损失函数(MSE和交叉熵)
全连接层解决MNIST:只是一层全连接层解决MNIST数据集
神经网络的传播:讲解了权重更新的过程
这个系列的文章都是为了总结我目前学习的积累。
损失函数
在我文章的网络中,我利用MSE(mean-square error,均方误差)作为损失函数,softmax作为激活函数。
prediction = tf.nn.softmax(tf.matmul(x, W)+b)
loss = tf.reduce_mean(tf.square(y-prediction))在我的理解中,样本是堆放在一个空间的。假设我们的理想模型是一个函数,那么图片经过它得出的值跟图片经过我们构建的模型得出的值之间的距离,可以通过MSE来近似表示。当值的距离无限缩小时,我们的模型也就越接近理想模型。
但是,其实在应用分类问题的过程中,我们偏向于应用交叉熵(损失函数)而不是MSE。
在监督学习(supervised learning)中,我们把问题分成回归和分类。两者的本质都是相同的,但是输出不一样。我们可以认为分类的输出是离散的,而回归的输出是连续的。举个例子:
我们来测量小明的温度。那么回归是输出他的体温,如37.5度、38度等等。而分类是着重在他发烧亦或者正常。
或许例子有点奇怪,但这是我认为的它们的区别。
要介绍熵,我们需要先从信息量讲起。我们需要明确一点,越难发生的事情,它能提供的信息也就越多,信息量也就越高。越容易发生的事情,它能提供的信息也就越小,信息量也就越低。再举个例子,当你设置了个闹钟,它响了,你理所当然觉得很正常,自然也不会提供任何信息给你。但是过了时间它还不响,那就说明了可能没电了、可能坏了。(例子真烂,哈哈哈)
由此看来,信息量是跟概率挂钩的存在。因此,相信我们都知道一件事情的概率都记作 p(xi) p ( x i ) ,那么信息量的定义如下:

这是 −ln(p(xi)) − l n ( p ( x i ) ) 横坐标在0.0 - 1.0的图像( 0<p(xi)<1 0 < p ( x i ) < 1 ),很形象的体现了信息量跟概率的关系。即随着概率的增加,能够提供的信息量逐步减少。
在信息论里面,熵是对不确定性的测量。但是在信息世界,熵越高,则能传输越多的信息,熵越低,则意味着传输的信息越少。
H(x)=E[I(x)]=E[−ln(p(x))]x={x1,x2,...,xn}H(xi)=∑ip(xi)I(xi)=−∑ip(xi)lnp(xi) H ( x ) = E [ I ( x ) ] = E [ − l n ( p ( x ) ) ] x = { x 1 , x 2 , . . . , x n } H ( x i ) = ∑ i p ( x i ) I ( x i ) = − ∑ i p ( x i ) l n p ( x i )
E为期望函数,而I(x)为x的信息量。即熵会等于信息量的期望,也就是所有x的概率乘以对应的信息量的总和。
我们需要再引入一个概念,相对熵(KL散度)。
KL散度是两个概率分布P和Q差别的非对称性的度量。(from Wiki)
那么我们可以知道,它是描述两个概率分布的差别。所谓的概率分布,也就是我们的标签和预测值了。我们在第一篇文章提到标签的one-hot格式是[0, 1, 0, …, 0]的类型,这是一个对MNIST数据集的准确的描述,因为它肯定它的某一个分类概率一定为1,而其他为0。但我们的预测值是一定同标签存在一定误差的,这也是我们评价这个模型的一个参数,损失值。
所以说,KL散度是用来描述误差很好的指标。那么我们为什么会用到交叉熵?
假设我们定义 P(x) P ( x ) (真实分布,即标签)和 Q(x) Q ( x ) (理论分布,即模型)为两个概率分布,那么对于他们的KL散度,我们可以有:
即, −H(P(x)) − H ( P ( x ) ) 为标签的熵,一个固定值。那么我们在优化标签和理论分布的KL散度的时候,不如直接优化后面的部分。我们将后面的部分称作交叉熵。
参考链接的第一个博客,还讲解了如何简化计算交叉熵。例子如下:
对于one-hot,p = [0, 1, 0],q = [0.2, 0.8, 0.3],有:
对于n-hot(多分类), p = [1, 1, 0], q = [0.8, 0.6, 0.3],真实分布中不止有一个为1,则:
loss函数公式的理解不是很难。我们需要明确,假如我们网络最后输出的是三个节点,那么,三个 xi x i 节点的loss值加在一起就是全部的loss。计算 xi x i 节点时,假如 xi x i 的概率 yi y i 为1,则其他的类别我们不需要判断。假如 xi x i 的概率 yi y i 为0时,我们计算loss值要计算其他真实存在的分类。
换了一个损失函数之后,从第一篇里面的最高准确率0.9179变成:
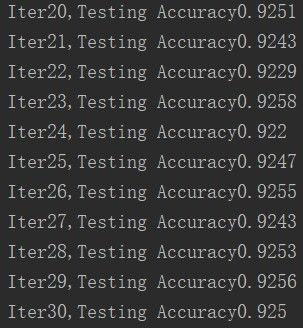
emmm,好像没提升多少,但最高值0.9258比0.9179多了0.079,也就是多了7.9%啦。
[参考]
https://blog.csdn.net/tsyccnh/article/details/79163834 (关于交叉熵,很好的教程)
https://www.zhihu.com/question/65288314/answer/244557337 (知乎上的大佬)
https://zh.wikipedia.org/wiki/%E7%9B%B8%E5%AF%B9%E7%86%B5 (Wikipedia)