【从线性回归到BP神经网络】第三部分:Logistic回归
文章目录
- 1、 Logistic函数
- 2、最大似然函数准则
- 3、用梯度下降法来最大化对数似然
本文主要参考文献如下:
1、吴恩达CS229课程讲义。
2、(美)S.Chatterjee等,《例解回归分析》(第2章),机械工业出版社。
3、周志华. 《机器学习》3.2.清华大学出版社。
4、(美)P.Harrington,《机器学习实战》人民邮电出版社。
5、陈明等,《MATLAB神经网络原理与实例精解》,清华大学出版社。
1、 Logistic函数
下面我们来考虑如何将线性回归用于二分类问题。显然,经过线性回归之后的输出
y ^ = h θ ( x ) = θ T x \hat { y}=h_{\bm \theta}({\bf x})={\bm \theta}^{\rm T}{\bf x} y^=hθ(x)=θTx是实数。如果 y ∈ [ 0 , 1 ] y\in [0,1] y∈[0,1],显然我们需要改变 h θ ( x ) h_{\bm \theta}({\bf x}) hθ(x)使其值也在0到1之间。这里我们采用Logistic函数,或者也叫Sigmoid函数如下:
h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x . (1) \tag{1} h_{\bm \theta}({\bf x})=g({\bm \theta}^{\rm T}{\bf x})=\frac{1}{1+e^{-{\bm \theta}^T{\bf x}}}. hθ(x)=g(θTx)=1+e−θTx1.(1)它的图形如图1所示。
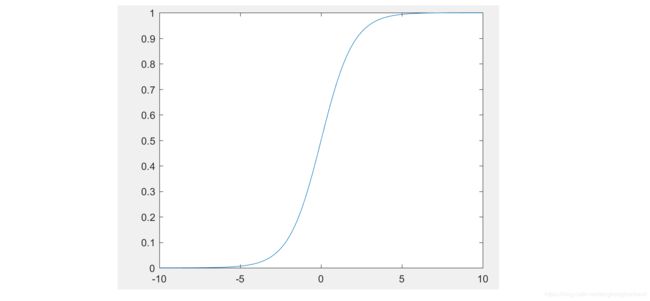
Sigmoid函数 g ( z ) g(z) g(z)有一个很重要的性质,就是它的微分
g ′ ( z ) = g ( z ) [ 1 − g ( z ) ] . (2) \tag{2} g'(z)=g(z)[1-g(z)]. g′(z)=g(z)[1−g(z)].(2)
我们来推导(2)。
g ′ ( z ) = d d z 1 1 + e − z = 1 ( 1 + e − z ) 2 ( e − z ) = 1 ( 1 + e − z ) ⋅ ( 1 − 1 1 + e − z ) = g ( z ) [ 1 − g ( z ) ] \begin{aligned} g'(z)&=\frac{d}{dz} \frac{1}{1+e^{-z}}\\ &=\frac{1}{(1+e^{-z})^2}(e^{-z})\\ &=\frac{1}{(1+e^{-z})}\cdot \left(1-\frac{1}{1+e^{-z}}\right)\\ &=g(z)[1-g(z)] \end{aligned} g′(z)=dzd1+e−z1=(1+e−z)21(e−z)=(1+e−z)1⋅(1−1+e−z1)=g(z)[1−g(z)]
2、最大似然函数准则
这里我们考虑二分类问题。由于 y y y的取值为0或者1,因此我们需要根据 h θ ( x ) h_{\bm \theta}({\bf x}) hθ(x)来猜测,到底输出 y ^ \hat {\bf y} y^为0还是1呢?由于 h θ ( x ) h_{\bm \theta}({\bf x}) hθ(x)的值在0到1之间,我们就用它作为概率值,即
P ( y = 1 ∣ x ; θ ) = h θ ( x ) P ( y = 0 ∣ x ; θ ) = 1 − h θ ( x ) (3) \tag{3}\begin{aligned} P(y=1|{\bf x};{\bm \theta})&=h_{\bm \theta}({\bf x})\\ P(y=0|{\bf x};{\bm \theta})&=1-h_{\bm \theta}({\bf x}) \end{aligned} P(y=1∣x;θ)P(y=0∣x;θ)=hθ(x)=1−hθ(x)(3)
我们从图2可以看出(3)的假设是合理的。如果Sigmoid函数的输入 θ T x {\bm \theta}^{\rm T}{\bf x} θTx大于0,则 h θ ( x ) h_{\bm \theta}({\bf x}) hθ(x)大于0.5,这意味着 y ^ \hat {\bf y} y^为1(>0)的可能性更大;反之,如果 θ T x {\bm \theta}^{\rm T}{\bf x} θTx小于0,则 h θ ( x ) h_{\bm \theta}({\bf x}) hθ(x)小于0.5,这意味着 y ^ \hat {\bf y} y^为0(<0)的可能性更大。
由于 y y y是二值离散随机变量,我们可以得到它的条件概率密度函数为
p ( y ∣ x ; θ ) = [ h θ ( x ) ] y [ 1 − h θ ( x ) ] 1 − y (4) \tag{4} p(y|{\bf x};{\bm \theta})=[h_{\bm \theta}({\bf x})]^{y}[1-h_{\bm \theta}({\bf x})]^{1-y} p(y∣x;θ)=[hθ(x)]y[1−hθ(x)]1−y(4)假定 m m m个样本彼此独立,我们得到关于参数 θ \bm \theta θ的似然函数为
L ( θ ) = ∏ i = 1 m [ h θ ( x ( i ) ) ] y ( i ) [ 1 − h θ ( x ( i ) ) ] 1 − y ( i ) (5) \tag{5} L({\bm \theta})=\prod_{i=1}^{m}[h_{\bm \theta}({\bf x}^{(i)})]^{y^{(i)}}[1-h_{\bm \theta}({\bf x}^{(i)})]^{1-y^{(i)}} L(θ)=i=1∏m[hθ(x(i))]y(i)[1−hθ(x(i))]1−y(i)(5)对数似然函数为
ℓ ( θ ) = ∑ i = 1 m y ( i ) log h θ ( x ( i ) ) + ( 1 − y ( i ) ) log [ 1 − h θ ( x ( i ) ) ] (6) \tag{6} \ell({\bm \theta})=\sum_{i=1}^{m}{y^{(i)}}\log h_{\bm \theta}({\bf x}^{(i)})+({1-y^{(i)}})\log [1-h_{\bm \theta}({\bf x}^{(i)})] ℓ(θ)=i=1∑my(i)loghθ(x(i))+(1−y(i))log[1−hθ(x(i))](6)
3、用梯度下降法来最大化对数似然
现在的优化问题变成
θ ^ ∗ = max θ ℓ ( θ ) . (7) \tag{7} \hat{\bm \theta}^*=\max \limits_{\bm \theta}\ell(\bm \theta). θ^∗=θmaxℓ(θ).(7)与线性回归类似,我们用梯度法来求解,即找到让 ℓ ( θ ) \ell (\bm \theta) ℓ(θ)变化最快的方向(梯度),从而更新参数
θ : = θ + α ▽ θ ℓ ( θ ) (8) \tag{8} \bm \theta:=\bm \theta+\alpha\bigtriangledown_{\bm \theta}\ell (\bm \theta) θ:=θ+α▽θℓ(θ)(8)注意由于求解最大值,上式中用的是加号而非减号。
我们先来求单个样本时的梯度。对于
ℓ ( θ ) = y log h θ ( x ) + ( 1 − y ) log [ 1 − h θ ( x ) ] (9) \tag{9} \ell({\bm \theta})={y}\log h_{\bm \theta}({\bf x})+({1-y})\log [1-h_{\bm \theta}({\bf x})] ℓ(θ)=yloghθ(x)+(1−y)log[1−hθ(x)](9)若 j = 0 , 1 , 2 … , n j=0,1,2\ldots,n j=0,1,2…,n,由于 h θ ( x ) = g ( θ T x ) h_{\bm \theta}({\bf x})=g({\bm \theta}^{\rm T}{\bf x}) hθ(x)=g(θTx),有
∂ ∂ θ j ℓ ( θ ) = [ y g ( θ T x ) − ( 1 − y ) 1 − g ( θ T x ) ] ∂ g ( θ T x ) ∂ θ j = [ y g ( θ T x ) − ( 1 − y ) 1 − g ( θ T x ) ] g ( θ T x ) [ 1 − g ( θ T x ) ] ⋅ ∂ ∑ j = 0 n θ j x j ∂ θ j = ( y − h θ ( x ) ) x j (10) \tag{10} \begin{aligned} \frac{\partial }{\partial \theta_j}\ell ({\rm \theta})&=\left[\frac{y}{g({\bm \theta}^{\rm T}{\bf x})}-\frac{(1-y)}{1-g({\bm \theta}^{\rm T}{\bf x})}\right]\frac{\partial g({\bm \theta}^{\rm T}{\bf x})}{\partial \theta_j}\\ &=\left[\frac{y}{g({\bm \theta}^{\rm T}{\bf x})}-\frac{(1-y)}{1-g({\bm \theta}^{\rm T}{\bf x})}\right] g({\bm \theta}^{\rm T}{\bf x})[1-g({\bm \theta}^{\rm T}{\bf x})]\cdot\frac{\partial \sum_{j=0}^{n}\theta_jx_j}{\partial \theta_j}\\ &=(y-h_{\bm \theta}({\bf x}))x_j \end{aligned} ∂θj∂ℓ(θ)=[g(θTx)y−1−g(θTx)(1−y)]∂θj∂g(θTx)=[g(θTx)y−1−g(θTx)(1−y)]g(θTx)[1−g(θTx)]⋅∂θj∂∑j=0nθjxj=(y−hθ(x))xj(10)因此,我们可以得到参数 θ \bm \theta θ的更新准则为
θ j : = θ j + α ⋅ ( y ( i ) − h θ ( x ( i ) ) ) x j ( i ) , j = 0 , 1 , … , n (11) \tag{11} \begin{aligned} \theta_j:=\theta_j+\alpha\cdot (y^{(i)}-h_{\bm \theta}({\bf x}^{(i)}))x_j^{(i)},\quad j=0,1,\ldots,n \end{aligned} θj:=θj+α⋅(y(i)−hθ(x(i)))xj(i),j=0,1,…,n(11)我们可以用矩阵形式表示为
θ : = θ + [ α ( y − y ^ ) T X ] T (12) \tag{12} {\bm \theta}:={\bm \theta}+[\alpha({\bf y}-\hat {\bf y})^{\rm T}{\bf X}]^{\rm T} θ:=θ+[α(y−y^)TX]T(12)其中 y ^ = [ y ^ 1 , y ^ 2 , … , y ^ m ] T \hat{\bf y}=[\hat y_1,\hat y_2,\ldots,\hat y_m]^{\rm T} y^=[y^1,y^2,…,y^m]T, y ^ i = h θ ( x ( i ) ) \hat { y}_i=h_{\bm \theta}({\bf x}^{(i)}) y^i=hθ(x(i))。