使用RIR_Generator从近场音频产生远场音频|混响
这里介绍一种使用近场的干净的音频生成(模拟)远场音频的方法。GitHub项目地址:RIR_Generator。
只介绍方法,要了解原理的请参考项目里的rir_generator.pdf文档。
平台:linux matlab
- 首先把这个项目git clone到本地。
git clone https://github.com/ehabets/RIR-Generator.git
cd RIR-Generator
- 将cpp文件编译成matlab可执行的文件
由于算法的底层是用cpp实现的,不能直接用matlab调用,要先编译成可执行文件才行。幸运的是作者已经将编译matlab的代码准备好了。
方法是,在终端打开matlab,直接输入,或者直接自己在linux里打开matlab软件:
matlab
- 在matlab中cd到RIR-Generator/目录下(如果按照以上操作,当前目录就是),在matlab命令行输入以下代码并回车
mex rir_generator.cpp
即可得到rir_generator.mexa64文件,在matlab中可以直接调用这个文件。
(参考这里)
工具已经准备好了,现在来试一试这个工具的效果如何。
- 从近场音频产生远场音频
以example_1.m为例产生远场音频。
example_1.m的代码为
c = 340; % Sound velocity (m/s)
fs = 16000; % Sample frequency (samples/s)
r = [2 1.5 2]; % Receiver position [x y z] (m)
s = [2 3.5 2]; % Source position [x y z] (m)
L = [5 4 6]; % Room dimensions [x y z] (m)
beta = 0.4; % Reverberation time (s)
n = 4096; % Number of samples
h = rir_generator(c, fs, r, s, L, beta, n);
参数的解读请参考rir_generator.pdf文档的p11
修改一下代码,将干净的近场音频close_clean.wav生成远场音频。
c = 340; % Sound velocity (m/s)
fs = 16000; % Sample frequency (samples/s)
r = [2 1.5 2]; % Receiver position [x y z] (m)
s = [2 3.5 2]; % Source position [x y z] (m)
L = [5 4 6]; % Room dimensions [x y z] (m)
beta = 0.4; % Reverberation time (s)
n = 4096; % Number of samples
h = rir_generator(c, fs, r, s, L, beta, n); % 计算转换矩阵
close_clean_wav = audioread('close_clean.wav'); % 读取近场干净音频
far_field_wav = fftfilt(h, close_clean_wav); % 产生远场音频
audiowrite('far_field.wav', far_field_wav, 16000); % 保存为.wav文件
- 效果
近场音频:close_clean.wav

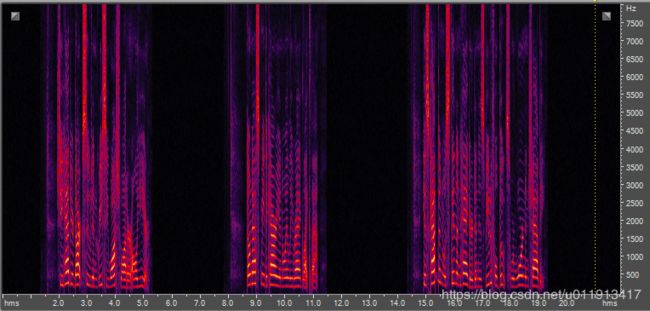
产生的远场音频:far_field.wav


为了对比,我将原近场音频进行复制压缩,和生成的远场音频进行对比。
原始音频幅值压缩后:

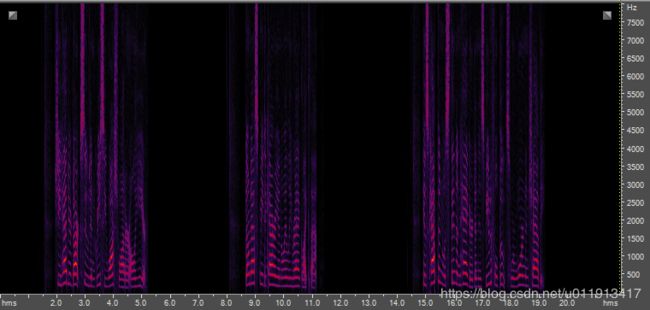
从频谱上看,用耳朵直接听,都可以感受到声音是远场的,包含了混响成分。
当训练数据不够多时,可以用这种方法进行数据增广,或者当训练样本为近场,测试样本包含远场的时候,也可以这样扩增远场训练集。
致谢
非常感谢原作者提供的宝贵资料,分享给更多人。原文链接为:
https://blog.csdn.net/LCCFlccf/article/details/100741703#commentBox