Integrated learning
1.集成学习一-----基于同一样本集,特征集,不同算法的集成学习
1.1什么是基于算法的集成学习
Q:对于同一个问题,不同的算法可能给出不同的结果,在此种情况下,到底以哪种算法的结果为准呢?
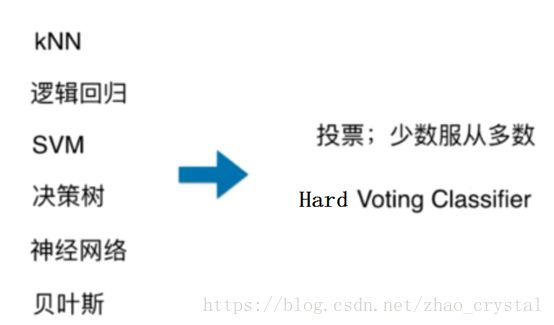
此时,可以把多个算法集中起来,让不同的算法对同一个问题都进行运算,得出结果,对于分类问题,少数服从多数;对于回归问题,取最终多个结果的平均值。----集成学习的思路
生活中的集成学习(我们经常用集成学习却不自知):
eg1: 买东西找人推荐,10个人中,7个人说值得买,3个人说垃圾,我们大概率的会去买(采取多数人的意见)
eg2: 病情确诊(专家会诊)
1.2 hard-Voting
1.2.1 根据集成学习的思路,自己编写程序
(1)调用sklearn 中make_moons数据(该数据集中总共包含两类数据),并将其分为训练数据集和测试数据集
(2)分别用logisticRegression 、SVC、DecisionTreeClassifier针对训练数据集进行训练,得到测试数据集的预测值,分别记为y_predict1,y_predict2, y_predict3(由于该数据集只有两类,故y_predict中只包含0,1)
(3)y_predict = (y_predict1+y_predict2+y_predict3) >=2, 即若y_predict1,y_predict2, y_predict3有两个为1,则y_predict为1(True);否则,y_predict为0(False)
(4)调用accuracy_score,根据y_test(测试数据集真值输出)分别看一下y_predict,y_predict1,y_predict2, y_predict3的准确率
1.2.2 用sklearn.ensemble.VotingClassifier进行集成学习的训练,达到同1,2,1同样的效果,
注意:此时参数voting=‘hard’(在分类问题中表示少数服从多数;在回归问题中,表示求平均(未看源码考证过,有待确定))
具体代码,详见Integrated-learning-hardvotting.ipynb
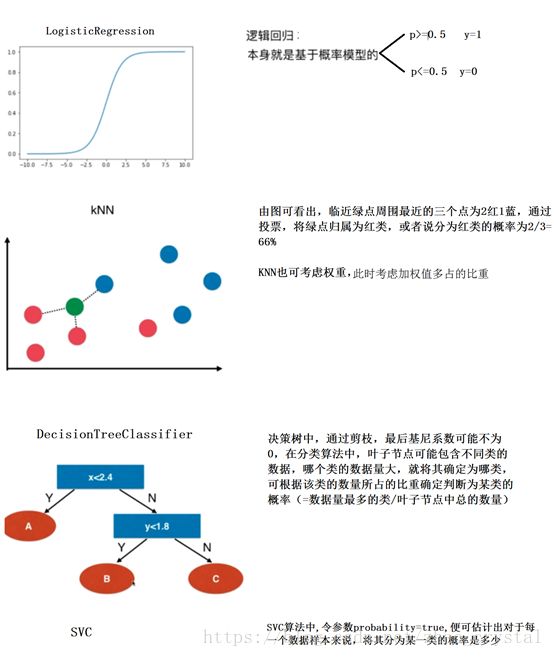
1.3 Soft-Voting Classifier
在一些情况下,少数服从多数是不合理的,更合理的投票,应该有权值。
eg3:唱歌比赛:专业评委+群众投票,此时,专业评委的权值就会更大一些
eg4:

根据Soft Voting的实现原理,Soft Voting要求集合的每一个模型都能估计概率(记为:predict_proba)
1.3.1 用sklearn中的函数,编程实现Soft Votting
(1)调用sklearn 中make_moons数据(该数据集中总共包含两类数据),并将其分为训练数据集和测试数据集
(2)调用sklearn.ensemble.VotingClassifier,
参数:
Voting=‘Soft’
estimators=('log_clf', LogisticRegression()),
('svm_clf', SVC(probability=True)),
('dt_clf', DecisionTreeClassifier(random_state=666))
注意:SVC中,probability=True;决策树的生成过程有一定的随机因素,在调试过程中,可传入一个随机种子,把随机因素控制掉。
大多时候,SoftVoting好于HardVoting
代码详见:Integrated-learning-SoftVotting.ipynb
2. 集成学习二--基于不同样本子集,不同特征子集的子模型
2.1
2.1.1 基于子模型的集成学习原理
Q:为什么引入基于子模型的集成学习
虽然有很多机器学习方法,但是从投票的角度看,仍然是不够多
故需要,创建更多的子模型,集成更多的子模型的意见。
注意:子模型不能一致,子模型之间要有差异性!
Q:子模型之间如何创建差异性?
每个子模型只看样本数据的一部分。
eg: 一共有500个样本数据,每个模型只看100个样本数据。由于每个模型训练的样本数据较少,准确率可能不能保证,但是此时每个子模型不需要太高的准确率
Q:为什么每个子模型不需要太高的准确率?
eg:如果每个子模型只有51%的准确率
当我们只有一个子模型时,整体准确率:51%
当我们有三个子模型时,整体准确率:![]()
当我们有500个子模型时,整体准确率: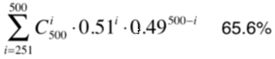
理论上,子模型越多,最后整体的准确率就会越高,这个只是在我们的子模型只有51%的准确率的情况下,如果我们子模型的准确率再高一点,当我们有很多个子模型时,整体的准确率肯定是很高的。
eg:如果每个子模型只有60%的准确率
当我们有500个子模型时,整体准确率: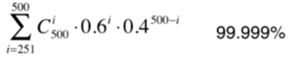
Q:如何创建子模型?
(1) 针对样本数据的随机采样bootstrap
Pasting: 不放回取样
比较具有随机性,比如总共有500个样本,每个子模型取100个,不放回取样,只能有5个子模型,相当于把样本分成了5份,怎样分将会影响最终的结果。
Bagging: 放回取样,更常用
没有很强烈的依赖随机,因为重复很多次,理论上把随机带来的问题给取消了。
OOB(Out-of-Bag)放回取样导致一部分样本很有可能没有取到(平均大约有37%的样本未取到,数学可推理证明),故我们可以不用将样本分为训练数据集和测试数据集,直接使用这部分没有取到的样本做测试、验证(sklearn算法中的参数oob_score)。
(2)针对特征进行随机采样Random Subspaces
随机的子空间。所有的特征构成了一个特征空间,每次在取样时,相当于在一个特征子空间中进行取样
(3)既针对样本,又针对特征进行随机采样 Random Patches
综合baging和random Subpaces, 既在行(样本)上随机取样,又在列(样本特征)上随机取样。

2.1.2 编程实现基于子模型的集成学习
(1)调用sklearn 中make_moons数据(该数据集中总共包含两类数据),
注意:此时不用将其分为训练数据集和测试数据集,我们一般使用放回取样(Bagging)
(2)针对样本数据的随机采样:使用sklearn.ensemble.BaggingClassifier,设置参数:
n_eatimaters = 500, max_samples = 100, bootstrap = True, oob_score = True, n_iobs等参数。
最后查看属性 .oob_score_ 得出测试数据集的预测效果
思考: 这里得出的score是准确率吗?对于有偏数据,想看一下f1_score 怎么实现?
(3)针对特征进行随机采样:仍然使用sklearn.ensemble.BaggingClassifier,设置参数:
n_eatimaters = 500, max_features = 1, bootstrap_features = True, oob_score = True, n_iobs等参数。
最后查看属性 .oob_score_ 得出测试数据集的预测效果
(4)既针对样本,又针对特征进行随机采样:仍然使用sklearn.ensemble.BaggingClassifier,设置参数:
n_eatimaters = 500, max_samples = 100, bootstrap = True, max_features = 1, bootstrap_features = True, oob_score = True, n_iobs等参数。
最后查看属性 .oob_score_ 得出测试数据集的预测效果
详见代码:Bagging(bootstrap)_bootstrap_features.ipynb
2.2基于决策树算法的子模型集成学习
2.2.1 随机森林 既针对样本,又针对特征进行随机采样?
Bagging
Base Estimator: Decision Tree
决策树在节点划分上,在随机的特征子集上寻找最优划分特征
2.2.2 Extra-Tree
Bagging
Base Estimator: Decision Tree
- 决策树在节点划分上,使用随机的特征和随机的阈值(适用于数据量很大的情况)
- 提供额外的随机性,抑制过拟合,但增大了bias(偏差).
- 更快的训练速度
2.2.3 编程详见:RandomForest_extraTree.ipynb
附:集成学习也可以解决回归问题。每一种分类算法对应的都有回归算法。
3集成学习三--- Boosting:基于同一样本集,特征集,同一算法的不同子模型
集成多个模型
每个模型都在尝试增强(Boosting)整体的效果
3.1 AdaBoosting

上一次未训练到的点的权重在下一次训练时就会大一些,(即每个子模型点和点之间的权重不一样)
对于分类问题,最终,综合所有的子模型进行投票,形成整体的决策结果。
对于回归问题,也是综合所有子模型的结果,取平均或是其他运算,最终得到整体的结果。
3.2 Gradient Boosting
Base estimator:DecisionTreeClassifier
- 训练一个模型m1,产生错误e1;
- 针对e1训练第二个模型m2,产生错误e2;
- 针对e2训练第三个模型m3,产生错误e3;
- 最终预测结果是:m1+m2+m3+……
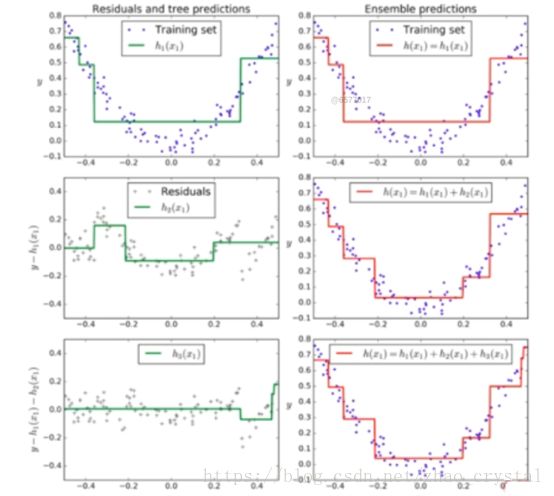
3.3 AdaBoosting 和Gradient Boosting的程序实现
详见程序:adaBoosting_GradiwntBoosting.ipynb
同理:Boosting也可以解决回归问题
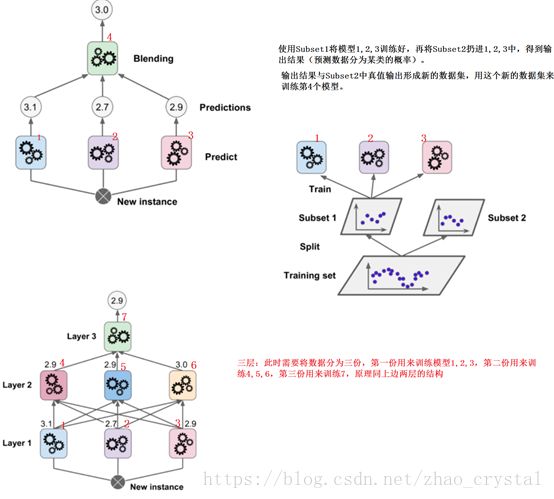
4 集成学习四--- Staking
- 上述的hardVoting,SoftVoting,bootstrap,Boosting都是多个模型对数据进行预测,分类是少数服从多数(SoftVoting是根据概率),回归是取平均值。-------Voting Classifier
- StakingClassifier中是取多个模型将数据预测为某一类的概率,和预测数据的真值作为第二层模型的输入再进行训练,得出最终结果。