Q-学习:强化学习
原文地址:http://mnemstudio.org/path-finding-q-learning-tutorial.htm
这篇教程通过简单且易于理解的实例介绍了Q-学习的概念知识,例子描述了一个智能体通过非监督学习的方法对未知的环境进行学习。
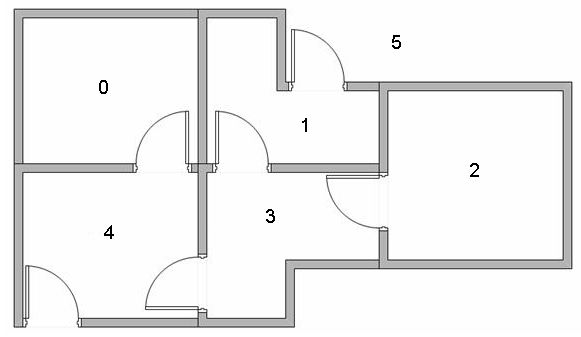
假设我们的楼层内共有5个房间,房间之间通过一道门相连,正如下图所示。我们将房间编号为房间0到房间4,楼层的外部可以被看作是一间大房间,编号为5。注意到房间1和房间4可以直接通到房间5。
假设我们的楼层内共有5个房间,房间之间通过一道门相连,正如下图所示。我们将房间编号为房间0到房间4,楼层的外部可以被看作是一间大房间,编号为5。注意到房间1和房间4可以直接通到房间5。
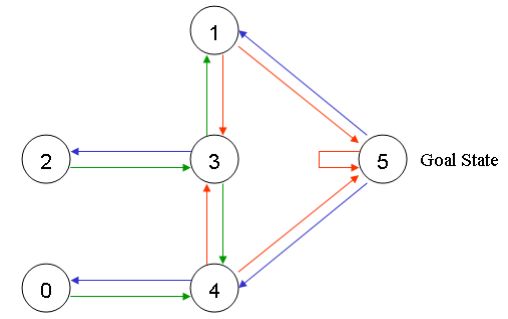
我们可以用图来表示上述的房间,将每一个房间看作是一个节点,每一道门看作是一条边(链路)。
在这个例子中,我们可能在任意一间房间中放置一个智能体(机器人),并期望该智能体能够从该房间开始走出这栋楼(可以认为是我们的目标房间)。换句话说,智能体的目的地是房间5。为了设置这间房间作为目标,我们为每一道门(节点之间的边)赋予一个奖励值。能够直接通到目标房间的门赋予一及时奖励值100,而其他的未与目标房间直接相连的门赋予奖励值0。因为每一道门都有两个方向,因此,每一道门在图中将描述为两个箭头。如下所示:
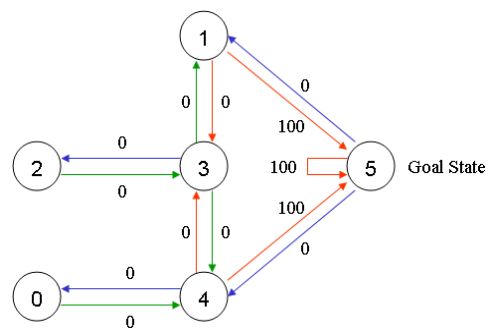
当然,从房间5到房间5的奖励值也是100,其他所有直接通到目标房间5的奖励值也是100。在Q-学习中,学习的目标是达到具有最高奖励值的状态,因此,如果智能体到底了目标位置,它将永远的留在那儿。这种类型的目标被称为“吸收目标”。
想象我们的智能体是一个不会说话的虚拟机器人,但是它可以从经验中学习。智能体能够从一个房间到底另外一个房间,但是它对周围的环境一无所知,它不知道怎么走能够通到楼层外面(房间5)。
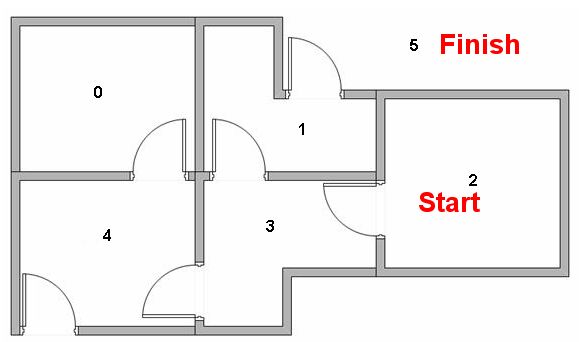
假设我们想对智能体从某一个房间中撤退的过程进行建模,现在,我们假设智能体在房间2内,我们希望智能体通过学习到达房间5。
Q-学习中的术语包括状态(state)和动作(action)。
我们将每一个房间称为一个“状态”,智能体从一个房间到另一个房间的移动过程称为“动作”。在我们的示意图中,状态被描述为节点,动作被描述成箭头。
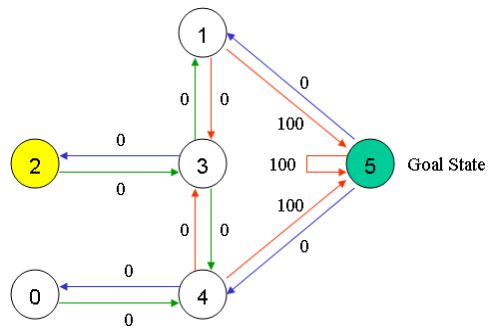
假设智能体处于状态2,那么,它从状态2能够直接到达状态3,因为状态2和状态3相连。然而,智能体从状态2不能直接到达状态1,因为在房间2和房间1之间没有直接相通的门,也即没有箭头存在。从状态3,智能体要么到达状态1,要么到达状态4,抑或着返回到状态2。如果智能体处于状态4,那么它有3周可能的动作,即到达状态0,、5或3。如果智能体在状态1,它能够到达状态5或者状态3。从状态0,它只能到达状态4。
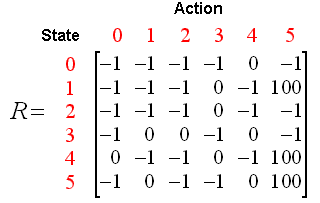
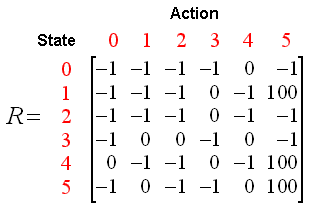
我们可以将状态图和即时奖励值填入到下面的奖励表中,即矩阵R:
(表中的-1代表空值,表示节点之间无边相连)
现在,我们再增加一个相似的矩阵Q,代表智能体从经验中所学到的知识。矩阵Q的行代表智能体当前的状态,列代表到达下一个状态的可能的动作。
因为智能体在最初对环境一无所知,因此矩阵Q被初始化为0。在这个例子中,为了阐述方便,我们假设状态的数量是已知的(设为6)。如果我们不知道有多少状态时,矩阵Q在最初被设为只有一个元素。如果新的状态一旦被发现,对矩阵Q增加新的行和新的列非常简单。
Q-学习的转换规则非常简单,为下面的式子:
Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])
依据这个公式,矩阵Q中的一个元素值就等于矩阵R中相应元素的值与学习变量Gamma乘以到达下一个状态的所有可能动作的最大奖励值的总和。
我们虚拟的智能体将从经验中学习,不需要教师指导信号(这被称为非监督学习)。智能体将从一个状态到另一个状态进行探索,直到它到达目标状态。我们将每一次探索作为一次经历,每一次经历包括智能体从初始状态到达目标状态的过程。每次智能体到达了目标状态,程序将会转向下一次探索。
Q-学习的转换规则非常简单,为下面的式子:
Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])
依据这个公式,矩阵Q中的一个元素值就等于矩阵R中相应元素的值与学习变量Gamma乘以到达下一个状态的所有可能动作的最大奖励值的总和。
我们虚拟的智能体将从经验中学习,不需要教师指导信号(这被称为非监督学习)。智能体将从一个状态到另一个状态进行探索,直到它到达目标状态。我们将每一次探索作为一次经历,每一次经历包括智能体从初始状态到达目标状态的过程。每次智能体到达了目标状态,程序将会转向下一次探索。
Q-学习算法的计算过程如下:
1、设置参数Gamma,以及矩阵R中的环境奖励值;
2、初始化Q矩阵为0;
3、对每一次经历:
随机选择一个状态;
Do while 目标状态未到达
对当前状态的所有可能的动作中,选择一个可能的动作;
使用这个可能的动作,到达下一个状态;
对下一个状态,基于其所有可能的动作,获得最大的Q值;
计算:Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])
设置下一个状态作为当前状态;
End For
1、设置参数Gamma,以及矩阵R中的环境奖励值;
2、初始化Q矩阵为0;
3、对每一次经历:
随机选择一个状态;
Do while 目标状态未到达
对当前状态的所有可能的动作中,选择一个可能的动作;
使用这个可能的动作,到达下一个状态;
对下一个状态,基于其所有可能的动作,获得最大的Q值;
计算:Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])
设置下一个状态作为当前状态;
End For
智能体利用上述的算法从经验中学习,每一次经历等价于一次训练。在每一次训练中,智能体对环境进行探索(用矩阵R表示),并且其一旦到达目标状态,就得到奖励值。训练的目的是增强智能体的大脑,用矩阵Q表示。越多的训练结果将导致更优的矩阵Q。在这种情况下,如果矩阵Q已经被增强,那么智能体就不会四处盲目的探索,而是会找到最快的路线到达目标状态。
参数Gamma的取值在0到1之间(0<=Gamma<=1),如果Gamma越接近于0,智能体更趋向于仅仅考虑即时奖励;如果Gamma更接近于1,智能体将以更大的权重考虑未来的奖励,更愿意将奖励延迟。
为了使用矩阵Q,智能体仅仅简单地跟踪从起始状态到目标状态的状态序列,这个算法在矩阵Q中,为当前状态寻找到具有最高奖励值的动作。
参数Gamma的取值在0到1之间(0<=Gamma<=1),如果Gamma越接近于0,智能体更趋向于仅仅考虑即时奖励;如果Gamma更接近于1,智能体将以更大的权重考虑未来的奖励,更愿意将奖励延迟。
为了使用矩阵Q,智能体仅仅简单地跟踪从起始状态到目标状态的状态序列,这个算法在矩阵Q中,为当前状态寻找到具有最高奖励值的动作。
利用矩阵Q的算法如下:
1、设置当前状态=初始状态;
2、从当前状态开始,寻找具有最高Q值的动作;
3、设置当前状态=下一个状态;
4、重复步骤2和3,直到当前状态=目标状态。
上述的算法将返回从初始状态到目标状态的状态序列。
为了理解Q-学习算法是怎样工作的,我们通过分析少量的例子进行分析。
我们设置学习率Gamma等于0.8,初始的状态是房间1。
初始的矩阵Q作为一个零矩阵,如下:
我们设置学习率Gamma等于0.8,初始的状态是房间1。
初始的矩阵Q作为一个零矩阵,如下:

观察R矩阵的第二行(状态1),对状态1来说,存在两个可能的动作:到达状态3,或者到达状态5。通过随机选择,我们选择到达状态5。
现在,让我们想象如果我们的智能体到达了状态5,将会发生什么?观察R矩阵的第六行,有3个可能的动作,到达状态1,4或者5。
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100
由于矩阵Q此时依然被初始化为0,Q(5, 1), Q(5, 4), Q(5, 5)全部是0,因此,Q(1, 5)的结果是100,因为即时奖励R(1,5)等于100。
下一个状态5现在变成了当前状态,因为状态5是目标状态,因此我们已经完成了一次尝试。我们的智能体的大脑中现在包含了一个更新后的Q矩阵。
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100
由于矩阵Q此时依然被初始化为0,Q(5, 1), Q(5, 4), Q(5, 5)全部是0,因此,Q(1, 5)的结果是100,因为即时奖励R(1,5)等于100。
下一个状态5现在变成了当前状态,因为状态5是目标状态,因此我们已经完成了一次尝试。我们的智能体的大脑中现在包含了一个更新后的Q矩阵。

对于下一次训练,我们随机选择一个初始状态,这一次,我们选择状态3作为我们的初始状态。
观察R矩阵的第4行,有3个可能的动作,到达状态1,2和4。我们随机选择到达状态1作为当前状态的动作。
现在,我们想象我们在状态1,观察矩阵R的第2行,具有2个可能的动作:到达状态3或者状态5。现在我们计算Q值:
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
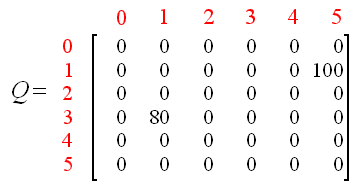
Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 2), Q(1, 5)] = 0 + 0.8 * Max(0, 100) = 80
我们使用上一次尝试中更新的矩阵Q得到:Q(1, 3) = 0 以及 Q(1, 5) = 100。因此,计算的结果是Q(3,1)=80,因为奖励值为0。现在,矩阵Q变为:
观察R矩阵的第4行,有3个可能的动作,到达状态1,2和4。我们随机选择到达状态1作为当前状态的动作。
现在,我们想象我们在状态1,观察矩阵R的第2行,具有2个可能的动作:到达状态3或者状态5。现在我们计算Q值:
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 2), Q(1, 5)] = 0 + 0.8 * Max(0, 100) = 80
我们使用上一次尝试中更新的矩阵Q得到:Q(1, 3) = 0 以及 Q(1, 5) = 100。因此,计算的结果是Q(3,1)=80,因为奖励值为0。现在,矩阵Q变为:
下一个状态1变成了当前状态,我们重复Q学习算法中的内部循环过程,因为状态1不是目标状态。
因此,我们从当前状态1开始一次新的循环,此时有2个可能的动作:到达状态3或者状态5。我们幸运地选择到达了状态5。
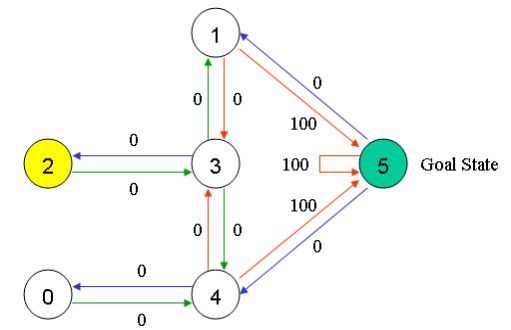
因此,我们从当前状态1开始一次新的循环,此时有2个可能的动作:到达状态3或者状态5。我们幸运地选择到达了状态5。
现在,想象我们处于状态5,有3个可能的动作:到达状态1,4或5。我们计算Q值如下:
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100
更新后的矩阵Q中,Q(5, 1), Q(5, 4), Q(5, 5)依然是0,故Q(1, 5)的值是100,因为即时奖励R(5,1)是100,这并没有改变矩阵Q。
因为状态5是目标状态,我们完成了这次尝试。我们的智能体大脑中包含的矩阵Q更新为如下所示:
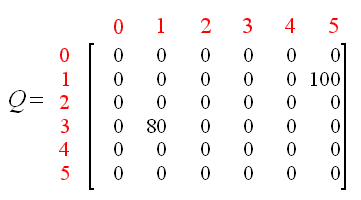
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100
更新后的矩阵Q中,Q(5, 1), Q(5, 4), Q(5, 5)依然是0,故Q(1, 5)的值是100,因为即时奖励R(5,1)是100,这并没有改变矩阵Q。
因为状态5是目标状态,我们完成了这次尝试。我们的智能体大脑中包含的矩阵Q更新为如下所示:
如果我们的智能体通过多次的经历学到了更多的知识,Q矩阵中的值会达到一收敛状态,如下:

通过对Q中所有的非零值缩小一定的百分比,可以对其进行标准化,结果如下:

一旦矩阵Q接近于收敛状态,我们就知道智能体已经学习到了到达目标状态的最佳路径。
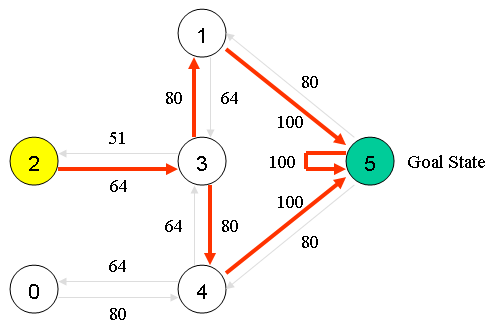
例如,从初始状态2,智能体在矩阵Q的指导下进行移动:
在状态2时,由矩阵Q中最大的值可知下一个动作应该是到达状态3;
在状态3时,矩阵Q给出的建议是到达状态1或者4,我们任意选择,假设选择了到达状态1;
在状态1时,矩阵Q建议到达状态5;
因此,智能体的移动序列是2-3-1-5。
在状态2时,由矩阵Q中最大的值可知下一个动作应该是到达状态3;
在状态3时,矩阵Q给出的建议是到达状态1或者4,我们任意选择,假设选择了到达状态1;
在状态1时,矩阵Q建议到达状态5;
因此,智能体的移动序列是2-3-1-5。