浅析 MapReduce/ Spark/ Spark Steaming/ Storm 与 HBase/HDFS
MapReduce 是大的批量操作,不要求时限。基于文件系统,hdfs。
Spark 是快速的批量操作,基于内存,所以速度快。其主要亮点在于把过程给数据。
Storm是流式处理,快速实时。
Spark Streaming 跟Storm类似,只不过Spark Streaming是小时间窗口的处理,Storm是实时的来一条处理一条。
1. storm技术架构:
Flume + kafka + Storm / Spark + Hbase / Redis的技术架构。
storm:流程: 把topology有向无环图分发到各个节点,数据到来时直接送到节点实时处理,处理期间以spout进入,经过多个bolt的处理过程,这个过程是以bult形式。最终写入HBase。
2. spark 技术架构:

spark逻辑:
把spark任务根据依赖度分成RDD,然后分成stage,再分成task,通过master把task分给worker,worker启动进程executor,executor启动多个线程去执行task。
创建RDD,创建执行计划,调度任务。
创建RDD就是把存在于文件的数据调入内存然后组织成RDD形式。
然后根据提交的任务(程序)把整个任务拆分成几个阶段(stage例如,先做RDD;然后做map操作也就是找出 一样的;最后对键相同的的做统计,这就是三个阶段),
最后就可以把这些任务分成task分配到不同的节点去执行了。
Spark Streaming技术架构:
和storm相似但有一个时间滑动窗口,即先汇集数据,到达一定量后按照数据块进行分发。
Spark Streaming流程:
总结:
spark与storm的业务目标有相似都有追求高效,但技术的架构spark与hadoop相似;都是准备好数据后把任务分配到数据上。
storm是现分布化任务然后等数据,spark是现分布化数据然后等任务。
spark和storm都支持DAG,所以应对复杂性运算还好。但MapReduce在应对复杂性上只能多次MapReduce,效率就不行了。
3.hadoop技术架构:
hadoop是以MapReduce计算模型为核心,包括HDFS文件存储系统和HBase数据库的一个架构。
MapReduce技术架构:
map作业 + map映射函数 和 reduce作业 + reduce合并函数
MapReduce处理流程:

外界传来一个数据文件,比如是txt格式,这个txt文件首先被MapReduce库切分成M个小文件(粒度大约16M-64M),切分后会把这些文件分布化到HDFS中;然后用fork把用户进程拷贝到集群内其他机器上。
(用户进程user program的副本中会有一个master,其它都是workermaster负责调度并为空闲worker分配作业也就是map作业和reduce作业,worker的数量可以由用户指定)
被分配了map作业的worker,开始读取对应分片的输入数据,map作业数量由M决定,和split一一对应,map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给 map函数,map函数产生的中间键值对被缓存在内存中。
缓存的中间键值对会被定期写入本地磁盘,而且被分为R个分区,R的大小由用户定义,将来每个分区会对应一个Reduce作业;这些中间键值对的位置会通报给master,master负责将信息转发给reduce worker。
master通知分配了reduce作业的worker它负责的分区在什么位置,不止一个地方,因为每个map作业产生的中间键值对都可能映射到所有R个不同分区,当reduce worker把所有它负责的中间键值对都读过来后,先对他们进行排序,使得相同键的键值对聚集在一起,因为不同的键可能会映射到同一个分区也就是同一个reduce作业,所以排序是必须的。
reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输入会添加到这个分区的输出文件中。
当所有的map和reduce作业都完成了,master唤醒正版的user program ,MapReduce函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(每一个对应一个reduce作业),用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。
整个过程的输入来子HDFS,中间数据放在本地文件系统,最终输出写入底层HDFS。
参考:
http://flyingsnail.blog.51cto.com/5341669/1571281/
疑问:
开始的txt文件是先切分然后送到各个机器还是在切分后仍然在原地机器上,等待调度???
总结:
对于复杂性运算,MapReduce在应对复杂性上只能多次MapReduce,就不适用了。因为要多次的IO。
4. HBase技术架构:

一个适合于非结构化数据存储的简单结构化分布式存储系统。面向列。
用MapReduce来处理数据,用HDFS来存储数据。
HBase处理流程:
写流程
来自MapReduce或者client的数据,在zookeeper的协调下在master上通过算法找到应该存储的HRegionServer,在HRegionServer上通过算法找到应该写入的HRegion,然后找到HStore,在写入HStore的MemStore之前会先写入HLog(恢复使用),HLog会不断删除旧数据也就是已经存到HStore的数据,然后往HStore的MemStore里写入,满了就flush到FileStore,FileStore到了阈值就跟其他FileStore合并,合并后的FileStore太大了就split出一个新的HRegion,也就是从下面的数据开始就被标记成新的另一个HRegion的name了。
如何寻找HRegionServer:
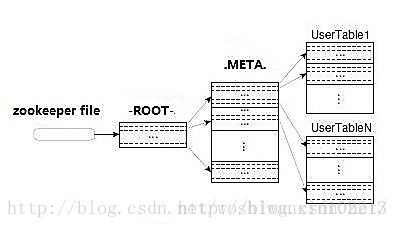
读流程
来自MapReduce或者client的操作,
疑问:
MapReduce输出的键值对是怎么变成column family形式的,因为HBase是以列的形式存储。???
下图中,HMaster还会直接管理DFS ???
HLog也会写入DFS ???
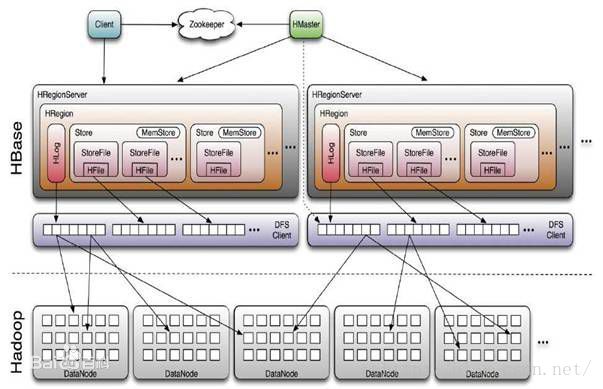
总结:
参考:
http://blog.csdn.net/woshiwanxin102213/article/details/17584043
5 HDFS技术架构:
Name Node ( FsImage存储文件块的映射表和文件系统配置信息 + EditLog事物日志 )+ Data Node

HDFS处理流程:
HBase的meta表存的可以是name node的信息,数据存入的时候也就是从HBase的HFile过来的时候一个Region可以对应这里Name Node的一个block。或者可以将Region再分成小文件块,这些块被存在Data Node中,不经过Name Node,Data Node中写入的信息多了后会生成一个新的块,并在心跳信息中报告给Name Node。Name Node用来操作文件命名空间的文件或者目录操作;数据块与数据节点的关系也是在Name Node中确定的。数据节点负责文件系统的读写,也就是块的读,写,创建,删除,和来自Name Node的复制命令。
在写入的时候,其实是先写入的客户端的本地文件中,当文件到达一个块大小时,客户端通知Name Node,Name Node把文件名插入命名系统中,并为之分配一个块包括块所在Data Node的ID和标识目标数据块的报文。这些信息就作为客户端请求的回复。客户断收到后把数据刷新到指定的Data Node中。文件关闭时,本地残留的未上传数据会转送到Data Node;然后Name Node就可以关闭了。
Name Node启动时会从磁盘中读取FsImage和EditLog,将EditLog中所有的事物应用到FsImage的仿内存中,然后将新的FsImage刷新到本地磁盘中,这时因为事物已经持久化到FsImage中,所以就可以删掉EditLog中的旧信息。这个过程也单独叫做检查点。
数据的安全性,数据之间的复制,数据的正确性,系统的可靠性,灾难恢复机能的实现。
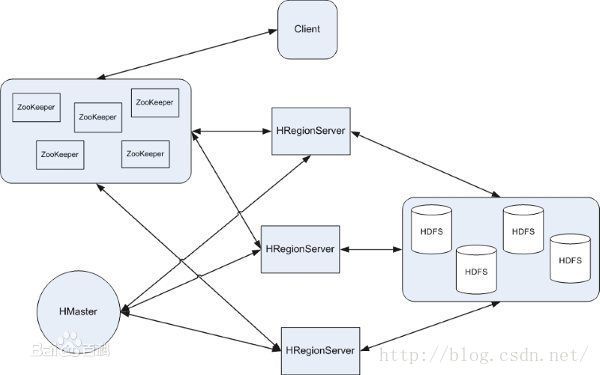
疑问:HDFS与HBase接入的地方,数据是怎么流动的???
总结: