Android虚拟机章节——1.3.2 ELF的加载和动态链接过程
静态库和动态链接库有什么区别呢?
Wiki上对静态库的释义如下所示:
“In computer science, a static library or statically-linked library is a set of routines, external functions and variables which are resolved in a caller at compile-time and copied into a target application by a compiler, linker, or binder, producing an object file and a stand-alone executable”
静态链接库的特点是会在程序的编译链接阶段就完成函数和变量的地址解析工作,并使之成为可执行程序中不可分割的一部分。这种处理手段在某种程度上也可以有效的实现代码的重复利用,使得编写程序不需要每次都从零开始,因而在程序开发的早期得到了广泛的应用——甚至是当时技术条件下的唯一选择。但是它的缺点也是比较明显的,即可执行程序的体积会随着静态链接库的增加而不断变大。另外,如果操作系统中有多个可执行程序都用到了同一个静态库A,按照静态链接的做法就需要把A分别打包进所有程序中——这显然是一种资源浪费。
与静态链接库相对应的,便是动态链接库的处理方式,我们再来看下它的定义:
“In computing, a dynamic linker is the part of an operating system that loads and links the shared libraries needed by an executable when it is executed (at “run time”), by copying the content of libraries from persistent storage to RAM, and filling jump tables and relocating pointers.”
动态链接库有如下几个核心特点:
动态链接库不需要在编译时就被打包到可执行程序中,而是等到后者在运行阶段再实现动态的加载和重定位
动态链接库在被加载到内存中之后,操作系统需要为它执行动态链接操作。值得一提的是,有一些参考资料会把这里的链接称为“动态链接”,而将前述编译阶段的链接叫做“静态链接”;而且静态链接中也会有Relocation(Link Time Relocation),只是和动态链接中的重定位(Load Time Relocation)所针对的对象和处理过程存在差异。换句话说,只要涉及到多个文件之间的链接,通常都需要重定位。只不过静态链接发生在编译阶段,而动态链接则发生在运行阶段。这些概念都很容易搞混淆,提醒大家注意区分。
实际的动态链接过程是比较复杂的,例如需要链接器的介入(链接器通常也是一个ELF文件,因而存在“蛋生鸡,鸡生蛋”的问题,解决类似问题的办法通常被称为“BootStrap”。这其中还有很多有趣的细节,有兴趣的读者可以自行查阅相关资料),需要重定位,需要有效的机制来管理所有的动态符号等等。
接下来我们仍以之前的求和程序为例,进一步讲解动态链接库的工作原理。
/*main.c*/
#include “stdio.h”
void main()
{
add(1,2);
printf(“This is an example”);
}
int add(int value1, int value2)
{
return value1+value2;
}在这个程序中,add函数是定义在main.c中的,因而它的地址是已知的;而printf函数则由C库提供,属于“外部函数”,所以它在编译时并不会被打包到“求和”小程序中。等到“求和”程序在机器上真正运行起来后,操作系统会把它需要的动态链接库从磁盘(或其它存储介质)加载到内存中,然后解析出(如果是启用了延时解析的话,情况会有所不同)所有它引用的外部函数的真实地址,并保证可执行程序可以正确指向这些外部函数。
那么动态链接的这些操作是在什么时候执行的呢?由前一小节的分析大家应该知道,ELF头文件中有一项代表的是程序的入口地址,即e_entry。它在求和程序中对应的具体值是:

ELF可执行程序在运行过程中的入口地址一定是e_entry吗?这个问题可以从Linux Kernel如何启动ELF程序中找到答案。当我们需要运行一个ELF程序时,内核在经过一系列操作后会调用do_execve——这个函数最终又会利用load_elf_binary来完成ELF文件的加载和解析(Linux支持多种可执行文件格式,由一个linux_binfmt结构体表示,其中包含的load_binary成员变量指向可执行文件具体的加载函数)。
函数load_elf_binary很长,我们来分段阅读:
static int load_elf_binary(struct linux_binprm *bprm, struct pt_regs *regs)
{
…
/* 开始处理头文件信息 */
if (loc->elf_ex.e_phentsize != sizeof(struct elf_phdr))
goto out;
if (loc->elf_ex.e_phnum < 1 ||
loc->elf_ex.e_phnum > 65536U / sizeof(struct elf_phdr))
goto out;
size = loc->elf_ex.e_phnum * sizeof(struct elf_phdr);
retval = -ENOMEM;
elf_phdata = kmalloc(size, GFP_KERNEL);
if (!elf_phdata)
goto out;变量loc保存的是ELF文件的头文件信息。上述代码段中,e_phnum代表的是Program Header Table的数量; e_phentsize则代表一个Program Header所占的空间大小。因为PHT区段对于可执行程序来说是必不可少的,所以在数量上一定是>1(并且<65536)的。
…
for (i = 0; i < loc->elf_ex.e_phnum; i++) {
if (elf_ppnt->p_type == PT_INTERP) {…
retval = -ENOMEM;
elf_interpreter = kmalloc(elf_ppnt->p_filesz,
GFP_KERNEL);
if (!elf_interpreter)
goto out_free_ph;
retval = kernel_read(bprm->file, elf_ppnt->p_offset,
elf_interpreter,
elf_ppnt->p_filesz);
…
interpreter = open_exec(elf_interpreter);
…
loc->interp_elf_ex = *((struct elfhdr *)bprm->buf);
break;
}
elf_ppnt++;
}上述这个for循环是整个函数的关键点之一,它的目标是通过遍历所有Program Header来查找到Interpreter,即通常所说的“解释器”段。一旦找到,我们就可以把其中的内容通过kernel_read读取到elf_ppnt->p_offset所指示的地址空间中了。
ELF文件格式有一个名为“.interp”的Section,用于指示上述的链接器的位置。例如下面是针对“求和”小程序执行“readelf – S”命令所得到的信息,大家注意看第2个区段:
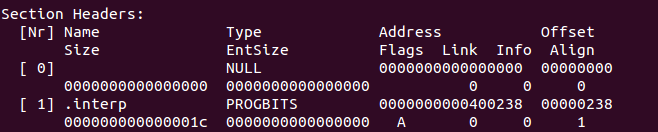
由“.interp”区段的Offset可知它的偏移量为00000238,我们来看下这个地址下保存的数据:

可见求和程序所使用的链接器的名称为“/lib64/ld-linux-x86-64.so.2”(这个链接器虽然表面上看是一个so文件,但事实上也是一个可执行程序),它在文件系统中的位置如下所示:
需要特别说明的是,我们的求和程序是在Linux平台下所做的实验。Android系统中的Linker与之大同小异,如下所示:
![]()
在Android系统中,可执行程序通常会被存储在/system/bin/目录下,其中就包括了我们关心的Linker。
我们再回到load_elf_binary函数,看下系统会利用interpreter做些什么工作:
if (elf_interpreter) {
retval = -ELIBBAD;
/* Not an ELF interpreter */
if (memcmp(loc->interp_elf_ex.e_ident, ELFMAG, SELFMAG) != 0)
goto out_free_dentry;
/* Verify the interpreter has a valid arch */
if (!elf_check_arch(&loc->interp_elf_ex))
goto out_free_dentry;
}首先需要验证interpreter的合法性,包括Magic Number是否正确;机器平台架构是否有效等等。
if (elf_interpreter) {
unsigned long uninitialized_var(interp_map_addr);
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias);
…
} else {
elf_entry = loc->elf_ex.e_entry;
if (BAD_ADDR(elf_entry)) {
force_sig(SIGSEGV, current);
retval = -EINVAL;
goto out_free_dentry;
}
}上述这段代码是决定ELF入口地址的关键。它的处理逻辑概况起来就是:如果interpreter区段存在,那么这个ELF文件的入口地址就是load_elf_interp函数的返回值;否则就仍然采用ELF头文件信息中指定的e_entry。换句话说,ELF程序真正的入口地址取决于它在执行过程中是否需要解释器——如果答案是肯定的,那么入口就在解释器中;否则使用默认的e_entry。
理解了ELF的入口地址如何确定后,接下来我们再用nm命令分析函数符号(特别是printf这类外部函数)信息:

不难发现,对于main这种内部函数而言,它的地址是预先就确定的;而printf则不一样,它只是被标志为”printf@@GLIBC_2.2.5”,并没有分配具体的地址值。大家可能会有疑问,可执行程序在运行时怎么知道要加载哪些动态库呢?这些信息事实上是由.dynamic区段(.dynamic有点类似于“大总管”,它包含了所有与动态链接相关的信息)提供的。譬如从下面图例(readelf –d命令)中可以看出这个可执行程序依赖于libc动态库(NEEDED类型),系统根据“这条线索”很容易就能判断出ELF在运行时所需要加载的动态链接库了。

有了上述知识点的铺垫后,我们现在可以给出动态链接库相关的处理过程了(以求和程序为例):
在编译阶段,求和程序经历了预编译、编译、汇编及链接操作后,最终形成一个ELF可执行程序。同时求和程序所依赖的动态库会被记录到.dynamic区段中;加载动态库所需的Linker由.interp来指示。
当求和程序运行起来以后,系统首先会通过.interp区段找到链接器的绝对路径,然后将控制权交给它(因为求和小程序使用到了动态链接库,所以入口地址在Linker中)
Linker负责解析.dynamic中的记录,得出求和程序依赖的所有动态链接库,以及它们又依赖于哪些其它的动态库,以此类推。因为.dynamic中并不会指定动态库的绝对路径,所以这还涉及到搜索目录的设置问题,具体细节大家可以自行查阅相关资料了解详情
动态链接库加载完成后,它们所包含的export函数在内存中的地址就可以确定下来了。Linker通过预设机制(如GOT/PLT)来保证求和程序中引用到外部函数的地方可以正常工作,即完成Dynamic Relocation
Dynamic Relocation在设计时有很多需要考量的因素,例如:
(1) 链接器如何知道可执行程序中有哪些需要重定位的对象?
(2) 在没有重定位以前,这些被引用对象的地址如何表示?
(3) 如何保证在不修改代码段的情况下完成Relocation?(GOT表的作用)
(4) 如何等到动态对象被第一次访问时才去做解析操作,从而提高程序的启动速度?(PLT表的作用)
对于第1个问题,ELF专门指定了一些特殊的Section来做解答,如下所示:
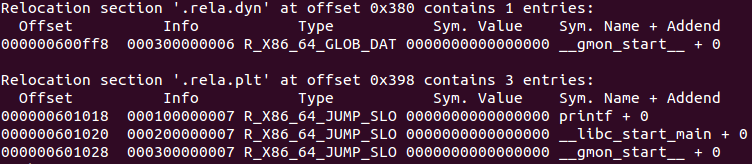
ELF动态链接库中以”.rela”开头的Section描述的是可重定位相关的信息。比如上面的”.rela.dyn”和”.rela.plt”分别表示需要被重定位的数据对象(此时被修正的位置在”.got”和数据段中)和函数对象(此时被修正的位置在”.got.plt”中)。这一点和静态链接时的做法类似,它会有名为”.rel.text”和”.rel.data”的段来分别保存代码和数据段的重定位信息。另外,上图中除printf之外还有一些由编译器自己产生的特殊符号,不过这些并不会影响我们的分析,可以直接略过。
这样子链接器就可以清楚地知道自己的服务对象是谁了。确定了这一点以后,链接器接下来要回答的是,它采用什么方式来为这些对象服务才是最合理的呢?大家可能会在第一时间想到:可以在编译阶段只给外部对象分配一个临时地址,然后再在动态重定位时将这些临时地址替换成真实地址。这种方案理论上是可行的,但对于动态链接的场景来说并非最佳方案。试想一下,动态链接库的一个核心优势就是代码共享——不单是指进程内的代码共享,还包括进程间的代码共享——实现这个目标的前提条件之一是动态库中的代码段不需要为任何进程做定制工作。而采用上述的方案显然需要为每一个进程都做一次代码修正(因为在动态链接中被替换的临时地址是在代码段中),所以是不可取的。
ELF针对上述问题给出的方案是GOT(Global Offset Table)。它的核心思想说得直白点,就是将“变”与“不变”的部分隔离开来——通过增加一个“中间层”GOT,来保持代码段的“不变”,而把“变”的部分放到GOT表中。
但是有了GOT就“万事大吉”了吗?大家是否想过这样的问题——如果程序中有非常多需要动态链接的对象,而它们中的绝大部分在程序执行过程中是不会被使用到的,那么我们在一开始就为所有对象做解析和重定位是否合理呢?实践证明这种“一杆子”的做法确实会影响程序的运行效率,特别是它的启动速度。聪明的人们马上又想到了有没有一种Lazy Binding的方法来在“需要动态对象的时候”才对它做重定位呢?这就是PLT的存在价值了。
接下来我们仍然以求和程序为例子,来详细分析下GOT和PLT两大机制的实现原理。
先来看下main函数对应的汇编代码:
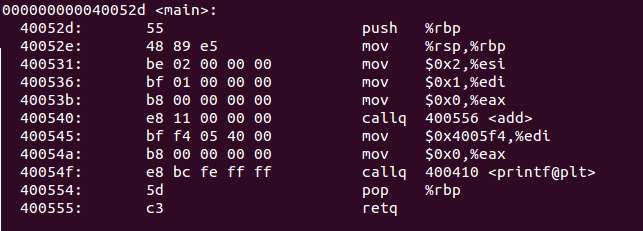
大家注意看下40054f这一行汇编语句:
callq 400410 <printf@plt>这里通过callq指令调用了一个地址为0x400410的目标位置,从释义来看它属于.plt区域。所以我们反编译.plt段来做跟进分析:

printf@plt的实现并不复杂:0x400410处是一条跳转指令,而且跳转地址被保存于0x200c02指针所指向的地址。通过0x400410语句后面的注释不难发现,0x200c02对应的是Global Offset Table偏移0x18的地方。
此时分为如下两种情况(以“求和”程序为例):
当printf被第1次访问时
当我们第一次调用printf这个函数时,程序首先通过callq调用printf@plt,然后在执行0x400410语句时跳转到GOT表中。可是此时printf函数的真实地址还未得到解析,换句话说GOT+0x18的地方保存的是0x400416——所以绕了一圈又回到了plt中。而0x400416是条堆栈语句,目的是为了保存printf在rel.plt中的序号(rel.plt中的信息包括了printf在GOT中的地址,以及它的名称“printf”,以便后续查找目标符号真实地址,并将结果值保存到正确的GOT地址中)。紧接着执行的0x40041b也是一条跳转语句,跳转目标是Plt[0]。PLT表的第一项是比较特殊的,它的工作简单来说就是为跳转到GOT[2]做准备。而GOT[0]、GOT[1]和GOT[2]都是系统预先保留的,其中GOT[2]中保存的是一个名为_dl_runtime_resolve的函数,用于解析某函数名(如“printf”)的真实地址。至此目标函数在第一次被访问时就可以得到正确的解析了。
当printf非首次执行时
有了上一步的努力后,GOT表中已经保存好printf的真实地址了。换句话说,当程序再次执行到0x400410这个位置时就不会再绕回0x400416,而是可以直接跳转到目标对象的真实地址了。
我们以下面的简图来帮助大家更好地理解上述讲解的整个过程(实际情况会更复杂一些,但原理是一样的):

图 0 20 GOT和PLT机制示意图
值得一提的是,不少开发人员经常分不清编译器提供的-fpic选项的作用。这个选项从字面意思上理解是“Position Independent Code”,即位置无关代码。确切地讲,是指代码段(.text)在运行时不需要重新定位(Relocation)。从本小节的分析中我们知道这一点是实现模块真正共享的关键,因为代码段的重新定位意味着使用者们需要各自拥有一份模块的拷贝,这显然是一种无谓的资源浪费。另外,地址无关技术不光适用于动态链接库,对可执行文件也是同样有效的(此时对应的选项是-fpie)。
我们在这两个小节中讲解的内容都是围绕C语言展开的,那么C++中的情况会不会有所差异呢?总的来讲,它们二者在最终形式上是大同小异的,主要的区别会体现在如下几个方面:
(1) Name Mangling
Mangle的字面意思是“损坏”,不难理解这是C++针对函数和变量采用的一种改名机制。这样做的原因有很多个,譬如为了支撑C++的重载功能——因为函数如果名字相同但参数不同,那么编译后的函数如果采用原先的名字就会出现重名现象。Name Mangling可以有效解决这个问题,它会综合考虑函数名和函数相关的信息(如参数)从而合成出一个全新的函数名称。C++标准中并没有对Mangling的具体做法做强制约束,这就意味着合成规则主要取决于编译器本身的设计。这一点对开发者的可能影响是我们无法通过函数名预先准确判断出它在Name Mangling后的结果,如此一来dlsym这样的函数在某些场景下可能就无计可施了——解决这个问题的一个可选的方法是在C++代码中使用extern “C”,以防止Name Mangling的发生。
(2) 类的加载
我们知道,C++是一门面向对象的语言,类的使用非常普遍。但是如何从一个C++代码生成的库中创建对象实例并不是件容易的事。不过这个问题已经有不少人给出了答案,限于篇幅我们不做深入分析,有兴趣的读者可以自行搜寻相关资料了解详情。