本文简单整理了以下内容:
(一)维数灾难
(二)特征提取——线性方法
1. 主成分分析PCA
2. 独立成分分析ICA
3. 线性判别分析LDA
(一)维数灾难(Curse of dimensionality)
维数灾难就是说当样本的维数增加时,若要保持与低维情形下相同的样本密度,所需要的样本数指数型增长。从下面的图可以直观体会一下。当维度很大样本数量少时,无法通过它们学习到有价值的知识;所以需要降维,一方面在损失的信息量可以接受的情况下获得数据的低维表示,增加样本的密度;另一方面也可以达到去噪的目的。

图片来源:[1]
有两种办法试图克服这个问题:首先是特征提取(Feature extraction),通过组合现有特征来达到降维的目的;然后是特征选择,从现有的特征里选择较小的一些来达到降维的目的。下面开始介绍特征提取。
(二)特征提取——线性方法
首先约定一下记号:
样本矩阵 $X=(\textbf x_1,\textbf x_2,...,\textbf x_N)=({\textbf x^{(1)}}^{\top};{\textbf x^{(2)}}^{\top};...;{\textbf x^{(d)}}^{\top})\in\mathbb R^{d\times N}$ ,$X_{ji}=x_i^{(j)}$;
$N$ 是训练集的样本数,每个样本都表示成 $\textbf x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(d)})\in\mathbb R^d$ 的列向量,样本矩阵的每一列都是一个样本;如果出现了 $\textbf x$ 这样没有上下标的记号就泛指任一样本,相当于省略下标;
$d$ 是特征的维数,每维特征都表示成 $\textbf x^{(j)}=(x_1^{(j)},x_2^{(j)},...,x_N^{(j)})\in\mathbb R^N$ 的列向量;如果出现了 $x^{(j)}$ 这样的记号就泛指任一样本的第 $j$ 维特征,相当于省略下标;
降维之后的样本矩阵 $Z\in\mathbb R^{k\times N}$ ,$k$ 是降维之后的特征维数,所以 $k\ll d$ ;每个样本被降维后都表示成 $\textbf z_i=(z_i^{(1)},z_i^{(2)},...,z_i^{(d)})\in\mathbb R^k$ 的列向量。
一、主成分分析(Principal component analysis,PCA)
PCA也叫主元分析,可谓是非常常用的一种线性降维方式,比如在人脸识别中的“特征脸”(Eigenfaces)。降维之后的每个“新”特征都被称为主成分。这是一种无监督的降维方法,没有用到样本的标记信息。
1. 定义:线性投影
下图是一个二维的例子,图示的两个方向为两个主成分的基底,我们可以通过PCA将它降成一维,也就是只保留一个基底。

图片来源:[6]
将原始数据 $X\in\mathbb R^{d\times N}$ 通过变换矩阵 $W=(\textbf w_1,\textbf w_2,...,\textbf w_k)\in\mathbb R^{d\times k}$ 投影到低维空间,得到变换后的数据 $Z\in\mathbb R^{k\times N}$
$$\begin{aligned}Z&=W^{\top}X\\&=(\textbf z_1,\textbf z_2,...,\textbf z_N)\\&=({\textbf z^{(1)}}^{\top};{\textbf z^{(2)}}^{\top};...;{\textbf z^{(d)}}^{\top})\end{aligned}$$
样本 $\textbf x_i$的经过映射后的得到的“新”样本 $\textbf z_i$ 为
$$\textbf z_i=W^{\top}\textbf x_i$$
分量表示为
$$z_i^{(j)}={\textbf w_j}^{\top}\textbf x_i,\quad j=1,2,...,d$$
可以直观看出,每个新的特征都是原先全部特征的线性组合。
“新”特征 $\textbf z^{(1)}={\textbf w_1}^{\top}X$ 称为第一主成分,随后是第二主成分 $\textbf z^{(2)}$,第三主成分……,只保留 $k$ 个主成分,构成样本 $\textbf x_i$ 降维后的表示 $\textbf z_i$ 。
2. 问题描述:矩阵分解
将变换矩阵记成 $W=(\textbf w_1,\textbf w_2,...,\textbf w_k)$ ,这是低维空间的一组标准正交基,每一列 $\textbf w_i\in\mathbb R^d$ 与其他列之间是互相正交的,而列本身的模为1。换句话说,矩阵 $W$ 需要满足正交约束(不能叫正交矩阵,因为只有方阵才谈得上是不是正交矩阵):
$$W^{\top}W=I$$
这样看的话,PCA 其实就是正交约束下的矩阵分解问题:
$$X=WZ$$
$$\textbf x_i=W\textbf z_i$$
3. 求解方法:协方差矩阵的特征值分解
现在的问题是,怎样确定出变换矩阵 $W$ 。PCA的基本做法是,在原始数据 $X$ (要去均值,也就是中心化)的协方差矩阵 $\varSigma_X$ 做特征值分解(实对称矩阵一定能找到一个正交矩阵使其对角化,这个正交矩阵正是由其特征值对应的特征向量所组成),将特征值从大到小排序,其中最大的特征值 $\lambda_1$ 所对应的特征向量 $\textbf w_1$ 作用在样本 $X$ 所得到的“新”特征 $\textbf z^{(1)}={\textbf w_1}^{\top}X$ 称为第一主成分,随后是第二主成分 $\textbf z^{(2)}$,第三主成分……,只保留 $k$ 个主成分,构成样本 $\textbf x_i$ 降维后的表示 $\textbf z_i$ 。$k$ 的值可通过下式来确定:
$$\frac{\sum\limits_{i=1}^k\lambda_i}{\sum\limits_{i=1}^d\lambda_i}\geq 95\%$$
4. PCA的motivation
为什么 PCA 要对协方差矩阵 $\varSigma_X$ 做特征值分解来得到主成分?下面简单说两种角度。
1) 最大投影方差
假设训练集样本的每一维特征都进行了去均值处理,使得 $\boldsymbol\mu (X)=\frac1N\sum_{i=1}^N\textbf x_i=\textbf 0\in\mathbb R^d$(需要注意,测试集的样本在做去均值操作时去掉的是训练集的均值,所以这个操作中得到的训练集的均值向量要保留)。
直接求解
考虑到降维到 $k$ 维的情况:希望投影后的每一维都尽可能地分开。
所以我们求取投影后的样本的协方差矩阵:
$$\begin{aligned}\varSigma_Z&=\frac{1}{N-1}\sum_{i=1}^N(\textbf z_i - \boldsymbol\mu(Z))(\textbf z_i - \boldsymbol\mu(Z))^{\top}\\&=\frac{1}{N-1}\sum_{i=1}^N\textbf z_i\textbf z_i^{\top}\\&=\frac{1}{N-1}ZZ^{\top}\\&=\frac{1}{N-1}W^{\top}XX^{\top}W\end{aligned}$$
因为
$$\varSigma_X=\frac{1}{N-1}\sum_{i=1}^N\textbf x_i\textbf x_i^{\top}=\frac{1}{N-1}XX^{\top}$$
不难看出 $\varSigma_X$ 就是样本去均值之后的协方差矩阵。所以有
$$\varSigma_Z=W^{\top}\varSigma_X W$$
这个形式很眼熟:首先,这和高斯分布经线性变换后的协方差矩阵形式一样,即原始协方差矩阵的二次型;其次,如果不降维的话(也就是说 $W$ 是个正交方阵),单从代数的角度来看,这里我们需要求取的 $\varSigma_Z$ ,不正是把协方差矩阵 $\varSigma_X$ 对角化吗?所以 $W$ 已经很显然了,就是 $\varSigma_X$ 的特征向量构成的矩阵。
由于 $\varSigma_Z$ 的对角线元素就代表了各维的方差,所以PCA的优化目标就是
$$\max_W\quad\text{tr}(W^{\top}\varSigma_X W)$$
约束是 $W^{\top}W=I$ ,然后用拉格朗日乘数法求解。但我觉得这样不直观,接下来从降维到一维入手,逐步求解主成分。
逐步求解
不妨先实现一个小目标:我们需要降维到一维,样本点在投影到一维之后,能够尽可能地“分开”——也就是投影后的方差最大。这时变换矩阵 $W$ 退化为一个向量 $\textbf w_1$ ,样本 $\textbf x_i$ 投影的结果为 $\textbf z_i =\textbf w_1^{\top}\textbf x_i\in\mathbb R$。
投影后的方差为:
$$\begin{aligned}&\frac{1}{N-1}\sum_{i=1}^N\textbf z_i\textbf z_i^{\top}\\=&\frac{1}{N-1}\sum_{i=1}^N(\textbf w_1^{\top}\textbf x_i)(\textbf w_1^{\top}\textbf x_i)^{\top}\\=&\textbf w_1^{\top}(\frac{1}{N-1}\sum_{i=1}^N\textbf x_i\textbf x_i^{\top})\textbf w_1\\=&\textbf w_1^{\top}\varSigma_X\textbf w_1\end{aligned}$$
为了实现上面降维到一维后方差最大的这个小目标,我们需要求解如下的约束最优化问题:
$$\max_{\textbf w_1}\quad\textbf w_1^{\top}\varSigma_X\textbf w_1$$
$$\text{s.t.}\quad\quad\|\textbf w_1\|=1$$
使用拉格朗日乘数法,那么问题的解就是拉格朗日函数 $L$ 的偏导数等于零这个方程的解:
$$L=\textbf w_1^{\top}\varSigma_X\textbf w_1-\lambda(\textbf w_1^{\top}\textbf w_1-1)$$
$$\frac{\partial L}{\partial \textbf w_1}=2\varSigma_X\textbf w_1-2\lambda\textbf w_1=0$$
$$\varSigma_X\textbf w_1=\lambda\textbf w_1$$
所以问题的解需要是 $\varSigma_X$ 的特征向量。优化目标 $\textbf w_1^{\top}\varSigma_X\textbf w_1=\textbf w_1^{\top}\lambda\textbf w_1=\lambda$ ,若要使它最大化,便要使 $\lambda$ 最大化。所以问题的解是 $\varSigma_X$ 的最大特征值所对应的特征向量。
现在已经证明了,第一主成分怎样得来。那么考虑到 $k$ 个主成分的情况:如何证明,最大的 $k$ 个特征值对应的特征向量所组成的矩阵 $W$ ,满足投影后的各维方差都尽可能大?
当然是数学归纳法:现在 $k=1$ 时成立(归纳基础),我们假设 $k=m$ 时成立,只要论证出 $k=m+1$ 时仍成立,那结论就是成立的。
现在已知 $\textbf w_1,\textbf w_2,...,\textbf w_m$ 是一组在新空间的维度为 $m$ 下满足投影方差最大的基底。$\textbf w_{m+1}$ 要满足的条件有:
(1) 模为1,$\|\textbf w_{m+1}\|=1$;(2) 与 $\textbf w_1,\textbf w_2,...,\textbf w_m$ 都正交,$\textbf w_{m+1}^{\top}\textbf w_j=0$ ;(3) $\textbf w_{m+1}^{\top}X$ 的方差最大
写成约束最优化的形式,就是
$$\max_W\quad \textbf w_{m+1}^{\top}\varSigma_X\textbf w_{m+1}$$
$$ \begin{aligned} \text{s.t.}\quad & \|\textbf w_{m+1}\|=1 \\& \textbf w_{m+1}^{\top}\textbf w_j=0,\quad j=1,2,...,m \end{aligned} $$
使用拉格朗日乘数,可得
$$L=\textbf w_{m+1}^{\top}\varSigma_X\textbf w_{m+1}-\lambda (\textbf w_{m+1}^{\top}\textbf w_{m+1}-1)-\sum_{j=1}^m\eta_j\textbf w_{m+1}^{\top}\textbf w_j$$
$$\frac{\partial L}{\partial \textbf w_1}=2\varSigma_X\textbf w_{m+1}-2\lambda\textbf w_{m+1}-\sum_{j=1}^m\eta_j\textbf w_j=0$$
将等式两边依次右乘 $\textbf w_j, j=1,2,...,m$ ,就可以依次得到 $\eta_j=0, j=1,2,...,m$,所以有
$$\varSigma_X\textbf w_{m+1}=\lambda\textbf w_{m+1}$$
这样就论证了 $\textbf w_{m+1}$ 就是协方差矩阵的第 $m+1$ 大的特征值所对应的特征向量。
2) 最小均方重建误差(mean square reconstruction error,MSRE)
我们知道,如果要从 $Z$ 再重建到原先数据所在的空间中,需要做的变换是 $WZ$ 。最小均方重建误差的优化目标为 $\min_W\quad\|X-WW^{\top}X\|^2$ ,约束为 $W^{\top}W=I$ 。可以推导出,优化目标等价于 $\max_W\quad\text{tr}(W^{\top}\varSigma_X W)$ 。也就是说和最大投影方差的优化目标一致。
3) 除此之外...
PCA还有另外若干种理解角度,如高斯随机采样。从这种角度理解可以参考[2],此外还介绍了PCA在指数族分布上的推广。
5. PCA 和 SVD 的关系
参考知乎的这个回答。
关于SVD,曾经在介绍 LSA 模型时提到过:
$$X=U\varSigma V^{\top}$$
那么就可以得到
$$XX^{\top}=U\varSigma \varSigma^{\top}U^{\top}$$
所以对比一下
$$\varSigma_X=W\varSigma_Z W^{\top}$$
就知道 U 和 W 的地位是一样的。
这反映出了奇异值与特征值的关系:矩阵 $X$ 的奇异值对应于 $XX^{\top}$ 的特征值的平方根,$X$ 的左奇异向量对应于 $XX^{\top}$ 的特征向量。
6. 其他说明
对于测试集,中心化操作中所减去的均值是训练集的;降维操作中的矩阵使用的是训练集的 $W$ 。机器学习方法中所有的预处理、调超参数等操作都不能混入任何测试集的信息,不妨想象:测试集就一个样本。
变换矩阵 $W$ 可以通过一个单隐层的AutoEncoder来求解,隐层神经元个数就是所谓的 $k$ ,这样就可以用神经网络那一套来训练了。这招是从 [1] 看的,恍然大悟的感觉,阅读经典的专著总会有意想不到的收获。
在实际的工业生产环境下,往往要面对数据量很大的情况,需要在线计算协方差矩阵,使得主成分随着新数据的到来而实时更新。方法是Oja’s Rule。
降维效果好坏的比较,应该还是从具体任务上的分类效果孰优孰劣来比较的。从低维的图里可以看出来,PCA还是比较适合于样本服从高斯分布,所以有些时候PCA降维后未必有很好的效果。
下面这个图是我本科毕设的实验,虚线的是PCA之前的,可见在这个特征空间下PCA降维对每个类的效果都有提升。

二、独立成分分析(Independent component analysis,ICA)
ICA相比于PCA,其追求的效果是不一样的:ICA寻找的是最能使数据的相互独立的方向,而PCA仅要求方向是不相关的。我们知道,独立可以推出不相关,反之则不可以,而高斯分布的情况下独立等价于不相关。因此ICA需要数据的高阶统计量,PCA则只需要二阶统计量。

图片来源:[6]
1. 背景
考虑盲信号分离(Blind signal separation)的问题:设有 $d$ 个独立的标量信号源发出声音,其在时刻 $t$ 发出的声音可表示为 $\textbf s_t=(s_t^{(1)},s_t^{(2)},...,s_t^{(d)})^{\top}\in\mathbb R^d$ 。同样地,有 $d$ 个观测器在进行采样,其在时刻 $t$ 记录的信号可表示为:$\textbf x_t\in\mathbb R^d$ 。认为二者满足下式,其中矩阵 $A\in\mathbb R^{d\times d}$ 被称为mixing matrix,反映信道衰减参数:
$$\textbf x_t=A\textbf s_t$$
显然,有多少个采样时刻,就可以理解为有多少个样本;而信号源的个数可以理解为特征的维数。ICA的目标就是从 $\textbf x$ 中提取出 $d$ 个独立成分,也就是找到矩阵unmixing matrix $W$ :
$$\textbf s_t=W\textbf x_t,\quad W=A^{-1}$$
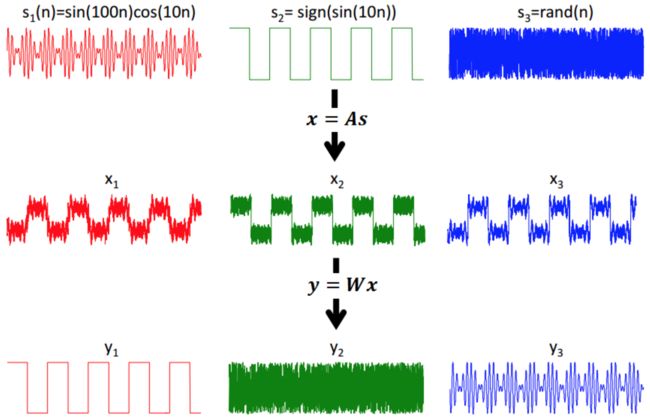
图片来源:[1]
将矩阵 $W$ 记为 $W=({\textbf w_1}^{\top};{\textbf w_2}^{\top};...;{\textbf w_d}^{\top})$ ,也就是它的第 $j$ 行是 ${\textbf w_j}^{\top}$ ,那么 $s_i^{(j)}={\textbf w_j}^{\top}\textbf x_i$ 。(这里的 $W$ 相比于PCA推导中的 $W$ 差一个转置)
2. 求解
在没有其他先验知识的情况下,由于上面式子中的只有观测信号是已知的,故无法求解:
首先是源信号的幅值不确定,导致矩阵 $W$ 随幅值的变化而变化;其次是源信号的顺序不确定,即使是完全相同的两组源信号而仅仅是顺序不同,因为当顺序更改了之后导致矩阵 $W$ 的行排列随之变化,所以无法确定出唯一的矩阵 $W$ 。
再有,源信号不能是高斯分布的。考虑2维情况,$\textbf s\sim N(\textbf 0,I)$ 。由于观测信号 $\textbf x_t=A\textbf s_t$ ,根据高斯分布的线性不变性,$\textbf x\sim N(\textbf 0,AIA^{\top})=N(\textbf 0,AA^{\top})$ 。现考虑另外一个mixing matrix $A'=AR$ ,其中 $R$ 是正交矩阵。则这时的观测信号 $\textbf x_t'=A'\textbf s_t$ ,且$\textbf x'\sim N(\textbf 0,A'IA'^{\top})=N(\textbf 0,ARR^{\top}A^{\top})=N(\textbf 0,AA^{\top})$ ,不同的mixing matrix却得到了相同的观测信号。可见当源信号服从高斯分布时 $W$ 不能唯一确定。从图示可以看出,高斯分布的线性不变性导致ICA失效。
图片来源:[1],图中的下标对应于本文的上标
现在考虑ICA的求解。之前说过,$d$ 个源信号是相互独立的(且没有噪声),所以源信号的密度函数可以表示为
$$p_{\textbf s}(\textbf s)=\prod_{j=1}^dp_s(s^{(j)})$$
观测信号 $\textbf s_t$ 和观测信号 $\textbf x_t$ 的关系是$\textbf x_t=A\textbf s_t$,它们的概率密度函数有如下关系:
$$p_{\textbf x}(\textbf x)=\frac{p_{\textbf s}(\textbf s)}{|A|}=p_{\textbf s}(\textbf s)|W|$$
可以得到下式
$$p_{\textbf x}(\textbf x)=|W|\prod_{j=1}^dp_s({\textbf w_j}^{\top}\textbf x)$$
现在需要做的是指定 $p_s(\cdot)$ 。在没有任何先验知识的情况下,可以指定
$$\begin{aligned}p_s(\cdot)&=\sigma '(\cdot)\\&=(\dfrac{1}{1+\exp(-\cdot)})'\\&=\dfrac{\exp(-\cdot)}{(1+\exp(-\cdot))^2}\\&=\sigma(\cdot)(1-\sigma(\cdot))\end{aligned}$$
这相当于分布函数是logistic函数,密度函数自然就是它的导函数。这是一个合理的指定,因为在很多问题上都work well;如果有先验知识当然可以指定为其他的形式。
给定 $N$ 个时刻的观测值,使用极大似然估计,得到似然函数为 $L(W)=\prod_{i=1}^Np_{\textbf x}(\textbf x_i)$,进一步得到对数似然函数为
$$l(W)=\sum_{i=1}^N(\sum_{j=1}^d\log \sigma'({\textbf w_j}^{\top}\textbf x_i)+\log |W|)$$
为了求极大值,需要用梯度上升法。根据公式 $\dfrac{\partial |W|}{\partial W}=|W|(W^{-1})^{\top}$ 以及 $\log\sigma'(\cdot)=1-2\sigma(\cdot)$,可求得对于一个样本的梯度为
$$\frac{\partial l_{1}}{\partial W}=(\textbf 1-2\sigma({\textbf w_j}^{\top}\textbf x_i))\textbf x_i^{\top}+(W^{-1})^{\top}$$
这里如果logistic函数的自变量为矩阵,就对逐个元素做运算,函数值是阶数相同的矩阵。这样就得到了优化目标对于一个样本的梯度,进而可以用梯度上升法迭代更新最大值。
附上sklearn中对PCA和ICA的介绍:2.5. Decomposing signals in components (matrix factorization problems)
三、线性判别分析(Linear Discriminant Analysis,LDA)
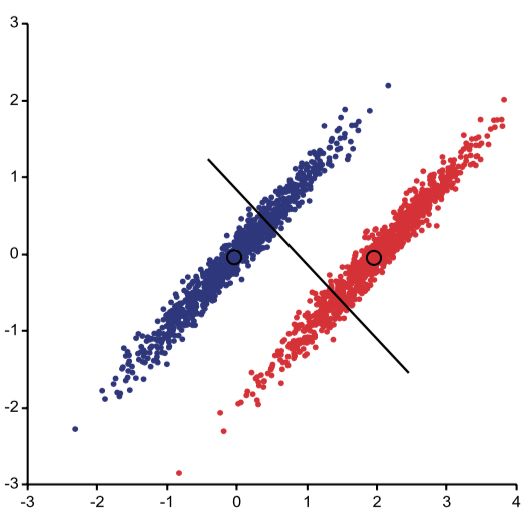
LDA也称为Fisher判别分析,是从更利于分类的角度来降维,利用到了训练样本的类别标记,追求的是最能够分开各个类别数据的投影方法。从下图可以看出,相比于直接用PCA降维,如果将样本投影到下图所示的直线上则会更利于分类。
LDA在NLP里通常指的是 latent Dirichlet allocation(隐狄利克雷分配),是一种主题模型的简称。不要搞混了。
严格说的话,LDA还要求了各个类别的协方差矩阵相等,这样可以从贝叶斯决策论的角度推导出LDA分类器的判别函数 $g_i(\textbf x)$ 为线性函数(Fisher判别分析则没有协方差矩阵相同的要求)。
图片来源:[3]
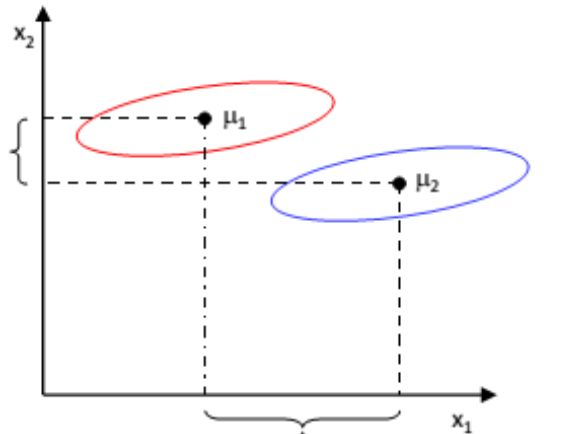
若想使得投影后的结果有利于分类,需要从两方面的需求考虑:一方面,投影之后相同类别的样本之间要尽可能近;另一方面,投影之后各个类别之间要尽可能远。
1. 二分类的情况
首先考虑二类问题,将 $d$ 维样本投影到一条方向由 $\textbf w$ 确定的的直线上。现在的问题就是找出 $\textbf w$ 。
一个容易想到的思路是投影后各个类的均值尽可能远。对于第 $i$ 类样本,投影前的均值为 $\boldsymbol\mu_i=\frac{1}{n_i}\sum_{\textbf x\in\omega_i}\textbf x$ ,投影后的均值为 $\widetilde{\boldsymbol\mu}_i=\textbf w^{\top}\boldsymbol\mu_i$ ,然后使 $|\widetilde\mu_1-\widetilde\mu_2|^2$ 最大化(因为降维后是一维,所以均值向量就是个标量,用了细体字母)。但这样其实是不行的,从下图一看便知:
图片来源:[7]
上述做法的症结在于,同类样本之间显然太远了,它只考虑了第二个需求而没有考虑第一个需求。所以,需要用总类内散度来归一化上述目标。首先定义如下几个概念:
类内散度矩阵(从定义中可看出与协方差矩阵相差一个常数倍):
$$S_i=\sum_{\textbf x\in\omega_i}(\textbf x-\boldsymbol\mu_i)(\textbf x-\boldsymbol\mu_i)^{\top}$$
总类内散度矩阵就是所有类别的类内散度矩阵之和:
$$S_W=\sum_{i=1}^cS_i$$
类间散度矩阵(式中 $\boldsymbol\mu=\frac1n\sum_{\textbf x}\textbf x$ 为全部数据的均值向量):
(1) 类别数等于2
$$S_B=(\boldsymbol\mu_1-\boldsymbol\mu_2)(\boldsymbol\mu_1-\boldsymbol\mu_2)^{\top}$$
(2) 类别数大于2
$$S_B=\sum_{i=1}^cn_i(\boldsymbol\mu_i-\boldsymbol\mu)(\boldsymbol\mu_i-\boldsymbol\mu)^{\top}$$
总体散度矩阵
$$S_T=S_W+S_B=\frac1n\sum_{\textbf x}(\textbf x-\boldsymbol\mu)(\textbf x-\boldsymbol\mu)^{\top}$$
经过变换矩阵 $W$ 后,类内散度矩阵和类间散度矩阵变为
$$\widetilde S_W=W^{\top}S_WW$$
$$\widetilde S_B=W^{\top}S_BW$$
(从形式上可以看出,与高斯分布经过线性变换后的新协方差矩阵的形式是一样的)
所以对于二类的情况,优化目标可以写为
$$J=\frac{|\widetilde\mu_1-\widetilde\mu_2|^2}{\widetilde s_1+\widetilde s_2}=\frac{\textbf w^{\top}S_B\textbf w}{\textbf w^{\top}S_W\textbf w}$$
该式是两个散度矩阵 $S_B$ 、$S_W$ 的广义瑞利商。
1) 普通解法:特征值分解
直接令该式的偏导数等于零,可以得到 $S_W^{-1}S_B\textbf w=J\textbf w$ ,所以可以看作是矩阵 $S_W^{-1}S_B$ 的特征值分解问题。另外,由于 $\textbf w$ 的幅值不影响问题的解,所以也可以看作下述约束最优化问题:
$$\min_{\textbf w}\quad -\textbf w^{\top}S_B\textbf w$$
$$\text{s.t.}\quad \textbf w^{\top}S_W\textbf w=1$$
使用拉格朗日乘数法可求得该问题的解就是下式的解:
$$S_W^{-1}S_B\textbf w=\lambda\textbf w$$
2) 另一种解法:典范变量
在这个问题中,其实没必要做特征值分解:
根据 $S_B=(\boldsymbol\mu_1-\boldsymbol\mu_2)(\boldsymbol\mu_1-\boldsymbol\mu_2)^{\top}$ ,得到 $S_B\textbf w=(\boldsymbol\mu_1-\boldsymbol\mu_2)(\boldsymbol\mu_1-\boldsymbol\mu_2)^{\top}\textbf w$ ,因为后两个因子的乘积是标量(记作 $a$ ),所以 $S_B\textbf w$ 总是位于 $\boldsymbol\mu_1-\boldsymbol\mu_2$ 的方向上,进而有 $\lambda\textbf w=aS_W^{-1}(\boldsymbol\mu_1-\boldsymbol\mu_2)$ 。所以可以立刻写出问题的解为
$$\textbf w=S_W^{-1}(\boldsymbol\mu_1-\boldsymbol\mu_2)$$
这个解有时被称为典范变量(Canonical variable)。
2. 多分类的情况
对于多分类问题,设类别个数是 $c$ ,从分类的角度讲是从 $d$ 维空间向 $c-1$ 维空间投影,从降维的角度来说的话是从 $d$ 维空间向 $k$ 维空间投影( $k\leq c-1$ )。记矩阵 $W=(\textbf w_1,...,\textbf w_{c-1})\in\mathbb R^{d\times(c-1)}$ 。优化目标通常是
$$J=\frac{|\widetilde S_B|}{|\widetilde S_W|}=\frac{\text{tr}(W^{\top}S_BW)}{\text{tr}(W^{\top}S_WW)}$$
其解的方程如下,最优矩阵 $W$ 的列向量是下列等式中最大特征值对应的特征向量:
$$S_W^{-1}S_B\textbf w_i=\lambda_i\textbf w_i$$
因为 $S_B$ 是 $c$ 个秩为1或0的矩阵的和,其中只有 $c-1$ 个是独立的,所以 $S_B$ 的秩不会超过 $c-1$ ,也就是说非零特征值至多只有 $c-1$ 个。
参考资料:
[1] 《模式分类》及slides
[2] 66天写的逻辑回归
[3] Dimension Reduction: A Guided Tour
[4][非线性方法推荐看这篇]【机器学习算法系列之三】简述多种降维算法
[5] CS229 Lecture notes11:ICA
[6] Assessment of multidimensional functional neuroimaging data model by statistical resampling
[7] A Tutorial on Data Reduction Linear Discriminant Analysis
[8] Independent Component Analysis: A Tutorial