用词袋(bag of word)实现场景识别
前段时间在standford university的计算机视觉:算法与应用这门课上做了一个小作业——利用词袋实现场景识别(Scene recognition with bag of words),下面整理如下:
一、词袋模型
最先是由Josef等基于自然语言处理模型而提出的。这一模型在文档分类里广为应用,通过统计each word的frequency来作为分类器的特征。类比一篇文章由很多文字(textual words) 组合而成,如果將一張图片表示成由许多 视觉单词(visual words)组合而成,就能将过去在文本检索(text retrieval)领域的技巧直接利用在图像检索(image retrieval)中,以文字检索系统现在的效率,图像表示的“文字化”也有助于大规模(large-scale)图像检索系统的效率。
下面通过一个简单的例子来说明词袋在文本处理中的应用:
如下两篇简单的文档;

基于这两篇文档建立一个字典(Dictionary)如下:
![]()
易见这个字典由10个distinct word构成,将其作为indexes,我们可将两篇文档表示为如下的10-entry vector:
![]()
通俗的讲:
Bag-of-words model实际就是把文档表示成向量,其中vector的维数就是字典所含词的个数,在上例中,vector中的第i个元素就是统计该文档中对应(字典)dictionry中的第i个单词出现的个数,因此可认为BoW model就是统计词频直方图的简单文档表示方法。
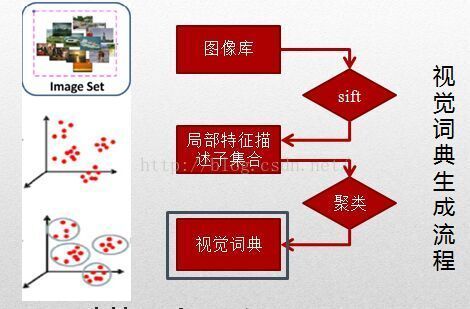
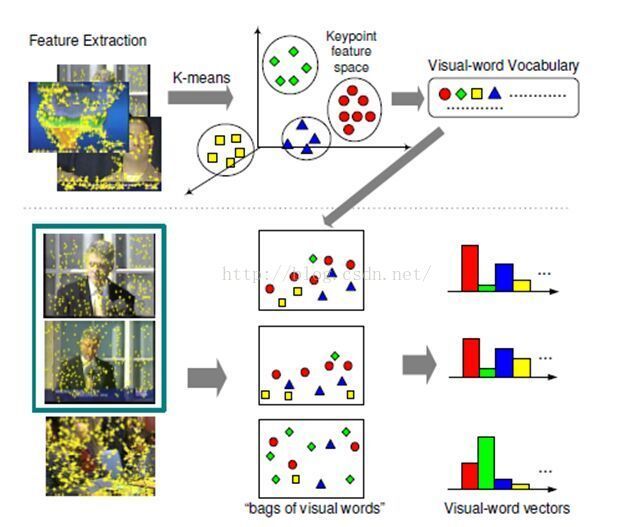
二、 词袋模型在计算机视觉中的应用
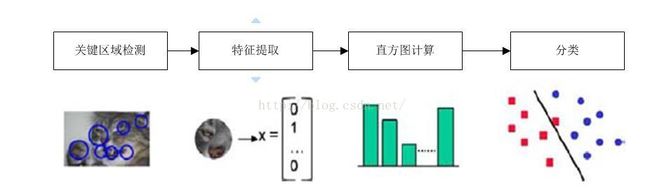
类别识别的最简单的算法之一是词袋(bag of words,也称为特征袋,即bag of features或“关键点袋”bag of keypoints)方法。词袋类别识别系统的典型处理框架如下图所示:
1. Matlab软件(我使用的mathlab是2013b试用版的)
2. vlfeat文件,可以是二进制包,也可以是源码。如果使用windows平台的话,推荐使用二进制包。
二进制包的下载地址可以从官网下载,也可以从我的个人网盘下载:
官网地址:http://www.vlfeat.org/download/vlfeat-0.9.18-bin.tar.gz
我的个人网盘地址:http://pan.baidu.com/s/1c0zPSqs
二、安装
1. 将所下载的二进制包解压缩到某个位置,如D:\盘
2.将解压完后的vlfeat文件复制到matlab安装目录toolbox文件夹下
3. 打开matlab,输入edit startup.m创建启动文件startup.m
4. 在startup.m中编辑发下内容(注意,如果将vlfeat安装在不同的地方,需要将以下的”D:\”改为你所安装的地址):

function image_feats = get_tiny_images(image_paths)
% image_paths is an N x 1 cell array of strings where each string is an
% image path on the file system.
% image_feats is an N x d matrix of resized and then vectorized tiny
% images. E.g. if the images are resized to 16x16, d would equal 256.
% small square resolution, e.g. 16x16. You can either resize the images to
% square while ignoring their aspect ratio or you can crop the center
% square portion out of each image. Making the tiny images zero mean and
% unit length (normalizing them) will increase performance modestly.
%file_paths = cell(System.IO.Directory.GetDirectories('D:\MATLAB\R2014a\bin\data3'));
%celldisp(file_paths);
[m,n] = size(image_paths);
d = 256;
%image_feats = [];
image_feats = zeros(m,d);
for i = 1:m
%string = image_paths{i};
s = num2str(cell2mat(image_paths(i)));
image = imread(s);
image = imresize(image,[16,16]);
image = reshape(image,1,256);
%image = image/norm(image); %normalize the tiny image
image = image - mean(image); %make the tiny image zero mean
image_feats(i,1:d) = image;
%image_feats = [image_feats;image];
endfunction predicted_categories = nearest_neighbor_classify(train_image_feats, train_labels, test_image_feats)
% image_feats is an N x d matrix, where d is the dimensionality of the
% feature representation.
% train_labels is an N x 1 cell array, where each entry is a string
% indicating the ground truth category for each training image.
% test_image_feats is an M x d matrix, where d is the dimensionality of the
% feature representation. You can assume M = N unless you've modified the
D = vl_alldist2(X,Y)
http://www.vlfeat.org/matlab/vl_alldist2.html
returns the pairwise distance matrix D of the columns of X and Y.
D(i,j) = sum (X(:,i) - Y(:,j)).^2
Note that vl_feat represents points as columns vs this code (and Matlab
in general) represents points as rows. So you probably want to use the
transpose operator '
vl_alldist2 supports different distance metrics which can influence
performance significantly. The default distance, L2, is fine for images.
CHI2 tends to work well for histograms.
[Y,I] = MIN(X) if you're only doing 1 nearest neighbor, or
[Y,I] = SORT(X) if you're going to be reasoning about many nearest
neighbors
%}
[N,d] = size(test_image_feats);
predicted_categories = cell(N,1);
dist = zeros(N,N);
for i = 1:N
for j = 1:N
dist(i,j) = vl_alldist2(test_image_feats(i,:)',train_image_feats(j,:)');
end
[Y,I] = min(dist(i,:));
predicted_categories(i,1) = train_labels(I);
end


function vocab = build_vocabulary( image_paths, vocab_size )
% The inputs are images, a N x 1 cell array of image paths and the size of
% the vocabulary.
[centers, assignments] = vl_kmeans(X, K)
http://www.vlfeat.org/matlab/vl_kmeans.html
X is a d x M matrix of sampled SIFT features, where M is the number of
features sampled. M should be pretty large! Make sure matrix is of type
single to be safe. E.g. single(matrix).
K is the number of clusters desired (vocab_size)
centers is a d x K matrix of cluster centroids. This is your vocabulary.
N = size(image_paths,1);
image_sampledSIFT = [];
for i = 1:4:N
s = num2str(image_paths(i)); %%s = num2str(cell2mat(image_paths(i)));
img = single(imread(s));
[locations,SIFT_features] = vl_dsift(img,'STEP',10);
SIFT_features = single(SIFT_features);
image_sampledSIFT = [image_sampledSIFT SIFT_features];
end
[vocab assignments] = vl_kmeans(image_sampledSIFT,vocab_size);
function image_feats = get_bags_of_sifts(image_paths)
% image_paths is an N x 1 cell array of strings where each string is an
% image path on the file system.
%{Useful functions:
[locations, SIFT_features] = vl_dsift(img)
http://www.vlfeat.org/matlab/vl_dsift.html
locations is a 2 x n list list of locations, which can be used for extra
credit if you are constructing a "spatial pyramid".
SIFT_features is a 128 x N matrix of SIFT features
D = vl_alldist2(X,Y)
http://www.vlfeat.org/matlab/vl_alldist2.html
returns the pairwise distance matrix D of the columns of X and Y.
D(i,j) = sum (X(:,i) - Y(:,j)).^2 %}load('vocab.mat')
fprintf('vocab loaded\n')
vocab_size = size(vocab, 2);
image_feats = [];
for i = 1:size(image_paths)
img = single(imread(num2str(cell2mat(image_paths(i)))));
[locations,SIFT_features] = vl_dsift(img,'STEP',10);
SIFT_features = single(SIFT_features);
D = vl_alldist2(vocab,SIFT_features);
[X,I] = min(D);
histogram = zeros(vocab_size,1);
for j = 1:vocab_size
histogram(I(j)) = histogram(I(j)) + 1;
end
histogram = histogram/norm(histogram);
image_feats(i,:) = histogram';
end
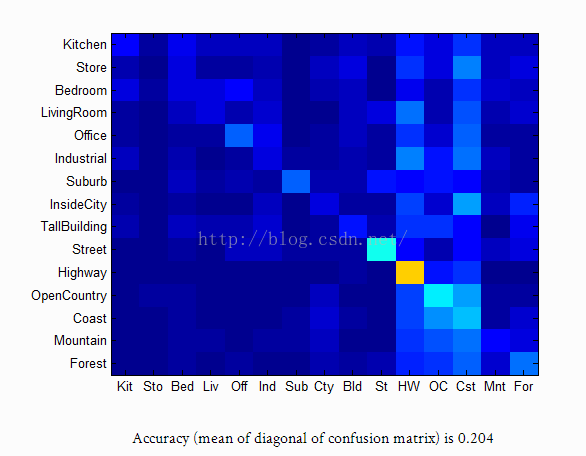
同样也是利用最近邻分类进行分类。
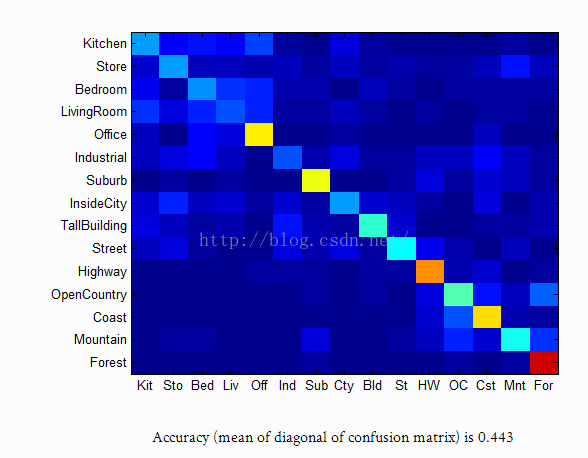
结果如下: