基于OCR训练的halcon汉字识别
使用halcon做字体识别,基于数字和字母组成的字符halcon自带了这类字符的分类器,我们只需要拿来用即可。
对于汉字字符的识别目前我所了解的,halcon似乎并不支持。因此我们需要通过训练OCR使halcon来识别汉字。
什么是OCR?
(百度百科):OCR(optical character recognition)文字识别是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题的友好性,产品的稳定性,易用性及可行性等。
halcon中的OCR助手的使用:
打开halcon的菜单栏上的助手,新建ocr,然后按顺序往下执行

对于ocr助手的使用这里不做过多的讲解,总之一句话:不是我的东西垃圾,是你不会用吧。
没错,我还在摸索中,若后续有机会我会把OCR助手的使用分享给大家,以上只是给大家熟悉熟悉OCR。
此处我们还是以halcon源码来实现halcon识别汉字。
材料:
训练用图片

识别用图片:

halcon代码:
**汉字识别**
************训练OCR**
read_image (Image, 'C:/此处路径自己行修改.png')
*通过阈值分割选中文字
rgb1_to_gray (Image, Gray)
threshold (Gray, Regions, 0, 0)
*由于汉字笔划与笔划之间有间隔,通过经过连通量运算会将其拆开,因此需要对文字进行一些加工
*腐蚀字体边界,使字体变得平滑
opening_circle (Regions, SelectedDotsOpening, 2)
*计算输入区域的并集
union1 (SelectedDotsOpening, Region)
*字体处理
closing_circle (Region, RegionClosing, 4)
connection (RegionClosing, ConnectedRegions)
*count_obj (ConnectedRegions, Number)
*定义识别内容
Fonts:=['你','好','丫','美','女','加','个','微','信','呗']
*trf文件存放路径
TrfPath:='C:/此处路径自己行修改.trf'
*omc文件存放路径
OmcPath:='C:/此处路径自己行修改.omc'
*向训练文件中添加字符
append_ocr_trainf (ConnectedRegions,Image, Fonts, TrfPath)
*查询训练库中的字符
read_ocr_trainf_names (TrfPath, CharacterNames, CharacterCount)
*使用多层感知器创建OCR分类器
create_ocr_class_mlp (8, 10, 'constant', 'default', CharacterNames, 80, 'none', 10, 42, OCRHandle)
*训练一个OCR分类器
trainf_ocr_class_mlp (OCRHandle, TrfPath, 200, 1, 0.01, Error, ErrorLog)
*将OCR分类器写入文件
write_ocr_class_mlp (OCRHandle, OmcPath)
**********************************************
**********************************************
******************开始识别**
read_image (Image, 'C:/此处路径自己行修改.png')
rgb1_to_gray (Image, Gray)
threshold (Gray, Regions, 0, 100)
opening_circle (Regions, SelectedDotsOpening, 2)
union1 (SelectedDotsOpening, Region)
closing_circle (Region, RegionClosing, 3)
connection (RegionClosing, ConnectedRegions)
count_obj (ConnectedRegions, Number)
*左到右排序
sort_region (ConnectedRegions, SortedRegions, 'character', 'true', 'column')
*从文件中读取OCR分类器
read_ocr_class_mlp (OmcPath, OCRHandle)
*使用OCR分类器对多个字符进行分类
do_ocr_multi_class_mlp (SortedRegions, Image, OCRHandle, Class, Confidence)
*显示结果
dev_clear_window ()
dev_display (Image)
dev_set_color ('black')
*显示结果
dev_set_color ('black')
disp_message(3600, '识别结果:', 'image', 550, 50, 'black', 'false')
for i:=1 to Number by 1
disp_message(3600, Class[i-1], 'image', 550, 210+50*i, 'black', 'false')
endfor
*注意:这里没有训练的三‘嘿’字被误识为‘呗’字结果:
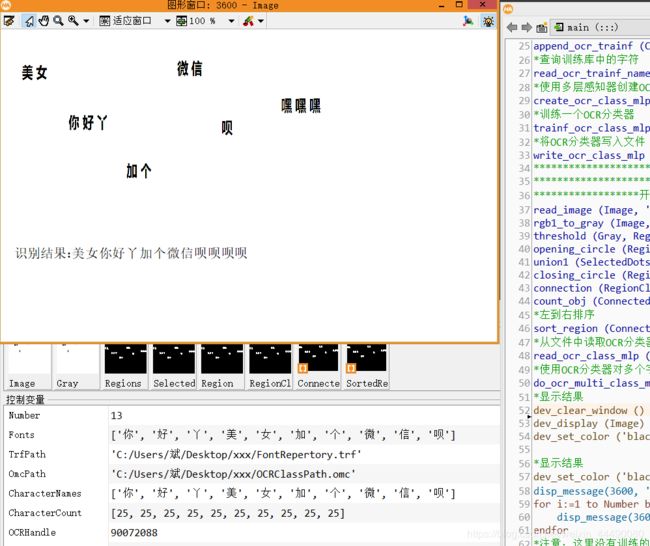
你会发现,没有被训练的字体被误认了,这跟OCR的算法匹配有关。