图像美化论文笔记: Deep Photo Enhancer:Unpaired Learning for Image Enhancement from Photographs with GANs
论文地址:Deep Photo Enhancer:Unpaired Learning for Image Enhancement from Photographs with GANs
来源: 2018 CVPR
在线demo:http://www.cmlab.csie.ntu.edu.tw/project/Deep-Photo-Enhancer/
GitHub:https://github.com/nothinglo/Deep-Photo-Enhancer
任务:image enhancement 图像增强
方法:将这一问题作为 image to image translation任务,使用改进的two-way GAN 实现unpaid训练集进行训练
创新:global U-Net + A-WGAN
引言:
文章将图像增强作为了一种图像翻译来进行处理,使用GAN做图像翻译,就我而言印象深刻的可能就是17年的两篇文章:pix2pix 和 cycGAN 。一个是paired,一个是unpaired,并且文章中有很多有趣的应用。
基于这两篇文章,在图像增强上也出现了大量的采用GAN来进行成对和非成对数据的工作。
而这篇DPE是将GAN应用到图像增强上。大的方向也是不成对的数据集,进行训练,来解决成对数据集收集的困难这一问题。
数据:
Paired:
自构建数据集: 如果自己构建数据集对差的图片进行一张张ps处理是不现实的,可以采取【将大量好的图片使用传统图像处理方法不同程度变坏】的方式
公开数据集: ① MIT-Adobe FiveK Dataset
② DSLR Photo Enhancement Dataset
Unpaired:
不要求一一对应,是域与域的构建。对于差的图片,当然是你要改善的一些图片。而好的图片可以在Flickr上面根据主题查找一些好看的图片。
文章具体细节:
这部分介绍将主要针对2-way gan,文中对1-way gan的介绍也是想引出后面的介绍
1. 整体网络结构和网络信息流向
文中所使用的改变的两阶段生成对抗网络和Cycgan相似,但是在细节上还有不同

两阶段的GAN保持着两个方向的映射关系,从x->y和y->x 。具体网络信息流向表达如下:

2.具体网络结构
在GAN中生成器一直扮演着重要的角色,因为它将充当最终的美化转化器 ,G的具体结构如下图所示,G网络是基于U-Net进行设计的,U-Net最早在生物医学图像分割领域被提出,但是在之后的许多任务都表现出了较强的性能。然而,U-Net可能不包括全局特征的提取。而全局特征可以揭示高级信息,例如场景类别、主体类别或整体照明条件等,这些信息可用于各个像素以确定其局部调整。对于图像增强而言,这些信息是十分重要的。所以将全局特征添加到了U-Net中,全局特征提取通道与U-Net结构共享前五层的卷积-激活-批归一化层,得到第五层的特征图后,全局特征提取通道进一步将特征图缩小然后通过全连接层。为了将全连接层提取特征图与U-Net低层特征相融合,使用特征拷贝的方式将1*1*128的特征图复制多份并将其与U-Net进行连接。网络除了U-Net具有的特征保留性的U前后跳跃连接,还参考了残差学习的思想,G仅学习输入图片与标签图片的差异。G结构中全局特征提取通道的设计是十分巧妙的,并不需要一个额外的监督网络训练而是使用了U-Net本身来编码隐式特征向量。对于D实质上是一个二分类的网络,由几层卷积构成,具体结构见下图,其主要作用是进行真假图片的判断。

大多数双向GAN对网络中的Gx和Gx' 使用相同的生成器,因为它们都将来自域X的输入映射到域 Y,对于Gy 和Gy '也是如此。然而,两者的输入可能具有不同的分布特征,生成器最好适应它们自己的输入。因此,文中的生成器共享除批归一化层之外的所有层和参数。每个生成器都有自己的批归一化层,以便更好地适应其自身输入的特性。
3.损失函数和优化方式
众所周知,自从2014年被提出,GAN虽然惊艳四座,但是其训练困难、生成样本缺乏多样性等问题就一直被人诟病。从DCGAN依靠枚举实验仔细的设计G和D的网络结构到Wasserstein GAN使用Lipschitz连续近似地最小化Wasserstein距离,大量的学者都在为GAN的训练优化进行研究探索。而本文所采用的是一种A-WGAN的方式,WGAN满足Lipschitz连续的方式是使用权重裁剪的方式,具体做法为当D的参数每更新一次就进行参数值大小的判断,如若其超出所定域值,就将超出的参数截取到阈值范围内保证训练过程中所有的参数有界。然而这种方式会使权重分布在阈值范围的两侧,极易导致网络梯度消失或者梯度爆炸。针对这一情况,WGAN-GP通过添加梯度惩罚项损失来进行直接约束D的梯度范围。然而对于惩罚项参数 的选择是一个难题,如果 太小,则无法保证Lipschitz约束。反之,如果 太大,则网络的收敛速度可能是极其缓慢的。因为本文将使用A-WGAN的方式,A-WGAN是在WGAN-GP的基础上进行自适应性地调节 的。
基于上述的介绍,可以容易地定义GAN的损失函数,网络的目标包括以下几个损失。第一个是内容映射损失 ,其要求变换图像的内容y'应该与输入图像x相似。由于是双向GAN,还有从y 到x'的映射对应损失。具体公式如下:
![]()
第二个损失是两阶段GAN的一致性损失C下:
![]()
还有生成对抗网络的对抗损失:

训练判别器D时,梯度惩罚项P将被添加到损失中,其具体定义如下:
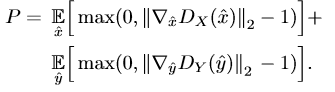
上述这一项确保了Lipschitz连续,为了近似最小化Wasserstein距离。因此对于G和D分别用如下公式进行优化。
G优化公式:

D优化公式:
![]()
4.评估方式和实验结果
文中使用了两种全参考的客观评价指标PSNR和SSIM来对有label的图片进行评价。
PSNR峰值信噪比:是一种评价图像的客观标准,PSNR的本质和MSE相同,是MSE的对数表示。peak就是指8bits表示的最大值255,MSE是均方误差。PSNR以dB为单位,PSNR值越大表示图像失真越小。具体公式如下(源于维基百科):

SSIM结构相似性:是一种用以衡量两张数位影像相似程度的指标。当两张影像其中一张为无失真影像,另一张为失真后的影像,二者的结构相似性可以看成是失真影像的影像品质衡量指标。相较于传统所使用的影像品质衡量指标,像是峰值信噪比,结构相似性在影像品质的衡量上更能符合人眼对影像品质的判断。具体公式定义如下(源于维基百科):

文中使用两种方法评估了 MIT-Adobe 5K dataset 数据集测试结果,与以往结果对比,所提模型有良好的效果。
然而对于图像美化而言,只是使用客观的方式来评价是单一且有偏差的。为此往往需要人工的参与,一般文章都会采用众包的方式,本文中也通过用户使用报告来验证了模型的效果。
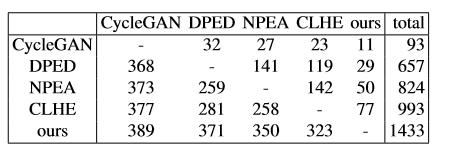
通过上述矩阵也可以看出,400张测试图片中,与其他4种模型相比,文中所提模型都是用户认可率最高的。
5.结果展示
6. 风险与隐患
1)如果输入非常暗并且包含大量噪声,模型可能放大噪声。
2)由于用于unpaired 训练的HDR图像是Tone Mapping而来,因此模型图片可能会出现从一些图像的色调映射得到一些halo artifacts的现象 。
3)对于unpaired的网络训练,训练集的domain的选择很重要,针对文章中选择的更外景,更多的蓝天、大海。如果我们不加选择的使用,输入的图片会出现不明所以的蓝。(可在在线demo测试图片)
7.代码与在线demo
作者公开了在线demo上的代码以及权重文件,提供了以下四种模型:
HDR(最大输出图片大小2048)
HDR (最大输出图片大小512)
MIT-ADOBE 5K(unpaired maxL 512)
MIT-ADOBE 5K(paired maxL 512)
在我理解前三种模型都是基于2 way gan训练得到的,其中前两个HDR的 是域MIT数据到在Flickr寻找的HDR图片的美化映射过程,更改了图片输出大小。MIT-ADOBE 5K(unpaired maxL 512)也是2 way gan训练得到的,是原图到专家Cps图之间的美化映射。而MIT-ADOBE 5K(paired maxL 512)是一对一对的对应数据输入,使用的是文章中提出的生成器训练而得。
自己训练网络的时候,在网上下载的MIT-ADOBE 5K数据集使用Lightroom进行导出。大小:最长边512 格式:SRGB
更多具体的细节可以仔细阅读作者公布的代码以及Issues,作者虽然说自己的代码没时间整理很ugly 但是在阅读的时候还是可以学到很多不一样的想法,比如在unet的上采样过程中作者采用的是图像插值扩增的方式,处理全连接地方作者采用的是卷积代替全连接,在测试过程中可以通过将卷积变为空洞卷积来处理任意大小的输入输出等等。