Hash table and linked list implementation of the Map interface, with predictable iteration order.
This implementation differs from HashMap in that it maintains a doubly-linked list running through all of its entries.
This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map ( insertion-order ).
LinkedHashMap的特征
- HashMap的子类
- 有序迭代
LinkedHashMap实现与HashMap的不同之处在于,LinkedHashMap的链表是双向链表,维护着元素的加入顺序(默认)。此双向链表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
构造器
看下它的无参构造器,了解下对象属性有什么。
/**
* Constructs an empty insertion-ordered LinkedHashMap instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
//
/**
* accessOrder的作用,设置迭代顺序,默认为false
*/
/**
* The iteration ordering method for this linked hash map: true
* for access-order, false for insertion-order.
*
* @serial
*/
final boolean accessOrder;
由构造器可以看出,LinkedHashMap也是链表数组(和HashMap一样)。那它在什么地方把数组元素的HashMap的单向链表替换成双向链表的实现呢。
在put方法里(LinkedHashMap没有重写此方法)初始化table(第一次resize())时,发现调用了LinkedHashMap重写的newNode()方法,使得其数组元素为Node
LinkedHashMap.Entrystatic class Entry)。
// 这里的参数e是链表的next对象
Node newNode(int hash, K key, V value, Node e) {
LinkedHashMap.Entry p =
new LinkedHashMap.Entry(hash, key, value, e);
// 双向链表的维护
// 把新加的节点置于链表的末端
linkNodeLast(p);
return p;
}
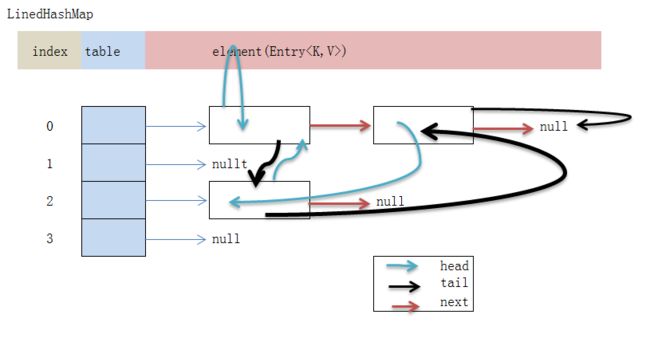
LinkedHashMap.Entry对象维护着父类的next属性,这是解决hash碰撞时的单向链表,另外LinkedHashMap.Entry的head和tail属性维护着node的顺序。所以它的结构类似以下:
迭代
默认的迭代顺序是Insert顺序:accessOrder=false,可想而知,顺序是基于这个双向链表的,那么迭代顺序的设置,实际上就是此双向链表的维护。
按照insert的顺序迭代很好理解,先加入的在前面,迭代(正序)时先输出;那么按照access顺序呢?
看一下HashMap的putVal方法里面的两个语句:
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 看这里
afterNodeAccess(e);
return oldValue;
}
// ...
// 以及在putVal方法最后的
afterNodeInsertion(evict);
看一下LinkedHashMap中对这两个方法的重写:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
void afterNodeAccess(Node e) { // move node to last
LinkedHashMap.Entry last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.after = null;
// b指向e的前驱,a指向e的后继,如果前驱和后继都不为null的话,直接把前驱的后继指向后继,即把e在链中的关系注销了。
if (b == null)
head = a;
else
b.after = a;
// 此处的a 应该不会是null的 是null的话就证明e是末尾元素了
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
// 更新双向链表的tail
tail = p;
++modCount;
}
}
关于AfterNodeInsertion方法的evict参数,在put方法中传入的是true:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
还有就是afterNodeInsertion内部调用的removeEldestEntry:
protected boolean removeEldestEntry(Map.Entry eldest) {
return false;
}
它是固定返回false的,也就是说在当前的LinkedHashMap的实现中,没有开启remove eldest的功能,所以这个afterNodeInsertion方法在目前来看其实是空的。
再看afterNodeAccess,它的业务逻辑很清晰,是把Node e移到链表的最后,这个e就是put进去的Node或者是get的Node。在这种情况下,每次put或get元素,都会引起底层双向链表的变化。
示例:
@Test
public void testLinkedHashMap() {
LinkedHashMap lhm = new LinkedHashMap<>(16, 0.75f, true);
lhm.put(1, "one");
lhm.put(3, "three");
lhm.put(2, "two");
// for (Integer key : lhm.keySet()) {
// System.out.println(lhm.get(key));
// }
System.out.println(lhm);
lhm.get(1);
System.out.println(lhm);
}
上面代码的输出是:
{1=one, 3=three, 2=two}
{3=three, 2=two, 1=one}
如果在迭代时,访问了元素,像上面注释掉的代码,会抛ConcurrentModificationException。
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
为什么modCount != expectedModCount呢,在开始迭代时,创建迭代对象把modCount值赋给了expectedModCount,但是后面访问元素触发了afterNodeAccess方法,导致modCount变化使得二者不一致。
//迭代开始时创建迭代对象
LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
}
那么想要去迭代怎么办呢?
至少有以下两个方法:
// 方法一
Set> entrySet = lhm.entrySet();
Iterator> iterator = entrySet.iterator();
while (iterator.hasNext()) {
Entry entry = iterator.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 方法二
entrySet.forEach(new Consumer>() {
@Override
public void accept(Entry entry) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
});
这两个方式的共同点都是直接拿到这个双向链表,取到Entry对象,直接操作Entry对象。看下迭代器iterator的代码就很清晰了:
// entrySet = new LinkedEntrySet()-> LinkedEntryIterator -> LinkedEntryIterator extends LinkedHashIterator
final class LinkedEntrySet extends AbstractSet> {
public final Iterator> iterator() {
return new LinkedEntryIterator();
}
// ...
// 省略
}
// 核心在这里,构成单向链表
abstract class LinkedHashIterator {
LinkedHashMap.Entry next;
LinkedHashMap.Entry current;
int expectedModCount;
LinkedHashIterator() {
// 拿到链表的头结点
next = head;
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry nextNode() {
LinkedHashMap.Entry e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
// ...
// 省略
}
实际上抛开accessOrder不看,这两个方式比for循环里面get(key)的效率要高,至少不用循环对keyhash寻址去找链表元素,然后再迭代链表元素。