不会这些,别说懂机器学习
作为高科技公司的一名非技术出身的员工,小编最近一直在恶补各种技术知识。这不,昨天小编在恶补的过程中看到了一篇介绍机器学习算法基础知识的文章,写的很全面,就想着分享给大家啦~
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
在我们了解了需要解决的机器学习问题的类型之后,我们可以开始考虑搜集来的数据的类型以及我们可以尝试的机器学习算法。在这个帖子里,我们会介绍一遍最流行的机器学习算法。通过浏览主要的算法来大致了解可以利用的方法是很有帮助的。
可利用的算法非常之多。困难之处在于既有不同种类的方法,也有对这些方法的扩展。这导致很快就难以区分到底什么才是正统的算法。在这个帖子里,我希望给你两种方式来思考和区分在这个领域中你将会遇到的算法。
第一种划分算法的方式是根据学习的方式,第二种则是基于形式和功能的相似性(就像把相似的动物归为一类一样)。两种方式都是有用的。
学习方式
基于其与经验、环境,或者任何我们称之为输入数据的相互作用,一个算法可以用不同的方式对一个问题建模。在机器学习和人工智能教科书中,流行的做法是首先考虑一个算法的学习方式。
算法的主要学习方式和学习模型只有几个,我们将会逐一介绍它们,并且给出几个算法和它们适合解决的问题类型来作为例子。
监督学习:输入数据被称为训练数据,它们有已知的标签或者结果,比如垃圾邮件/非垃圾邮件或者某段时间的股票价格。模型的参数确定需要通过一个训练的过程,在这个过程中模型将会要求做出预测,当预测不符时,则需要做出修改。
无监督学习:输入数据不带标签或者没有一个已知的结果。通过推测输入数据中存在的结构来建立模型。这类问题的例子有关联规则学习和聚类。算法的例子包括Apriori算法和K-means算法。
半监督学习:输入数据由带标记的和不带标记的组成。合适的预测模型虽然已经存在,但是模型在预测的同时还必须能通过发现潜在的结构来组织数据。这类问题包括分类和回归。典型算法包括对一些其他灵活的模型的推广,这些模型都对如何给未标记数据建模做出了一些假设。
强化学习:输入数据作为来自环境的激励提供给模型,且模型必须作出反应。反馈并不像监督学习那样来自于训练的过程,而是作为环境的惩罚或者是奖赏。典型问题有系统和机器人控制。算法的例子包括Q-学习和时序差分学习(Temporal Difference Learning)。
当你处理大量数据来对商业决策建模时,通常会使用监督和无监督学习。目前一个热门话题是半监督学习,比如会应用在图像分类中,涉及到的数据集很大但是只包含极少数标记的数据。
算法相似性
通常,我们会把算法按照功能和形式的相似性来区分。比如树形结构和神经网络的方法。这是一种有用的分类方法,但也不是完美的。仍然有些算法很容易就可以被归入好几个类别,比如学习矢量量化,它既是受启发于神经网络的方法,又是基于实例的方法。也有一些算法的名字既描述了它处理的问题,也是某一类算法的名称,比如回归和聚类。正因为如此,你会从不同的来源看到对算法进行不同的归类。就像机器学习算法自身一样,没有完美的模型,只有足够好的模型。
在这个小节里,我将会按照我觉得最直观的方式列出许多流行的机器学习算法。虽然不管是类别还是算法都不是全面详尽的,但我认为它们都具有代表性,有助于你对整个领域有一个大致的了解。如果你发现有一个或一类算法没有被列入,将它写在回复里和大家分享。让我们来开始吧。
回归分析
回归是这样一种建模方式,它先确定一个衡量模型预测误差的量,然后通过这个量来反复优化变量之间的关系。回归方法是统计学的主要应用,被归为统计机器学习。这有些让人迷惑,因为我们可以用回归来指代一类问题和一类算法。实际上,回归是一个过程。以下是一些例子:
普通最小二乘法
逻辑回归
逐步回归
多元自适应样条回归(MARS)
局部多项式回归拟合(LOESS)
基于实例的方法
基于实例的学习模型对决策问题进行建模,这些决策基于训练数据中被认为重要的或者模型所必需的实例。这类方法通常会建立一个范例数据库,然后根据某个相似性衡量标准来把新数据和数据库进行比较,从而找到最匹配的项,最后作出预测。因此,基于实例的方法还被叫做“赢者通吃”方法和基于记忆的学习。这种方法的重点在于已有实例的表示以及实例间相似性的衡量标准。
K最近邻算法(kNN)
学习矢量量化(LVQ)
自组织映射(SOM)
正则化方法
这是对另一种方法(通常是回归分析方法)的扩展,它惩罚复杂度高的模型,倾向推广性好的更加简单的模型。我在这里列下了一些正则化的方法,因为他们流行、强大,而且通常只是对其他方法简单的改进。
岭回归
套索算法(LASSO)
弹性网络
决策树学习
决策树方法对决策过程进行建模,决策是基于数据中属性的实际数值。决策在树形结构上分叉直到对特定的某个记录能做出预测。在分类或者回归的问题中我们用数据来训练决策树。
分类与回归树算法(CART)
迭代二叉树3代(ID3)
C4.5算法
卡方自动互动检视(CHAID)
单层决策树
随机森林
多元自适应样条回归(MARS)
梯度推进机(GBM)
贝叶斯算法
贝叶斯方法是那些明确地在分类和回归问题中应用贝叶斯定理的算法。
朴素贝叶斯算法
AODE算法
贝叶斯信度网络(BBN)
核函数方法
核函数方法中最为出名的是流行的支持向量机算法,它其实是一系列方法。核函数方法关心的是如何把输入数据映射到一个高维度的矢量空间,在这个空间中,某些分类或者回归问题可以较容易地解决。
支持向量机(SVM)
径向基函数(RBF)
线性判别分析(LDA)
聚类方法
就像回归一样,聚类既表示一类问题,也表示一类方法。聚类方法一般按照建模方式来划分:基于质心的或者层级结构的。所有的方法都是利用数据的内在结构来尽量地把数据归入具有最大共性的一类里。
K均值法
最大期望算法(EM)
关联规则学习
关联规则学习是提取规则的一类算法,这些规则能最好地解释观测到的数据中的变量之间的关系。这些规则能在大型多维数据集中发现重要且在商业上有用的关联,然后进一步被利用。
Apriori算法
Eclat算法
人工神经网络
人工神经网络是受启发于生物神经网络的结构和/或功能的算法。它们是一类常用在回归和分类问题中的模式匹配方法,但其实这个庞大的子类包含了上百种算法和算法的变形,可以解决各种类型的问题。一些经典流行的方法包括(我已经把深度学习从这个类中分出来了):
感知器
反向传播算法
Hopfield神经网络
自适应映射(SOM)
学习矢量量化(LVQ)
深度学习
深度学习方法是利用便宜冗余的计算资源对人工神经网络的现代改进版。这类方法试图建立大得多也复杂得多的神经网络,就如前面说到的,许多方法都是基于大数据集中非常有限的标记数据来解决半监督学习问题。
受限玻尔兹曼机(RBM)
深度信念网(DBN)
卷积神经网络
层叠自动编码器(SAE)
降维方法
如同聚类方法,降维方法试图利用数据中的内在结构来总结或描述数据,所不同的是它以无监督的方式利用更少的信息。这对于可视化高维数据或者为之后的监督学习简化数据都有帮助。
主成分分析(PCA)
偏最小二乘法回归(PLS)
萨蒙映射
多维尺度分析(MDS)
投影寻踪
集成方法
集成方法由多个较弱模型组合而成,这些子模型独立训练,它们的预测结果以某种方式整合起来得出总的预测。很多努力都集中在选择什么类型的学习模型作为子模型,以及用什么方式整合它们的结果。这是一类非常强大的技术,因此也很流行。
推进技术(Boosting)
自展集成(Bagging)
适应性推进(AdaBoost)
层叠泛化策略(Blending)
梯度推进机(GBM)
随机森林
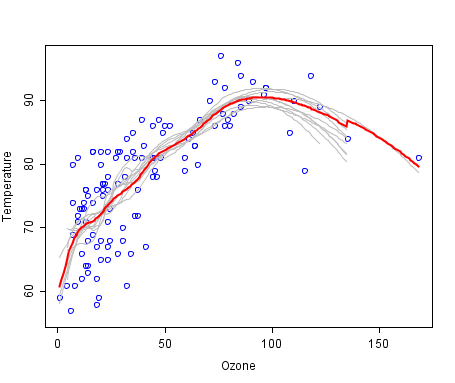
这是一个最适曲线集成的例子。弱成员用灰色线表示,整合后的预测用红色。这个图显示了温度/臭氧数据,曲线出自使用局部多项式回归拟合(LOESS)的模型。
图片授权自公有领域(public domain),归于维基百科。
英语原文
原文地址:http://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/
After we understand the type of machine learning problem we are working with, we can think about the type of data to collect and the types of machine learning algorithms we can try. In this post we take a tour of the most popular machine learning algorithms. It is useful to tour the main algorithms to get a general idea of what methods are available.
There are so many algorithms available. The difficulty is that there are classes of method and there are extensions to methods and it quickly becomes very difficult to determine what constitutes a canonical algorithm. In this post I want to give you two ways to think about and categorize the algorithms you may come across in the field.
The first is a grouping of algorithms by the learning style. The second is a grouping of algorithms by similarity in form or function (like grouping similar animals together). Both approaches are useful.
Learning Style
There are different ways an algorithm can model a problem based on its interaction with the experience or environment or whatever we want to call the input data. It is popular in machine learning and artificial intelligence text books to first consider the learning styles that an algorithm can adopt.
There are only a few main learning styles or learning models that an algorithm can have and we’ll go through them here with a few examples of algorithms and problem types that they suit. This taxonomy or way of organizing machine learning algorithms is useful because it forces you to think about the the roles of the input data and the model preparation process and select one that is the most appropriate for your problem in order to get the best result.
Supervised Learning: Input data is called training data and has a known label or result such as spam/not-spam or a stock price at a time. A model is prepared through a training process where it is required to make predictions and is corrected when those predictions are wrong. The training process continues until the model achieves a desired level of accuracy on the training data. Example problems are classification and regression. Example algorithms are Logistic Regression and the Back Propagation Neural Network.
Unsupervised Learning: Input data is not labelled and does not have a known result. A model is prepared by deducing structures present in the input data. Example problems are association rule learning and clustering. Example algorithms are the Apriori algorithm and k-means.
Semi-Supervised Learning: Input data is a mixture of labelled and unlabelled examples. There is a desired prediction problem but the model must learn the structures to organize the data as well as make predictions. Example problems are classification and regression. Example algorithms are extensions to other flexible methods that make assumptions about how to model the unlabelled data.
Reinforcement Learning: Input data is provided as stimulus to a model from an environment to which the model must respond and react. Feedback is provided not from of a teaching process as in supervised learning, but as punishments and rewards in the environment. Example problems are systems and robot control. Example algorithms are Q-learning and Temporal difference learning.
When crunching data to model business decisions, you are most typically using supervised and unsupervised learning methods. A hot topic at the moment is semi-supervised learning methods in areas such as image classification where there are large datasets with very few labelled examples. Reinforcement learning is more likely to turn up in robotic control and other control systems development.
Algorithm Similarity
Algorithms are universally presented in groups by similarity in terms of function or form. For example, tree based methods, and neural network inspired methods. This is a useful grouping method, but it is not perfect. There are still algorithms that could just as easily fit into multiple categories like Learning Vector Quantization that is both a neural network inspired method and an instance-based method. There are also categories that have the same name that describes the problem and the class of algorithm such as Regression and Clustering. As such, you will see variations on the way algorithms are grouped depending on the source you check. Like machine learning algorithms themselves, there is no perfect model, just a good enough model.
In this p I list many of the popular machine leaning algorithms grouped the way I think is the most intuitive. It is not exhaustive in either the groups or the algorithms, but I think it is representative and will be useful to you to get an idea of the lay of the land. If you know of an algorithm or a group of algorithms not listed, put it in the comments and share it with us. Let’s dive in.
Regression
Regression is concerned with modelling the relationship between variables that is iteratively refined using a measure of error in the predictions made by the model. Regression methods are a work horse of statistics and have been cooped into statistical machine learning. This may be confusing because we can use regression to refer to the class of problem and the class of algorithm. Really, regression is a process. Some example algorithms are:
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS)
Instance-based Methods
Instance based learning model a decision problem with instances or examples of training data that are deemed important or required to the model. Such methods typically build up a database of example data and compare new data to the database using a similarity measure in order to find the best match and make a prediction. For this reason, instance-based methods are also called winner-take all methods and memory-based learning. Focus is put on representation of the stored instances and similarity measures used between instances.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM)
Regularization Methods
An extension made to another method (typically regression methods) that penalizes models based on their complexity, favoring simpler models that are also better at generalizing. I have listed Regularization methods here because they are popular, powerful and generally simple modifications made to other methods.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net
Decision Tree Learning
Decision tree methods construct a model of decisions made based on actual values of attributes in the data. Decisions fork in tree structures until a prediction decision is made for a given record. Decision trees are trained on data for classification and regression problems.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM)
Bayesian
Bayesian methods are those that are explicitly apply Bayes’ Theorem for problems such as classification and regression.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN)
Kernel Methods
Kernel Methods are best known for the popular method Support Vector Machines which is really a constellation of methods in and of itself. Kernel Methods are concerned with mapping input data into a higher dimensional vector space where some classification or regression problems are easier to model.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA)
Clustering Methods
Clustering, like regression describes the class of problem and the class of methods. Clustering methods are typically organized by the modelling approaches such as centroid-based and hierarchal. All methods are concerned with using the inherent structures in the data to best organize the data into groups of maximum commonality.
k-Means
Expectation Maximisation (EM)
Association Rule Learning
Association rule learning are methods that extract rules that best explain observed relationships between variables in data. These rules can discover important and commercially useful associations in large multidimensional datasets that can be exploited by an organisation.
Apriori algorithm
Eclat algorithm
Artificial Neural Networks
Artificial Neural Networks are models that are inspired by the structure and/or function of biological neural networks. They are a class of pattern matching that are commonly used for regression and classification problems but are really an enormous subfield comprised of hundreds of algorithms and variations for all manner of problem types. Some of the classically popular methods include (I have separated Deep Learning from this category):
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ)
Deep Learning
Deep Learning methods are a modern update to Artificial Neural Networks that exploit abundant cheap computation. The are concerned with building much larger and more complex neural networks, and as commented above, many methods are concerned with semi-supervised learning problems where large datasets contain very little labelled data.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders
Dimensionality Reduction
Like clustering methods, Dimensionality Reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarise or describe data using less information. This can be useful to visualize dimensional data or to simplify data which can then be used in a supervized learning method.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit
Ensemble Methods
Ensemble methods are models composed of multiple weaker models that are independently trained and whose predictions are combined in some way to make the overall prediction. Much effort is put into what types of weak learners to combine and the ways in which to combine them. This is a very powerful class of techniques and as such is very popular.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
Resources
This tour of machine learning algorithms was intended to give you an overview of what is out there and some tools to relate algorithms that you may come across to each other.
The resources for this post are as you would expect, other great lists of machine learning algorithms. Try not to feel overwhelmed. It is useful to know about many algorithms, but it is also useful to be effective and have a deep knowledge of just a few key methods.
List of Machine Learning Algorithms:On Wikipedia. Although extensive, I do not find this list or the organization of the algorithms particularly useful.
Machine Learning Algorithms Category:Also on Wikipedia, a slightly more useful than Wikipedias great list above. It organizes algorithms alphabetically.
CRAN Task View: Machine Learning & Statistical Learning: A list of all the packages and all the algorithms supported by each machine learning package in R. Gives you a grounded feeling of what’s out there and what people are using for analysis day-to-day.
Top 10 Algorithms in Data Mining: Published article and now a book (Affiliate Link) on the most popular algorithms for data mining. Another grounded and less overwheling take on methods that you could go off and learn deeply.
I hope you have found this tour useful. Leave a comment if you know of a better way to think about organizing algorithms or if you know of any other great lists of machine learning algorithms.
UPDATE: Continue the discussion on HackerNews and reddit.
List of Machine Learning Algorithms: On Wikipedia. Although extensive, I do not find this list or the organization of the algorithms particularly useful.
Machine Learning Algorithms Category: Also on Wikipedia, a slightly more useful than Wikipedias great list above. It organizes algorithms alphabetically.
CRAN Task View: Machine Learning & Statistical Learning: A list of all the packages and all the algorithms supported by each machine learning package in R. Gives you a grounded feeling of what’s out there and what people are using for analysis day-to-day.
Top 10 Algorithms in Data Mining: Published article and now a book (Affiliate Link) on the most popular algorithms for data mining. Another grounded and less overwheling take on methods that you could go off and learn deeply.
I hope you have found this tour useful. Leave a comment if you know of a better way to think about organizing algorithms or if you know of any other great lists of machine learning algorithms.
本文由36大数据翻译组darcher005翻译,并经36大数据编辑,文章地址:http://www.36dsj.com/archives/8911
约吗?
各位技术控们,大家要是看到什么好的写CV和Machine Learning的文章,欢迎推荐给小编哦~
分割线在此,还不快快分享到朋友圈!
如果你不是搞技术的,就把这篇文章转给自己朋友圈那些技术控们吧~
当然,要是对我们的文章以及内容有任何意见和建议,也欢迎随时对小编开启吐槽模式,小编最喜欢不吐槽会死星人了~