2]。设有 X X X的样本 { x 1 , x 2 , … , x n } \{x_1,x_2,\ldots,x_n\} {x1,x2,…,xn},则样本均值为
m ^ X = 1 n ∑ i = 1 n x i . (1) \tag{1} \hat m_X=\frac{1}{n}\sum_{i=1}^{n}x_i. m^X=n1i=1∑nxi.(1)
可以证明, m ^ x \hat m_x m^x是均值 m x m_x mx的无偏估计,即 E [ m ^ X ] = m X {\rm E}[\hat m_X]=m_X E[m^X]=mX,证明如下:
E [ m ^ x ] = E [ 1 n ∑ i = 1 n x i ] = 1 n ∑ i = 1 n E [ x i ] = 1 n ∑ i = 1 n m X = m X . \begin{aligned} {\rm E}[\hat m_x]&={\rm E}\left[\frac{1}{n}\sum_{i=1}^{n}x_i\right]\\ &=\frac{1}{n}\sum_{i=1}^{n}{\rm E}\left[x_i\right]\\ &=\frac{1}{n}\sum_{i=1}^{n}m_X=m_X. \end{aligned} E[m^x]=E[n1i=1∑nxi]=n1i=1∑nE[xi]=n1i=1∑nmX=mX.
2、样本方差
对于随机变量 X X X,其均值 m X = E ( x ) m_X={\rm E}(x) mX=E(x),方差为 σ X 2 = E [ ( x − m X ) 2 ] \sigma_X^2={\rm E}[(x-m_X)^2] σX2=E[(x−mX)2],样本方差为
σ ^ X 2 = 1 n − 1 ∑ i = 1 n ( x i − m ^ X ) 2 . (2) \tag{2} \hat \sigma_X^2=\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\hat m_X)^2. σ^X2=n−11i=1∑n(xi−m^X)2.(2)
我们来看为何上式中求样本方差时,为何对 n n n项求和,却除以 n − 1 n-1 n−1呢?
这主要是因为我们希望 σ ^ X 2 \hat \sigma^2_X σ^X2是 σ X 2 \sigma_X^2 σX2的无偏估计,如果我们除以 n n n,会遇到下面情况:
E [ σ ^ X 2 ] = E [ 1 n ∑ i = 1 n ( x i − m ^ X ) 2 ] = 1 n E [ ∑ i = 1 n ( x i − m ^ X ) 2 ] = 1 n E [ ∑ i = 1 n ( x i 2 + m ^ X 2 − 2 x i m ^ X ) ] = E [ 1 n ∑ i = 1 n x i 2 − m ^ X 2 ] = 1 n ∑ i = 1 n E [ x i 2 ] − E [ m ^ X 2 ] = E [ x 2 ] − E [ m ^ X 2 ] = ( E [ x 2 ] − m X 2 ) − ( E [ m ^ X 2 ] − m X 2 ) = σ X 2 − v a r [ m ^ X 2 ] \begin{aligned} {\rm E}\left[\hat \sigma_X^2\right]&={\rm E}\left[\frac{1}{n}\sum_{i=1}^{n}(x_i-\hat m_X)^2\right]\\ &=\frac{1}{n}{\rm E}\left[\sum_{i=1}^{n}(x_i-\hat m_X)^2\right]\\ &=\frac{1}{n}{\rm E}\left[\sum_{i=1}^{n}(x_i^2+\hat m_X^2-2x_i\hat m_X)\right]\\ &={\rm E}\left[\frac{1}{n}\sum_{i=1}^{n}x_i^2-\hat m_X^2\right]\\ &=\frac{1}{n}\sum_{i=1}^{n}{\rm E}\left[x_i^2\right]-{\rm E}\left[\hat m_X^2\right]\\ &={\rm E}\left[x^2\right]-{\rm E}\left[\hat m_X^2\right]\\ &=({\rm E}\left[x^2\right]-m_X^2)-({\rm E}\left[\hat m_X^2\right]-m_X^2)\\ &=\sigma_X^2-{\rm var}[\hat m_X^2] \end{aligned} E[σ^X2]=E[n1i=1∑n(xi−m^X)2]=n1E[i=1∑n(xi−m^X)2]=n1E[i=1∑n(xi2+m^X2−2xim^X)]=E[n1i=1∑nxi2−m^X2]=n1i=1∑nE[xi2]−E[m^X2]=E[x2]−E[m^X2]=(E[x2]−mX2)−(E[m^X2]−mX2)=σX2−var[m^X2]由于 v a r [ m ^ X 2 ] = v a r [ 1 n ∑ i = 1 n x i ] = 1 n 2 ∑ i = 1 n v a r [ x i ] = σ X 2 n \begin{aligned} {\rm var}[\hat m^2_X]&={\rm var}\left[\frac{1}{n}\sum_{i=1}^{n}x_i\right]\\ &=\frac{1}{n^2}\sum_{i=1}^{n}{\rm var}\left[x_i\right]\\ &=\frac{\sigma_X^2}{n} \end{aligned} var[m^X2]=var[n1i=1∑nxi]=n21i=1∑nvar[xi]=nσX2因此
E [ σ ^ X 2 ] = n − 1 n σ X 2 \begin{aligned} {\rm E}\left[\hat \sigma_X^2\right]=\frac{n-1}{n}\sigma_X^2 \end{aligned} E[σ^X2]=nn−1σX2显然不是 σ X 2 \sigma_X^2 σX2的无偏估计。因此,我们将该估计进行修正,可以得到
E [ σ ^ X 2 ] = E [ 1 n − 1 ∑ i = 1 n ( x i − m ^ X ) 2 ] = 1 n − 1 E [ ∑ i = 1 n ( x i − m ^ X ) 2 ] = 1 n − 1 E [ ∑ i = 1 n ( x i 2 + m ^ X 2 − 2 x i m ^ X ) ] = 1 n − 1 E [ ∑ i = 1 n x i 2 − n ⋅ m ^ X 2 ] = E [ 1 n ∑ i = 1 n x i 2 − m ^ X 2 ] = n n − 1 ( E [ x 2 ] − E [ m ^ X 2 ] ) = σ X 2 \begin{aligned} {\rm E}\left[\hat \sigma_X^2\right]&={\rm E}\left[\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\hat m_X)^2\right]\\ &=\frac{1}{n-1}{\rm E}\left[\sum_{i=1}^{n}(x_i-\hat m_X)^2\right]\\ &=\frac{1}{n-1}{\rm E}\left[\sum_{i=1}^{n}(x_i^2+\hat m_X^2-2x_i\hat m_X)\right]\\ &=\frac{1}{n-1}{\rm E}\left[\sum_{i=1}^{n}x_i^2-n\cdot\hat m_X^2\right]\\ &={\rm E}\left[\frac{1}{n}\sum_{i=1}^{n}x_i^2-\hat m_X^2\right]\\ &=\frac{n}{n-1}\left({\rm E}\left[x^2\right]-{\rm E}\left[\hat m_X^2\right]\right)\\ &=\sigma_X^2 \end{aligned} E[σ^X2]=E[n−11i=1∑n(xi−m^X)2]=n−11E[i=1∑n(xi−m^X)2]=n−11E[i=1∑n(xi2+m^X2−2xim^X)]=n−11E[i=1∑nxi2−n⋅m^X2]=E[n1i=1∑nxi2−m^X2]=n−1n(E[x2]−E[m^X2])=σX2为无偏估计。
3、协方差
下面我们来定义两个随机变量 X X X和 Y Y Y的样本的协方差,这里假设 X X X的样本为 { x 1 , x 2 , … , x n } \{x_1,x_2,\ldots,x_n\} {x1,x2,…,xn}, Y Y Y的样本为 { y 1 , y 2 , … , y n } \{y_1,y_2,\ldots,y_n\} {y1,y2,…,yn},则有
c o v ( X , Y ) = ∑ i = 1 n ( y i − m ^ Y ) ( x i − m ^ X ) n − 1 . (3) \tag{3} {\rm cov}(X,Y)=\frac{\sum_{i=1}^{n}(y_i-\hat m_Y)(x_i-\hat m_X)}{n-1}. cov(X,Y)=n−1∑i=1n(yi−m^Y)(xi−m^X).(3)
4、相关系数
进一步,可以对两个随机变量进行标准化处理,得到 X X X和 Y Y Y的相关系数为
c o r ( Y , X ) = 1 n − 1 ∑ i = 1 n ( y i − m ^ Y σ ^ Y ) ( x i − m ^ X σ ^ X ) = 1 n − 1 ∑ i = 1 n ( y i − m ^ Y ) ( x i − m ^ X ) σ ^ Y σ ^ X = ∑ i = 1 n ( y i − m ^ Y ) ( x i − m ^ X ) ∑ ( x i − m ^ X ) 2 ∑ ( x i − m ^ X ) 2 (4) \tag{4} \begin{aligned} {\rm cor}(Y,X)&=\frac{1}{n-1}\sum_{i=1}^{n}(\frac{y_i-\hat m_Y}{\hat\sigma_Y})(\frac{x_i-\hat m_X}{\hat \sigma_X})\\ &=\frac{1}{n-1}\sum_{i=1}^{n}\frac{(y_i-\hat m_Y)(x_i-\hat m_X)}{\hat\sigma_Y \hat \sigma_X}\\ &=\frac{\sum_{i=1}^{n}(y_i-\hat m_Y)(x_i-\hat m_X)}{\sqrt{\sum(x_i-\hat m_X)^2 \sum(x_i-\hat m_X)^2}}\\ \end{aligned} cor(Y,X)=n−11i=1∑n(σ^Yyi−m^Y)(σ^Xxi−m^X)=n−11i=1∑nσ^Yσ^X(yi−m^Y)(xi−m^X)=∑(xi−m^X)2∑(xi−m^X)2∑i=1n(yi−m^Y)(xi−m^X)(4)
注意相关系数的如下性质:
- c o r ( Y , X ) = c o r ( X , Y ) {\rm cor}(Y,X)={\rm cor}(X,Y) cor(Y,X)=cor(X,Y)
- − 1 ≤ c o r ( Y , X ) ≤ 1 -1\le {\rm cor}(Y,X) \le 1 −1≤cor(Y,X)≤1
- 相关系数只能刻画变量间线性关系的强弱。
- 相关系数会受到数据中一个或者几个离群值的显著影响。
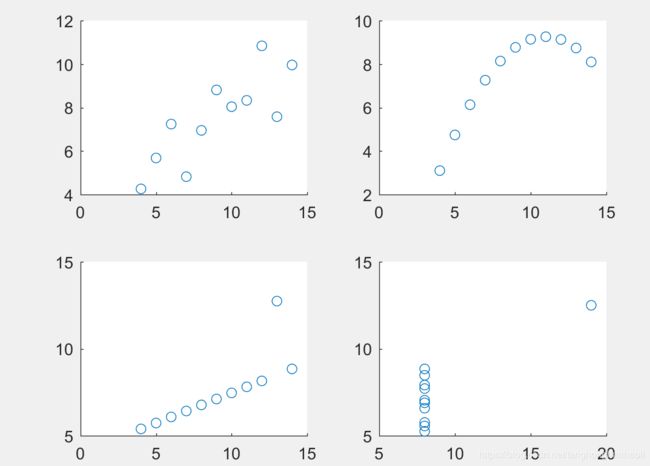
5、 示例:数据集的相关系数计算
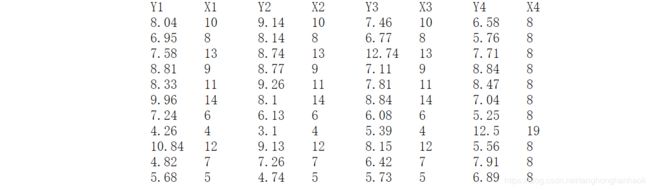
下面我们看个例子。我们计算下表中的四个数据集,分别计算相关系数,并画出散点图。
Matlab代码如下:
A=load('Data_Chap2_Anscombe.txt')
Cor_12=corrcoef(A(:,1),A(:,2))
Cor_34=corrcoef(A(:,3),A(:,4))
Cor_56=corrcoef(A(:,5),A(:,6))
Cor_78=corrcoef(A(:,7),A(:,8))
subplot(2,2,1)
scatter(A(:,2),A(:,1))
subplot(2,2,2)
scatter(A(:,4),A(:,3))
subplot(2,2,3)
scatter(A(:,6),A(:,5))
subplot(2,2,4)
scatter(A(:,8),A(:,7))
得到相关系数为
Cor_12 =
1.0000 0.8164
0.8164 1.0000
Cor_34 =
1.0000 0.8162
0.8162 1.0000
Cor_56 =
1.0000 0.8163
0.8163 1.0000
Cor_78 =
1.0000 0.8165
0.8165 1.0000
显然,尽管相关系数基本相等,但从下图散点图中可以看出,四组数据 Y Y Y与 X X X的函数关系差别很大。因此在计算相关系数之前,考察散点图是非常有帮助的。