【Pytorch】基于MNIST数据集的手写数字识别
新手小白一个,我准备将自己的学习记录在这里,希望能遇到一些并肩同行的伙伴,希望大佬在评论区交流指出我的不足!最近在写准备写一个手写汉字识别的神经网络,于是跟大佬从头开始学习(莫烦python),首先从数字识别开始,把代码根据理解的加上了注释,让大家看的更明白,如果有同学对于函数不太理解,我把感觉通俗易懂的解释链接也放在下方。
如果引用的超链接损害了您的权益,请及时与我联系删除。
①导入模块
import torch
import torch.nn as nn # 神经网络库
from torch.autograd import Variable
import torch.utils.data as Data #数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。
import torchvision # 包括了图片的数据库
import matplotlib.pyplot as plt # 出图程序
②设置超参数
超参数:
在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
来源于百度百科
EPOCH = 1 # 训练几次
BATCH_SIZE = 50 # 数据集划分
LR = 0.001 # 学习率
DOWNLOAD_MNIST = False # 下载数据集
③数据集处理
train_data = torchvision.datasets.MNIST(
root = './mnist', # 数据路径
train = True, # True为训练集 False为测试集
transform = torchvision.transforms.ToTensor(),
download = DOWNLOAD_MNIST
)
torchvision.datasets是一个包含多种数据集的工具库,MNIST是其数据集之一
数据下载:
将DOWNLOAD赋值为True,等待下载即可,完成后赋值为False
.ToTensor-将[0,255]范围内的PIL.image(RGB)或numpy.ndarray(HxWxC)转换为[0.0,1.0]范围内的torch.FloatTensor(CxHxW)
h:图片高度
w:图片宽度
c:图片通道数
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) #迭代器
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False) #提取的是test 测试数据
test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1), volatile=True).type(torch.FloatTensor)[:2000]/255
test_y = test_data.test_labels[:2000] # 取2000个数据是为了节约运算时间
Variable中的volatile=true,它可以将所有依赖于它的节点全部设为volatile=true,优先级高于requires_grad=true.这样的节点不会进行求导,即使requires_grad为真,也无法进行反向传播.在inference中如果采用这种设置,可以实现一定程度的速度提升,并且节约大概一半显存.来源于简书
torch.utils.data函数介绍
torch.unsqueeze函数的介绍
④神经网络的构建
class CNN(nn.Module): # 卷积->池化->卷积->池化->全连接层
def __init__(self):
super(CNN, self).__init__() #这里我是死记硬背的,请教大佬们!
self.conv1 = nn.Sequential(
nn.Conv2d( # 卷积层
in_channels = 1, # 输入图片的高度
out_channels = 16, # 16个特征卷积过滤器
kernel_size = 5, #卷积宽度(长度)
stride = 1, # 步长
padding = 2, # 扩展图片边缘长宽度
# if stirder = 1, padding = (kernel_size-1)/2
), # ->(16, 28, 28))
nn.ReLU(), #激活函数
nn.MaxPool2d(kernel_size = 2), # 池化层→筛选重要信息 !!取一定区域内最大值!!
) # -> (16, 14, 14))
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2)
) # -> (32, 7, 7))
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) #将四维数据集变成二维
output = self.out(x)
return output
对于torch.nn.Module,可以参看这篇文章,耐心就有收获~
.Sequential直白理解就是将网络的各个层组合到一起
程序显然分为三块,第一块卷积采用16个卷积核,第二块卷积采用2个卷积核,最后一块则是全连接层,参数已经备注到程序中,在这里恕不赘述。
原始数据集情况:1 * 28 * 28 (表示只有一个颜色通道,一张图片像素大小是2828)
第一块卷积:16 * 28 * 28 (使用了16种卷积核,步长为1,两边各扩充1格,大小不变2828)
第一块max pooling池化之后: 16 * 14* 14 (使用2*2的大小进行降采样,图的大小缩小一倍)
第二块卷积之后:32 * 14 * 14(使用了2种卷积核,步长为1,两边各扩充2格,大小不变)
第二块max pooling之后:32 * 7 * 7
全连接层:10 (输出十个概率)
⑤参数优化和训练
误差计算:
cnn = CNN()
#print(cnn)
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # lr 学习率
loss_func = nn.CrossEntropyLoss() # 分类误差计算
训练模型:
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
b_x = Variable(x)
b_y = Variable(y)
output = cnn(b_x) # 数据集传入
loss = loss_func(output, b_y) # 计算误差
optimizer.zero_grad() # 导数清零
loss.backward()
optimizer.step() # step从0开始,遍历一个BATCH_SIZE就加一,训练集有60000个数据,所以step最后值为1199
if step % 50 == 0: #每五十个step就提示训练次数、误差和准确率
test_output = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.squeeze() # 取行中最大概率值
accuracy = (pred_y == test_y).sum().item() / test_y.size(0) # 行的大小
print('Epoch:', epoch, '| train loss:%.4f' % loss.data, '| test accuracy:', accuracy)
enumerate() 用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
对于本程序中的.backward()和.step()使用的解释,可以看这篇文章
⑥检验模型
test_output = cnn(test_x[:10]) # 利用前十个测试数据检测
pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
最后放上程序运行的效果
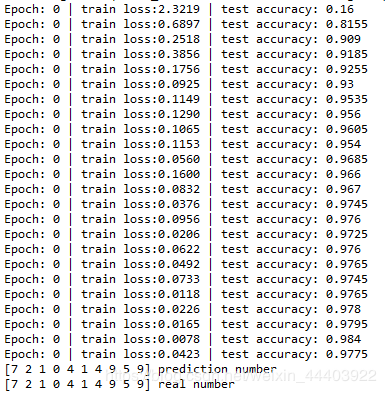
可以看到模型训练的准确性达到 97.75%,不知道这个准确率是否属实,可能是数据集数量太少。
以上则是代码的全部了,如果你耐心看懂了以上内容,那下一篇的手写汉字识别(代码已完成,正在写博客中…)我相信你也会轻车熟路啦!
做任何事都要有耐心,最后谢谢大家的耐心观看!
代码来自于莫烦Python视频,但是原代码在现在的版本上已经不能运行,我在原代码的基础上精心修改后并且详细的加上了注释,在此感谢莫烦哥哥的教学视频 网址献上
最后把全部代码放在→这里←,有需要的同学可以自行下载哦~