数据挖掘实践与我的想法之特征工程
从一个最近的天池数据挖掘比赛,记录部分特征工程实践内容。
比赛链接 商铺定位
本人渣渣,排名TOP21。
本博客采用二分类XGBOOST模型,同时涉及部分的多分类模型。重点介绍业务特征,对于一些科技特征,就私藏了。
简单分析
比赛数据给了三部分:用户历史纪录集、商场商铺数据集、测试集。
这里已经将前两个数据集合并,查看数据:
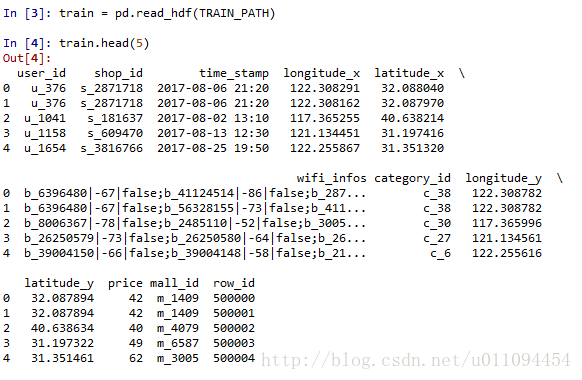
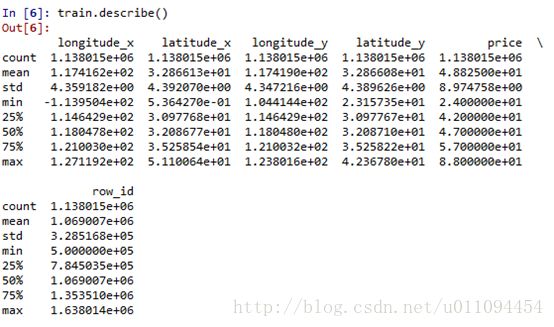
数据看上去只有100w,但后面特征提取一定会增加大量数据。抽取某个商场mall,做简单分析。
经纬度分析
对于定位,我们肯定先想到使用经纬度。由于商场可能楼层很高,于是我们先看下有多少店铺的经纬度是不重复的,

再查看部分商店每位顾客的分布,图来自比赛群共享,
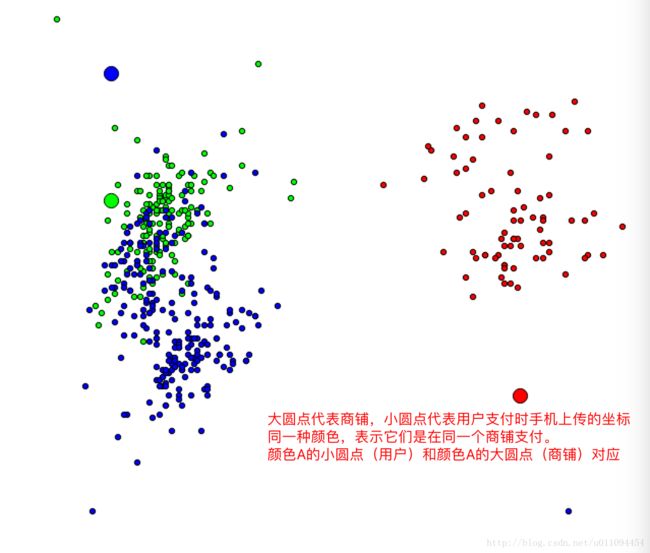
这两张图展示的用户位置和店铺位置相当清晰,似乎使用经纬度就可以做出基本的区分。
写一个利用弧度计算两个经纬度距离的函数,
#获得经纬度欧式距离#默认地球半径
R = 6378137
#用户行为发生位置与店铺位置的距离
def tcd_produceDistance(latitude1, longitude1,latitude2, longitude2):
radLat1 = np.radians(latitude1)
radLat2 = np.radians(latitude2)
a = radLat1-radLat2
b = np.radians(longitude1)-np.radians(longitude2)
return R*2*np.arcsin(np.sqrt(np.power(np.sin(a/2),2)+np.cos(
radLat1)*np.cos(radLat2)*np.power(np.sin(b/2),2)))统计用户与店铺的距离,这里拿一个商场来统计,
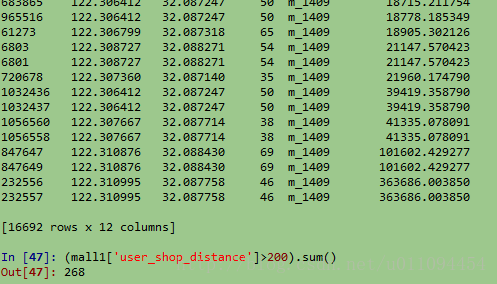
可以看到,有超过200条记录他距店铺的距离超过了200米,将这些距离全部转为200m,输出可以看到:
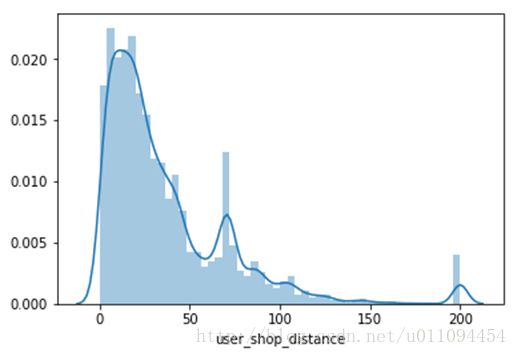
距离集中在0~50,实际超过100m的就在少数,统计也只有900个。不符合实际情况,是否需要删除呢?不,后面会将每个店铺的交易距离做聚类,并提取相关特征。
WiFi信息分析
从全部数据中可以看到,WiFi信息的格式为:
b_6396480|-67|false;b_41124514|-86|false;b_28723327|-90|false;
解释:以分号隔开的WIFI列表。对每个WIFI数据包含三项:b_6396480是脱敏后的bssid,-67是signal强重点内容度,数值越大表示信号越强,false表示当前用户没有连接此WIFI(true表示连接)。
以此写一个WiFi信息提取的方法,
def get_shop_wifi_bssid(mall):
#WiFi切片
result = []
for i in mall.index:
slist = mall.loc[i,'wifi_infos'].split(';')
for f in slist:
j = f.split('|')
j.append(mall.loc[i,'shop_id'])
j.append(mall.loc[i,'row_id'])
result.append(j)
result = pd.DataFrame(result,columns=['bssid','power','isconnect','shop_id','row_id'])WiFi信息的使用对每一位刚开始做比赛的同学都很迷茫,查找很多关于室内WiFi定位的资料,都是利用KNN、SVM、决策树等方法做的,论文提到其中KNN的做法效果最好,但对于这个比赛是否是这样呢?

这是提取出来的WiFi,这只是一条记录里一个商店拥有的WiFi信息,用groupby方法可以提取关于这个商店的所有WiFi信息,并“加工”成特征。看到上面的WiFi信息,很自然的一个思路是,是否有些WiFi是大型WiFi或是只出现一次的等的噪声WiFi呢?直接groupby查看下,

不仅可以知道这个商场WiFi连接最多店铺的只有20个,还可以看到有部分WiFi的路由器bssid是连续的,查阅资料可以知道商场的路由器并不是只有一个,是由多个路由器分布成的,于是商场在采购这些路由器时就可能是同意批次连续的号了。当然同一个店铺也可能有连续bssid的路由器。上面的信息就可以提取相当好的特征,而WiFi的特征提取远不止如此,这个比赛的分数就靠WiFi特征了。
选择模型
模型的选择决定了需要提取什么样的特征,这道题可以选择多分类,也可以选择二分类,还有比赛群里强大的三分类。
对于多分类来说,全部店铺有8700多个,WiFi数量更是爆炸,只能分mall进行。具体的多分类模型可以采用KNN、XGBOOST等,提取的特征当然是WiFi信息和经纬度信息了。比赛群里分享的XGBOOST多分类仅60行代码,过滤了出现20次以下的WiFi,剩下的WiFi与经纬度一起进行训练,得到了0.9072的高分。本人自己写的KNN远没有这么高。
本博客重点介绍二分类思想,因为二分类思想可以提取的特征实在是太多了。可以将多分类比作从出发地猜目的地在哪,而二分类是已经给出有可能的目的地,猜这个目的地是不是真实的,选择概率最大的。显而易见,多分类提取的特征只是出发地的,而二分类提取的特征是出发地和目的地都可以有,且还有更多两者相关联的特征。
多分类比较好理解,而二分类在这里是怎么实现的呢?

首先,真正的训练集是将训练集分为两部分的如图的下一部分,上一部分为下面真正的训练集提供样本和特征。这里的样本sample是指正负样本,负样本为真正的训练集里每条记录可能的目标(可以有很多个),正样本是指这条记录真正的目标;特征feature指该条记录里的“属性”:用户、经纬度、WiFi信息等经过加工联系得到的“新的属性”。这里真正的训练集是有0-1标签label的,代表是否是真的记录。
再用同样的方法在整个训练集里提取特征给测试集,这里的测试集代表了上面所说的“真正的训练集”,提取的样本和特征是在整个训练集里找。
于是可以得到如下的真正的训练集和测试集:
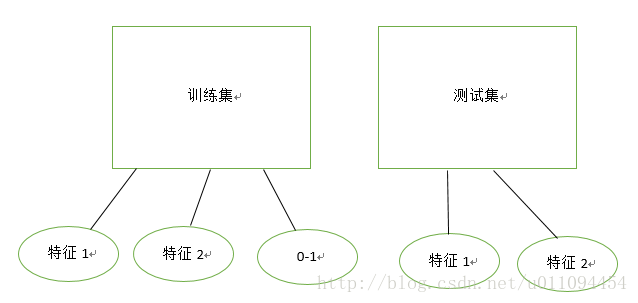
当然特征不可能这么点。这样就是我们所熟悉的二分类了,直接扔进模型里试试。
业务特征提取
这里说的业务特征也就是逻辑特征,个人解释为可以讲出道理的特征,如此条记录里WiFi的最大信号强度等,是不需要进过统计学方法如Log、Log1p等处理的,而对一般分类决策树的模型这样的处理方式也没有用处,但在多分类如KNN里还是需要对数据做一个标准化、归一化等。
特征提取部分是在样本选择之后进行的,样本选择可以是该条记录里的WiFi曾经连接过的所有商店、用户曾去过的所有商店等,这里不多赘述。
提取完负样本后得到训练集如下:

在复杂事物自身包含的多种矛盾中,每种矛盾所处的地位、对事物发展所起的作用是不同的,总有主次、重要非重要之分,其中必有一种矛盾与其它诸种矛盾相比较而言,处于支配地位,对事物发展起决定作用,这种矛盾就叫做主要矛盾。这就是唯物辩证法。
在这些未加工的特征属性中,按照重要性排序可以得到:
WiFi:是本次大赛的主题,当然是最重要的特征。研究统计WiFi特征,联系交叉进行提取,并从各个方面进行建模。(只用WiFi便可以得到高分)
商店:单单是商店,没什么特征可以提取,但是当商店与WiFi等的用户信息相结合,提取的特征是非常多的,在WiFi的基础上对其进行建模。
经纬度:是与WiFi信息差不多的性质,但是却并不比WiFi数据有效。可以从从微观角度建模。
时间:各种比赛中,时间都不会单独提取的,是与其他特征交叉组合的重要特征。
用户:在这里的用户信息是比较少的,但还是可以根据用户的不同行为,从微观、个性化角度进行建模。
一阶特征
一阶特征是指只从一个属性里找的特征,并没有与其他特征有交叉。声明:这些提取的特征不是全部都是“有效的”,但是却“应该”试一试。
该条记录特征
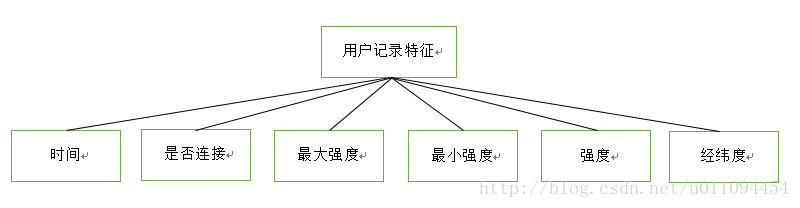
店铺特征
二阶交叉组合特征
在二阶特征以及以上的特征提取中,需要注意目标对象。在本题中,目标对象是shop_id,还有category_id与price也属于目标对象。源对象也可以是user_id、row_id、bssid等,从源对象出发来预测目标对象为“正”的概率时,需要提取的比例等的统计类特征应该是在”目标对象“在”源对象“中的所占的比例。一般很容易想到的都是”源对象“在”目标对象“中所占的比例,其实这样提取也是可以的,但在逻辑上变成了”目标对象“在预测”源对象“了,各中的逻辑需要慢慢体会,至于那个比较好还是要结合问题情况。如这样两个特征:
1.用户在这个商店历史记录中出现过的比例;
2.这个商店在用户所有去过的商店中所占的比例。
这两个对象就是相反的,前者以商店为中心,后者以用户为中心。
用户WiFi与店铺历史WiFi
用户WiFi与店铺历史WiFi这两者的交叉特征是非常重要的特征,这两者的联系也可以提取到很多特征,如图为提取的部分“有道理”的特征,图上是本人提取的特征,当然实际提取了很多,这里委实放不下。
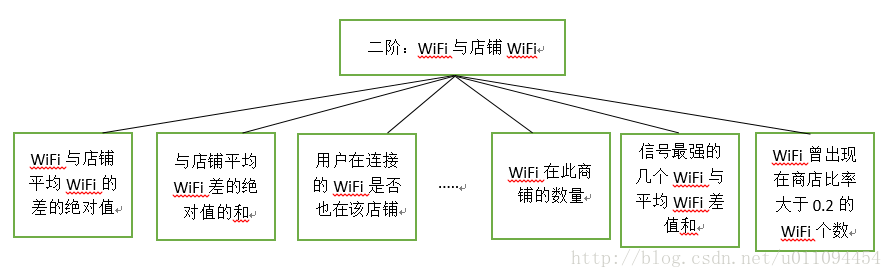
在思考WiFi与店铺的关系时,一定会想到WiFi的强度与这个WiFi在这个店铺的历史强度的关系,这个历史强度在多分类中可以直接使用所有的此WiFi历史强度,这么大数量的特征显然是不可取的,但不使用所有历史数据损失的信息相当大,也因此没有足够好的特征,在本道赛题是弱势的。
于是找到所有店铺历史WiFi的规律是找到主要矛盾的关键点。
基本店铺历史WiFi首先可以想到
1.平均WiFi、中位数WiFi、众数WiFi
2.WiFi在这个店铺出现过的次数与比率
3.每条历史纪录中WiFi的强度的排名
4.哪些WiFi曾经在这个店铺connect过由当前记录的WiFi信息与这些店铺历史WiFi的信息做“对比”。最自然的想到的特征肯定有
1.当前WiFi强度与对应店铺历史强度的差--记为wifi_nn
2.wifi_nn的和
3.当前所有WiFi中曾出现在这个店铺的个数
4.当前WiFi比率大于某个值的WiFi个数
5.当前WiFi是否连接过此店铺
6.当前连接的WiFi是否在此店铺也被连接过
等等这样子的特征貌似并没有把每个WiFi的等级划分出来,于是很久WiFi强度、历史强度、WiFi出现的次数或比率来给WiFi进行“等级划分”。在上面已经得到的基础特征上在进行特征提取:
1.根据当前WiFi强度排序的wifi_nn特征展开
2.根据当前WiFi强度排序的前几位WiFi_nn的和
3.根据店铺平均WiFi强度排序的wifi_nn特征展开
4.根据店铺平均WiFi强度排序的前几位WiFi_nn的和
5.当前WiFi强度排序位置(1-10)与历史WiFi强度排序的位置的平均值差的展开
6.每个WiFi的历史WiFi强度排序的位置展开下面是复赛第一名的部分用户WiFi与店铺历史WiFi特征:
1. wifi历史上出现过的总次数、候选shop在其中的占比
2. 在当前排序位置(如最强、第二强、第三强...)上wifi历史上出现过的总次数、候选shop在其中的占比
3. 连接的wifi出现的总次数、候选shop在其中的占比
(特征1、2,每条记录中的10个wifi由强到弱排列,可生成10个特征。)
4. wifi强度 - 候选shop的历史记录中该wifi的平均强度
5. wifi强度 - 候选shop的历史记录中该wifi的最小强度
6. wifi强度 - 候选shop的历史记录中该wifi的最大强度
(三个wifi强度差值特征,按照信号强度由强到弱排列,可生成10个特征)。最小最大值一直都是特征提取的重点,当前值与最大最小值之间的差更是值得尝试的特征。
下面是复赛第四名的部分用户WiFi与店铺历史WiFi特征:
1. 当前wifi序列的能量与历史商店平均能量的方差
2. 当前wifi序列的能量与历史商店平均能量的差值的标准差
3. 当前wifi序列的能量与历史商店平均能量的差值的均值
4. 当前wifi序列的能量与历史商店平均能量序列的cos相似度
5. 当前wifi序列中大于历史商店平均能量的数量
6. 当前wifi序列中大于历史商店平均能量的数量占当前wifi序列与历史商店wifi序列相同wifi个数的比例
7. 当前序列wifi存在在商店历史中的最小能量
8. 当前wifi序列中小于历史商店平均能量的数量
9. 当前wifi序列的能量与历史商店平均能量的带有权重的差值
10. 当前序列wifi的能量与历史商店出现频率大于0.5的wifi的平均能量的方差
11. 在result中每个row_id出现次数最多的10个wifi的历史在商店中的平均能量与当前序列的能量差
12. 在result中每个row_id出现次数最多的10个wifi的历史在商店中
13. wifi出现在当前序列且出现在商店历史中的个数
14. 当前wifi序列中小于历史商店最小能量的数量
15. 当前wifi序列的能量与商店历史wifi序列的最小能量的方差
16. 当前wifi序列中大于历史商店最小能量的数量
17. 当前wifi序列中大于历史商店最小能量的数量占相同数量的比例
18. 当前wifi序列与历史商店最大能量的方差
19. 当前wifi序列的能量与历史商店最大能量序列的cos相似度
20. 当前wifi序列的能量与历史商店最大能量的带有权重的差值
21. 当前wifi序列中大于历史商店最大能量的数量
22. 当前序列wifi的能量与历史商店出现频率大于0.5的wifi的最大能量的方差
23. result中每个row_id出现次数最多的10个wifi的历史在商店中的最大能量与当前序列的能量差
24. 当前序列中wifi能量大于历史上这个商店出现过的所有商店的能量的次数
25. 当前序列中wifi能量大于历史上这个商店出现过的所有商店的能量的次数除以当前序列wifi在历史上出现的次数
26. 当前序列中的wifi能量与历史上这个wifi出现过的最大能量的距离
27. 当前序列中的wifi能量与历史上这个wifi出现过的最大能量的平均距离
28. 当前序列中的wifi能量与历史上这个wifi出现过的最小能量的平均距离经纬度特征
解决用户WiFi与商店WiFi这个主要矛盾后,再来看看次要矛盾——经纬度。用户所在位置与商店位置也可以组成相当多的特征。
首先很自然就可以想到
1.用户和商店的欧式距离。同时统计所有用户在这个商店的距离,还可以得到
2.最大最小的距离、平均距离、中位数距离等。接着顺着这个思路又可以想到
3.用户的位置与这个历史平均距离的差距用户的位置与这个历史平均距离的差距,这个平均距离与店铺的经纬度两者在图形上是个弧,除去距离还应该想到店铺历史记录的平均经纬度或中位数经纬度是这个店铺的历史交易中心点,那么用户的位置与这个交易中心的距离也是可取的
4.用户与店铺交易中心的距离用户记录特征
在数据量比较少的情况下,这段特征表现可能不会太好,可能非常稀疏。但是本赛题复赛这段特征提高了几个百分点。
用户记录特征肯定是用户与店铺、店铺的某些属性之间的关系,很自然便可以找到这方面的特征:
1.用户去过此店铺的次数与占该用户总次数的比率
2.用户去过此类型店铺的次数与占该用户总次数的比率
3.用户去过此价格店铺的次数与占该用户总次数的比率三阶交叉特征
这里的对象其实只有用户与店铺两个,第三个对象是什么呢?不能忘记的重要组合特征就是“时间”!时间不仅可以用来聚类数据,最重要的还可以提取到重要的时间滑窗特征。举几个例子就可以明白什么叫做时间滑窗:
1.距离当前时间1、7、14、30天的商店热度
2.在每天不同时间段的商店热度
3.周末非周末的商店热度当然还有一些重要的三阶时间特征如:
1.用户上次在此商店购买过东西距现在的时间