C++ STL介绍(含struct类重载运算符方法)
最近在整理原来的一些资料,偶然想起原来搞OI时讲过一次STL和struct类重载运算符的内容,这里分享给大家
目录
algorithm
sort语句及struct类重载运算符
1、通过比较函数cmp实现
2、Struct类中重载运算符
二分查找
去除重复元素、离散化
queue
优先队列(堆)
map
set、迭代器
bitset
总结
题目推荐
标准模板库(Standard Template Library),惠普实验室开发的一系列软件的统称
在C++标准中,STL被组织为下面头文件:、<
调用STL是需要加特定的头文件的
algorithm
sort语句及struct类重载运算符
给定数列Ai,每个数有两个属性值Qi,Wi,按照Qi从小到大排序,若Qi相同,则按Wi从大到小排序
Sort(a+1,a+1+N)表示将a数组的第1位到第N位从小到大排序
如果需要按照其他标准排序呢?
两种实现方法:比较函数cmp实现、Struct类中重载运算符
1、通过比较函数cmp实现
由于STL中默认比较方式为两已有数据类型从小到大排序,即‘<’比较方式,即以下两种对A序列的从小到大排序方式等同。注意两部分sort语句的区别
方式1:

方式2:

我们可以发现:cmp函数为bool类型,那么如果返回true,相当于不交换位置,即当前两元素的位置顺序满足最终目的
前述问题的参考程序如下:

这里有个小细节:新建一个struct类数组时,有如下两种实现方式

2、Struct类中重载运算符
前面说过,默认比较方式按‘<’来执行,因此我们重载的运算符为‘<’,有如下两种方式
方式1:

方式2:
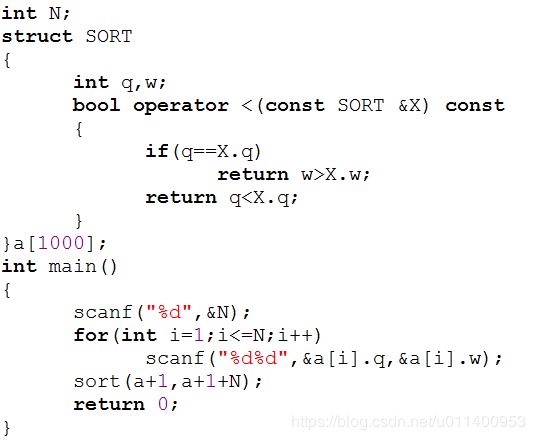
这两种不同的struct类实现方式的sort语句部分均未包含“,cmp”部分
二分查找
lower_bound语句及upper_bound语句
使用lower_bound可以知道在一个有序序列中大于等于某值的第一个位置在哪,默认有序序列的顺序为按值从小到大
如: lower_bound(a+1,a+1+N,Value)-a返回了大于等于Value这个值的第一个位置的指针,请看下方这个程序及其运行结果:

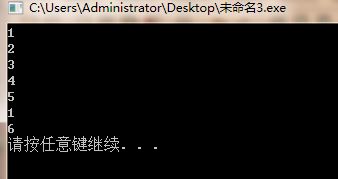
使用upper_bound可以知道在一个有序序列中大于某值的第一个位置在哪,默认有序序列的顺序为按值从小到大
去除重复元素、离散化
语句unique可以移除数组中连续的重复元素。所谓清除,只不过是将重复元素移到整个数组的后面,其返回值同样为一指针
去除重复元素+离散化代码如下:

queue
介绍普通队列的几个函数(不太推荐使用queue来执行队列操作,因为这样常数会很大)
empty()判断队列空,当队列空时,返回true。
size()访问队列中的元素个数。
push()会将一个元素置入queue中。
front()会返回queue内的下一个元素(也就是第一个被置入的元素)。
back()会返回queue中最后一个元素(也就是最后被插入的元素)。
pop()会从queue中移除一个元素。
注意:pop()虽然会移除下一个元素,但是并不返回它,front()和back()返回下一个元素但并不移除该元素
优先队列(堆)
优先队列可以被当做堆来使用
下面的语句相当于定义了一个struct类名字为POINT的一个优先队列:
![]()
该优先队列的维护方式将默认按照‘<’来维护,因此如果想要定义一个按照自己设定的规则来维护的优先队列,可以重载‘<’运算符。
按下图方式定义POINT,得到的是一个以v值来维护的小根堆:

如果要联系,可以去写一个堆优化Dijkstra
平时我们写题目的时候如果需要使用堆,一般使用priority_queue
map
下面介绍一个用红黑树维护的STL,需要头文件
map类型建立的是一个一一对应的数据映射,比如下面的这个语句建立了一个int类型到bool类型的一个映射:
![]()
你看到了什么东西?Hash!
没错,它可以用来当散列表使用
例子:

我们发现一个map类型
map
a类型的数据可以放在角标中,b类型的数据即为返回值
可以当数组用
其他map的操作:
. clear() 删除所有元素
. size() 返回map中元素的个数
. lower_bound() 返回键值大于等于给定元素的第一个位置
. upper_bound() 返回键值大于给定元素的第一个位置
提示一点,map的维护方式仍然通过‘<’维护
同时,一个string类型use:
use+=ch; 或 use=use+ch;
即可将ch这个字符加入use变量的后面
还有,如果想要实现多对一的映射关系,请自行学习multimap
set、迭代器
使用红黑树维护,定义一个空的set:
![]()
插入一个值A:S.insert(A);
删除一个值A:S.erase(A);
查找一个值A:S.find(A);,如果不存在该值,返回set尾指针的迭代器
注:
迭代器是一种对象,它能够用来遍历标准模板库容器中的部分或全部元素,每个迭代器对象代表容器中的确定的地址
例如:定义一个map类型的迭代器:
![]()
它只能用来接受类型为map<string,int>的迭代器
如果想调出其指向元素的值,只需在前面加上一个‘*’
比如:
![]()
将internal_storage这个set的头指针指向的元素值存入了use
set的其他操作:
. begin() 返回set的第一个元素的迭代器
. end() 返回set的最后一个元素的迭代器
. lower_bound() 返回指向大于(或等于)某值的第一个元素的迭代器
. clear() 清除所有元素
类似于map,set也有multiset这个库,有兴趣的可以自己学习
bitset
这是一个二进制容器
例如,定义一个容量为8的S变量,类型为bitset:
![]()
看下面这个程序:
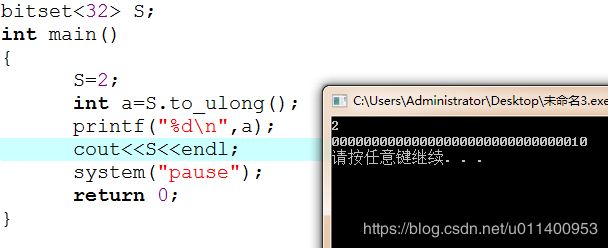
其中“S.to_ulong();”可以将S转化为unsigned long的类型
注意两个输出的不同
bitset的一些操作
.any():是否存在置为1的二进制位,返回值为bool类型
. count():二进制位为1的个数
. flip():把所有二进制位逐位取反
. flip(pos):把在pos处的二进制位取反
. set():把所有二进制位都置为1
. set(pos):把在pos处的二进制位置为1
. reset():把所有二进制位都置为0
. reset(pos):把在pos处的二进制位置为0
. test(pos):在pos处的二进制位是否为1
总结
其实STL还有许多,还推荐一个vector(向量容器,我习惯叫它动态数组),可以自己去学
这里只是介绍了一些常用的STL,现在就STL效率及实用性谈一点自己的感受:STL的使用,可以让自己的程序变得更简单,实现程序时也会更加方便,比如:Set可以用来当做平衡树、Map可以用来当做散列表、Algorithm中的一些功能可以实现二分查找(仅需一行实现)、离散化仅需3行
但是,STL也有个很大的缺点:时间常数太大。尽管set和map的每一步操作时间复杂度均为O(logn),因为是用红黑树维护,而且也没人想去在考场上写红黑树吧?
有一个例外,Bitset在位运算方面有着很神奇的优化功效<应该有些人有感受>,当然,仅限于位运算方面。在数据存储方面,当然普通数组更胜一筹
当然,在考场上,灵活的使用STL可以达到效率与收获百分比的最大化
总之,STL的学习是一个积累的过程,找到属于自己最好的编程方式才是最好的
题目推荐
BZOJ 1206 虚拟内存(HNOI 2005)(参见:https://blog.csdn.net/csyzcyj/article/details/17403613)
USACO 3.1.5 Contact(参见:https://blog.csdn.net/csyzcyj/article/details/9943645)
其实能用STL的地方太多了
不需要题目推荐
转载注明出处:https://blog.csdn.net/csyzcyj/