【壹品仓App爬虫】charles、mitmproxy和appium联合爬取壹品仓App商品数据
charles、mitmproxy和appium联合爬取壹品仓App商品数据
一、项目介绍:
本次主要是想爬取壹品仓APP里的发布的品牌数据信息(图片、品牌介绍、活动截止时间等)和相应品牌的产品的具体信息(包括图片、商品介绍、商品库存、商品尺码、商品原价、商品现价等),项目github地址为:壹品仓App爬虫
查看更多python相关内容,可以查看我的个人网站大圣的专属空间
二、所使用的工具:
本次爬虫所使用的工具有:
pycharm、python、mitmproxy、appium、夜神模拟器、mongodb数据库,charlse其中mitmproxy、mongodb、夜神模拟器的安装请参考以前的博客内容:【APP爬虫】mitmproxy抓包工具和夜神模拟器爬取得到APP,appium、charles请参考自行在网上搜索安装或者参考崔大大的《python3网络爬虫开发实战书》,需要电子版本的可在评论区留邮箱,项目开始前请确保所有环境均配置成功,具体配置遇到问题请自行搜索,博主在此暂时不做工具安装的介绍,如果以后有机会将工具安装单独总结一篇。
三、开始项目的具体实现
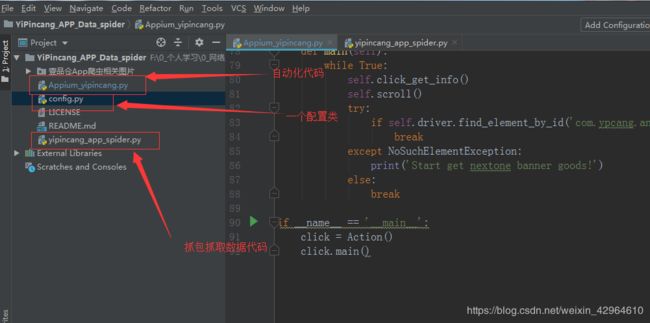
本项目的代码目录如下:
3.1 chales抓包
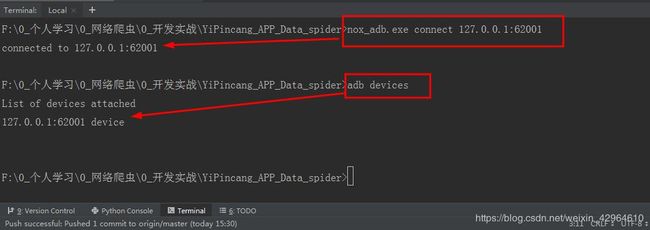
首先,我们在pycharm里面的Terminal里面输入nox_adb.exe connect 127.0.0.1:62001,开启夜神模拟器,输入adb devices可查看是否已经链接上模拟器:具体如下图所示:
然后我们打开我们的chales抓包工具,左侧可以看到抓取的url链接,右侧显示其内容:

接下来在我们点击打开夜神模拟器:
我们可以看到charles抓包工具开始获取相关链接,我们可以看到一个链接http://ypc.gongchengtemai.com,然后点开shop里面的homev5里面的homeindex,即可看到我们所需的品牌相关信息,如下:

接下来我们点击进入某个品牌,进入其详细商品界面,我们可以看到在刚才home5下面出现一堆goodslist,点击进入,我们即可看到我们所需要获取的商品信息:

此时我们即获取到了我们所需爬取信息的url链接地址,接下来我们采用mitmproxy联合appium联合获取APP中的信息
3.2、mitmproxy抓包
在开启mitmproxy之前,我们需要对夜神模拟器中的端口进行更改,由8888端口改成mitmproxy所设置的8080端口:
由上一节charles中的抓包信息我们已经获取了我们需要抓取信息的url链接地址,接下来我们编写获取信息的脚本,具体脚本如下,编码可以参考以前的博客内容:
Mitmproxy的使用(应用于爬虫)
【APP爬虫】mitmproxy抓包工具和夜神模拟器爬取得到APP
import json
from mitmproxy import ctx
import pymongo
def response(flow):
# 连接Mongodb数据库
myClient = pymongo.MongoClient("mongodb://localhost:27017/")
db = myClient['yipincang_goods_info']
banner_collection = db['banner_info']
goods_collection = db['goods_info']
response = flow.response
request = flow.request
# app首页链接
homeIndexUrl = 'http://ypc.gongchangtemai.com/shop/homev5/homeindex'
goodList = 'http://ypc.gongchangtemai.com/shop/homev5/goodslist'
# 获取主页每个品牌的基本信息
if homeIndexUrl in request.url:
text = response.text
homeData = json.loads(text)
bannersList = homeData.get('data').get('activity_list')
for bannerInfo in bannersList:
bannerData = {
'bannerId': bannerInfo.get('activity_id'),
'bannerImage': bannerInfo.get('activity_pic'),
'bannerIntroduce': bannerInfo.get('ac_desc'),
'endTime': bannerInfo.get('datetime')
}
ctx.log.error(str(bannerData))
banner_collection.insert_one(bannerData)
# 获取品牌内的商品信息
if goodList in request.url:
text = response.text
goodData = json.loads(text)
goodsList = goodData.get('data').get('goods_list')
bannerID = goodData.get('data').get('activity_info').get('activity_id')
for list in goodsList:
goodStorage = list.get('goods_storage')
if goodStorage != 0:
good_data = {
'belongToBannerId': bannerID,
'goodImage': list.get('goods_image'),
'goodStorage': list.get('goods_storage'),
'goodMarketPrice': list.get('goods_marketprice'),
'goodPrice': list.get('goods_price'),
'goodSize': list.get('size'),
'goodIntroduce': list.get('strace_title')
}
ctx.log.error(str(good_data))
goods_collection.insert_one(good_data)
此处我们已经编写好mitmproxy爬取相应信息的脚本,正常手动抓取的话,我们在命令行输入mitmdump -s yipincang_app.py运行脚本,手动打开APP点击,则电脑可根据我们的点击滑动获取相应信息,并保存至mongodb数据库中,,但是我们想实现自动化的获取,不需要人为参与,因此我们采用appium实现自动化的抓取。
3.3、Appium实现自动化
首先我们需要打开Appium软件,如下:


现在我们已经开启了appium,具体怎么使用我们这里不做详细的介绍,我们对配置做介绍,如下图:
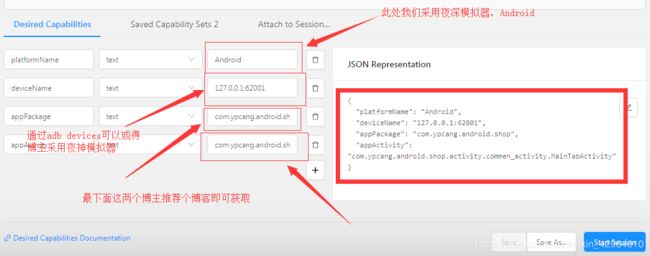
第一个博主用的安卓模拟器,因此此处写Android,可根据自己情况配置
第二个参数可以通过adb devices命令获得
最下面的两个参数可以参考博客:实现获取appPackage和appActivity的方法
接下来我们编写自动化脚本:此次爬虫仅仅需要获取相应属性并点击进入即可,因此自动化脚本不算太复杂,具体代码如下:
# 采用Appium和mitmproxy联合爬取壹品仓APP商品数据信息并保存至MongoDB数据库中
import sys
from appium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException, WebDriverException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
from config import *
class Action():
def __init__(self):
'''初始化'''
# 配置驱动
self.desired_caps = {
"platformName": platformName,
"deviceName": deviceName,
"appPackage": "com.ypcang.android.shop",
"appActivity": "com.ypcang.android.shop.activity.commen_activity.MainTabActivity"
}
self.driver = webdriver.Remote(driver_server, self.desired_caps)
self.wait = WebDriverWait(self.driver, timeout=timeout)
self.all_banners = []
self.type = sys.getfilesystemencoding()
def click_get_info(self):
# 点击进入某个品牌的详细界面
size = self.driver.get_window_size()
x1 = size['width']*0.5
y1 = size['height']*0.75
y2 = size['height']*0.55
try:
banner_info = self.wait.until(EC.presence_of_all_elements_located((By.ID, 'com.ypcang.android.shop:id/tvTitle')))
banner_text = banner_info[0].text
print(banner_text.encode(self.type).decode('GBK', 'ignore'))
if banner_text in self.all_banners:
self.driver.swipe(x1,y1,x1,y2,500)
print('The banner has been saved')
self.click_get_info()
else:
self.all_banners.append(banner_text)
banner_info[0].click()
except NoSuchElementException:
print('Can not find this elements!')
def scroll(self):
size = self.driver.get_window_size()
x1 = size['width']*0.5
y1 = size['height']*0.75
y2 = size['height']*0.25
y3 = size['height']*0.5
while True:
try:
self.driver.swipe(x1,y1,x1,y2,500)
# 获取商品的信息(为了判断停止下滑按钮)
try:
texts = self.wait.until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'android.widget.TextView')))
if texts[len(texts)-1].text == '-仓主,没有更多了-':
# 结束该品牌商品信息获取,返回首页
back = self.driver.find_element_by_id('com.ypcang.android.shop:id/imgBack')
back.click()
# 下滑获取下一个品牌的商品信息
try:
self.driver.swipe(x1,y1,x1,y3,500)
break
except WebDriverException:
print('The banner is loading,Please Wait a moment!')
sleep(2)
self.driver.swipe(x1,y1,x1,y3,500)
break
except NoSuchElementException:
print('Go on slide!')
except WebDriverException:
print('The Service request is so quick,Please Wait a moment!')
sleep(2)
def main(self):
while True:
self.click_get_info()
self.scroll()
try:
if self.driver.find_element_by_id('com.ypcang.android.shop:id/rvBanner'):
break
except NoSuchElementException:
print('Start get nextone banner goods!')
else:
break
if __name__ == '__main__':
click = Action()
click.main()
接下来我们先在命令行运行mitmdump -s yipincang_app_spider.py开启抓包抓取数据:

接下来我们直接运行自动化代码,Appium_yipincang.py,此时就开始进行自动化抓取数据,注意在代码编写的过程中需要进行异常处理,防止在自动化操作中报错:
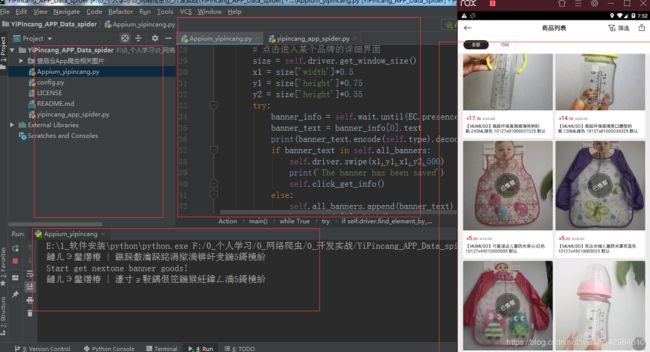
上面我们已经可以看到数据在不断的抓取,爬取时间较慢,后续研究如何实现数据的大批量抓取,完成后我们打开mongodb数据库即可看到我们抓取到的数据:
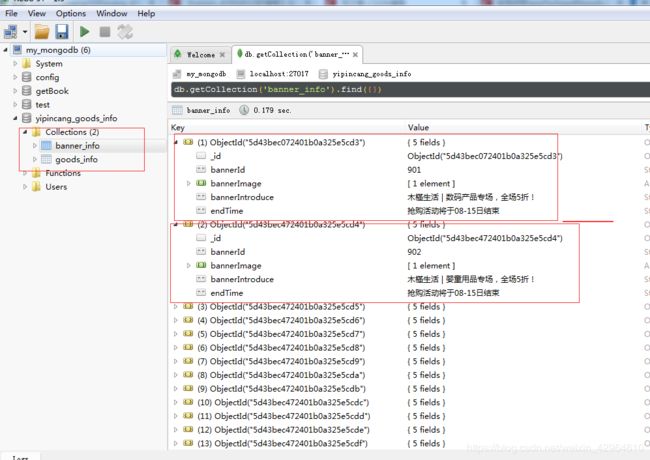

此时,我们完成了壹品仓App商品数据的抓取。
四、总结
- 每个商品获取了仅一张图片,后续会进行商品所有图片的获取
- 商品数据获取速度较慢,后续考虑如何完善
- Appium自动化测试代码编写技能需要提高
- mitmproxy还需不断学习提高
- 后续考虑爬取的数据有何价值